 首页
首页根据开源社区Hugging Face 10月29日最新榜单数据,SoulX-Podcast模型在发布第二天登顶TTS(Text To Speech,从文本到语音)趋势榜。
一. SoulX-Podcast是什么
此前,Soul App AI团队(Soul AI Lab)联合西北工业大学ASLP@NPU团队和上海交通大学X-LANCE Lab正式开源SoulX-Podcast,该模型是一款专为多人、多轮对话场景打造的语音生成模型,支持多语种/方言与副语言风格,自然流畅、角色切换准确、韵律起伏丰富的多轮语音对话。
传统语音合成系统在多人、多轮对话场景常面临一些痛点问题,例如上下文衔接不自然;缺少副语言(如笑/叹气)、方言等的可控生成能力,缺少“活人感”;情绪状态无法随对话内容流畅改变,影响沉浸体验等。SoulX-Podcast致力于解决这些核心问题,其在播客场景、通用语音合成或克隆场景下出色表现,以及生动、真实的语音体验也让该模型在开源社区发布后迅速获得关注。
技术亮点:
- 支持多方言(川、粤、豫等)与副语言(笑声、叹息等)的精准控制;
- 实现超60分钟长对话的稳定生成与角色一致性;
- 突破“跨方言音色克隆”,实现普通话音色与方言表达的灵活结合。
二. SoulX-Podcast的实现
方言对话式 AI 需兼顾 “方言准确性” 与 “对话自然性”,需从数据处理、模型设计、训练策略、推理优化四环节系统构建:
(一)方言专属数据处理:构建高质量标注 corpus
1. 方言数据稀缺且标注难度高,需通过多策略采集与精细化处理,形成可用训练数据,核心步骤包括:
- 多渠道数据采集
- 公开数据挖掘:收集方言广播、方言节目、公开方言语料库(如文中用于粤语的 Wenetspeech-Yue、用于四川话的 Wenetspeech-Chuan);
- 模型辅助筛选:训练方言识别模型,从通用 “野生对话数据” 中筛选出方言 utterances(如文中从多语种数据中提取河南话、四川话片段);
- 商业工具补全:对难以转录的方言,采用方言专属 ASR 工具(如文中用 Seed-ASR API、TeleSpeech-ASR)生成精准文本,最终构建含四川话(2000 小时)、粤语(1000 小时)、河南话(500 小时)等多方言的 corpus。
2. 数据质量与一致性优化
- 噪声处理:用 UVR-MDX 工具分离方言对话中的背景音、噪声,保证语音纯净度;
