K 歌 & 语聊
智能硬件
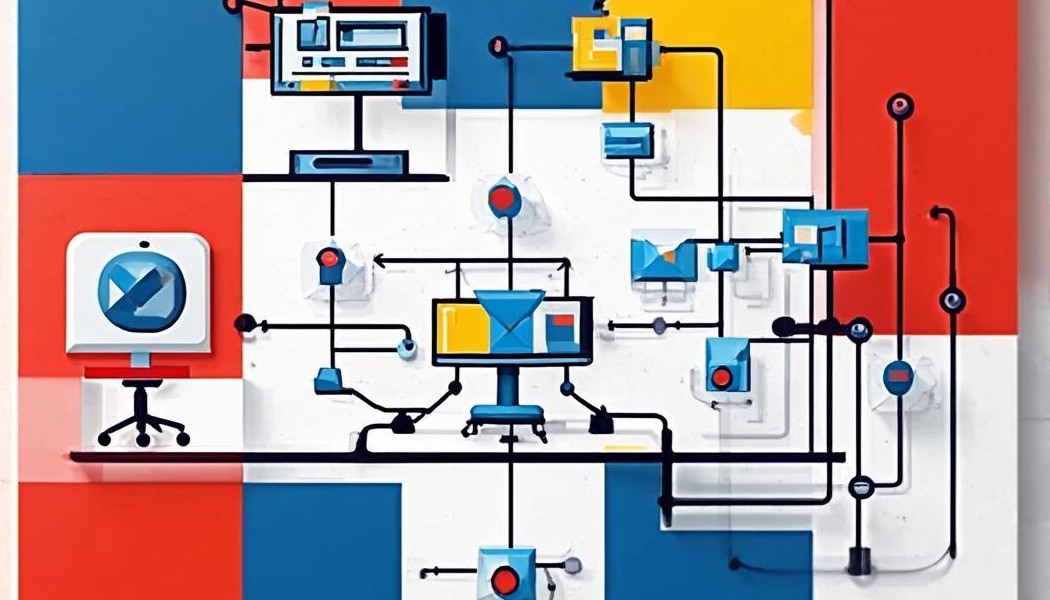
当夜晚书桌前的灯光显得格外安静,一道棘手的数学题或一个复杂的物理概念可能会让许多学生和家长感到困扰。在过去,这或许意味着长时间的苦思冥想或等待第二天的课堂解答。而如今,只需拿出手机,轻轻一拍,答案和详尽的解析便能在几秒钟内呈现眼前。这一神奇过程的背后,是一系列复杂而精密的人工智能技术在协同工作。它不仅仅是简单的图像比对,更是一场涉及计算机视觉、自然语言处理和大数据检索的“技术风暴”。理解其核心原理,不仅能让我们更好地利用这一工具,更能让我们一窥人工智能技术如何深刻地改变着我们的学习与生活方式。
一切始于用户按下快门的那一刻。当一张包含题目的照片被上传时,系统首先要做的不是“读懂”题目,而是“看清”这张图片。这一阶段被称为图像识别与预处理,是整个流程的地基,其处理效果直接决定了后续环节的准确性。现实世界中的拍照环境千差万别,照片可能因为光线不均、拍摄角度倾斜、书本弯曲或存在手写笔记的干扰而变得模糊不清。因此,算法必须首先对图像进行一系列“净化”和“矫正”操作。
这个预处理过程通常包括多个步骤。首先是图像降噪,利用高斯滤波等算法去除照片中的随机噪点,让图像变得更平滑。接着是灰度化和二值化,将彩色的图像转换为黑白图像,简化图像信息,强化文字与背景的对比度,为文字识别创造最佳条件。至关重要的一步是倾斜校正和透视变换,算法会自动检测图片中文本的排列方向和页面边缘,即便用户拍摄的照片是歪斜的,系统也能将其“扶正”,恢复到标准的阅读视角。最后,通过边缘检测和轮廓识别等技术,系统能准确地定位出题目文字、公式和图表所在的区域,将它们从复杂的背景中精确地“裁剪”出来,为下一步的文字识别做好充分准备。
t
当一张清晰、方正的题目图像准备就绪后,接力棒就交到了光学字符识别(Optical Character Recognition, OCR)技术的手中。OCR的任务是将图像中的文字、数字和符号转换成机器可以编辑和理解的文本格式。这可以说是整个流程中最为核心和神奇的一环。传统的OCR技术对于印刷体、字迹清晰的文本识别效果尚可,但面对手写体、艺术字体,尤其是结构复杂的数学公式和化学方程式时,往往力不从心。
现代拍照搜题应用所采用的,是基于深度学习的智能OCR技术。它通过构建复杂的神经网络模型,如卷积神经网络(CNN)来提取文字特征,再结合循环神经网络(RNN)或其变体(如LSTM)来理解字符之间的序列关系。这些模型经过海量数据的“投喂”和训练,不仅认识常见的汉字和英文字母,更能精准识别根号、分式、积分符号、化学元素以及各种上下标。例如,它能区分字母“O”和数字“0”,也能理解复杂的矩阵和多行公式的结构。这种强大的识别能力,是确保系统能够准确理解题意的基础。
为了更直观地展示传统OCR与现代AI-OCR的区别,我们可以参考下表:
| 特性 | 传统OCR | 现代AI-OCR |
|---|---|---|
| 识别对象 | 以标准印刷体为主 | 印刷体、常见手写体、公式、图表 |
| 准确率 | 在理想条件下较高,对干扰敏感 | 整体准确率极高,抗干扰能力强 |
| 复杂公式识别 | 能力很弱或不支持 | 支持,能解析复杂结构 |
| 技术核心 | 模板匹配、特征提取 | 深度学习、神经网络 |
仅仅将文字识别出来是远远不够的,系统还需要真正“读懂”这道题目的意思。这一重任由自然语言处理(Natural Language Processing, NLP)技术来承担。NLP的目标是让计算机能够像人类一样理解和运用语言。在搜题场景中,它的首要任务是对识别出的文本进行语法分析和语义理解。
首先,系统会对文本进行分词和词性标注,将一长串句子切分成一个个独立的词语,并判断每个词语的属性(如名词、动词、形容词等)。例如,对于“求解函数f(x)=x^2在x=2处的导数”,系统需要准确地切分出“求解”、“函数”、“f(x)”、“导数”等关键信息。随后,通过命名实体识别,系统可以识别出题目中的专有名词和核心概念。更进一步,语义理解模型(如BERT等预训练模型)会分析整个句子的深层含义,理解题目究竟是在问什么,考察的是哪个知识点。它需要弄清楚这是一个代数问题还是几何问题,是要求计算结果还是要求证明过程。这种深度的理解,是确保后续能在庞大的题库中找到最匹配答案的关键。
当系统完全理解了用户的题目后,最后一步就是在其庞大的后台题库中找到相同或相似的题目及其解答。这个题库可能包含数亿道题目,如果采用传统的文本匹配方式逐一比对,速度会非常慢,无法满足用户对“秒出答案”的期待。因此,这里采用的是更为先进的向量化检索技术。
这项技术的核心思想是,将每一道题目(无论是用户的提问还是题库中的存量题目)通过特定的算法(如Word2Vec, Sentence-BERT等)转换成一个多维的数学向量。这个向量可以被看作是题目在“语义空间”中的一个坐标。如此一来,寻找相似题目的问题,就转化为了一个数学问题:在海量的向量中,寻找与用户题目向量距离最近的几个向量。为了实现这一目标,工程师们会使用专门为高效相似性搜索设计的索引结构和算法,如倒排索引、局部敏感哈希(LSH)或基于图的索引(如HNSW),从而能够在毫秒级别内从亿级题库中锁定最匹配的几道题。最终,系统会根据匹配度的高低,将最相关的题目和解析呈现给用户。
然而,技术的发展并未止步于提供一个静态的答案。许多时候,即使用户看到了详细的解题步骤,可能依然对其中某个环节感到困惑。为了解决这个问题,“拍照搜题”正在从一个单向的搜索工具,向一个双向的、实时的互动学习平台演进。这种演进的核心在于,当自动化的解答无法满足用户的求知欲时,能够无缝地引入“人”的元素,提供即时的在线辅导。
要实现这种即时的、高质量的师生互动,离不开稳定、低延迟的实时音视频通信技术。这正是像声网这样的专业服务商发挥关键作用的地方。通过集成其提供的实时互动技术,搜题应用可以在用户需要时,一键连接真人老师进行视频或语音讲解。老师可以在共享的虚拟白板上演算过程,针对学生的疑问进行追问和引导,将原本冷冰冰的图文解析,升级为充满温度的个性化教学。这种结合了AI快速检索与人类专家深度辅导的模式,不仅解决了学生的燃眉之急,更构建了一个完整的学习闭环,让技术真正服务于教育的本质。
总而言之,一次看似简单的拍照搜题,背后是人工智能领域多项前沿技术的深度融合与精密协作。它始于计算机视觉对图像的精准捕捉与优化,依赖于OCR技术对文字和公式的精确识别,借助于自然语言处理技术对题意的深刻理解,最终通过高效的向量化检索技术在浩如烟海的题库中定位答案。而实时互动技术的加入,更是为其注入了人性的温度,让它从一个答题工具,向着一个真正的学习伴侣迈进。
展望未来,这一领域依然有广阔的探索空间。随着AI模型的不断进化,未来的搜题系统或许能提供更加个性化的学习路径建议,根据学生搜索的题目类型,智能推荐相关的知识点和练习题。增强现实(AR)技术的融入,也可能让解题过程变得更加直观和生动。但无论技术如何演变,其核心目标始终如一:即利用科技的力量打破知识传播的壁垒,让每一个渴望学习的人,都能随时随地获得高质量的教育支持。