- speaker 一致性修正:通过 WavLM-large 提取 speaker 嵌入特征,聚类过滤 “同 speaker 误标为多身份” 的片段(如剔除嵌入特征偏离聚类中心的异常 utterances);
- 方言标注细化:为数据添加方言标签(如<Sichuan>“<Cantonese>),同时标注对话中的语用信息(如方言特有的语气词、俚语),为模型学习方言特性提供依据。
(二)模型架构设计:适配方言对话的双阶段生成框架
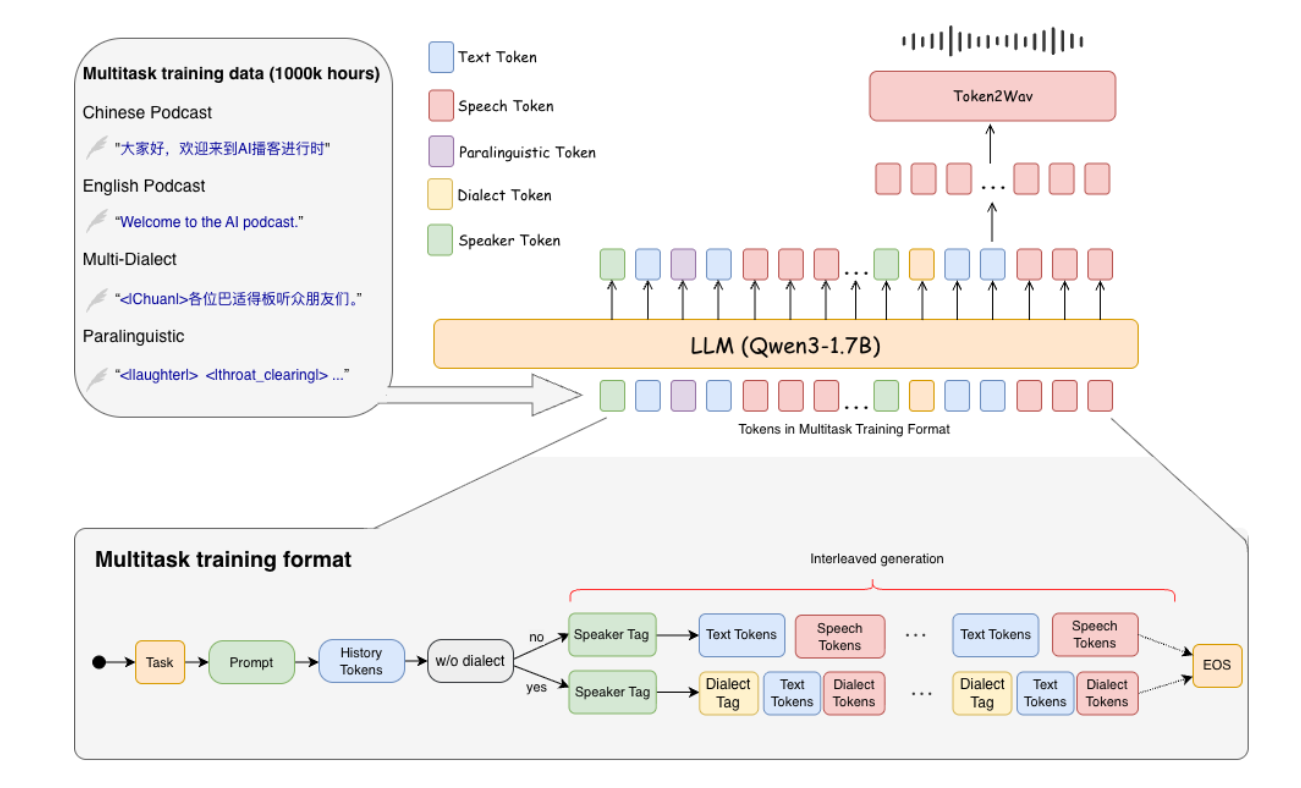
采用 “LLM + 语音生成” 双阶段架构,同时优化 token 组织方式以支持方言与对话逻辑,核心设计包括:
1. 基础架构:语义 – 声学两阶段生成
- 第一阶段(语义生成):以 Qwen3-1.7B 为基础 LLM,扩展文本码本,纳入 “方言 token”(如方言标签)、“对话 token”(如 speaker 标识<SPEAKER1>)、“副语言 token”(如方言对话中的笑声<|laughter|>、咳嗽<|coughing|>),让模型同时理解方言语义与对话场景;
- 第二阶段(声学合成):通过流匹配(Flow Matching)将语义 token 转换为声学特征,再经声码器合成方言语音,保证方言发音的准确性(如四川话的 “巴适”、粤语的 “唔该” 发音还原)。
2. token 组织:文本 – 语音交错序列
按 “时间顺序” 构建对话序列,格式为:<SPEAKER1><方言标签><文本 token><语音 token><SPEAKER2><方言标签><文本 token><语音 token>…,确保多 speaker 方言对话的流畅衔接,避免 “方言切换断裂”“ speaker 身份混淆”。
(三)训练策略:分阶段优化方言能力
针对方言数据少、对话场景复杂的问题,采用 “课程学习 + 专项微调” 策略,逐步提升模型性能:
1. 基础能力构建:先用 100 万小时通用独白数据(含普通话、英语)预训练 LLM,掌握基础文本 – 语音映射能力;
2. 对话能力提升:加入多 speaker 普通话 / 英语对话数据,训练模型理解对话逻辑(如 speaker 交替、上下文韵律适配);
3. 方言专项微调:用方言数据(含独白 + 对话)进一步微调,重点优化方言发音、语调特性(如粤语的九声六调、河南话的声调转折),同时通过 “上下文正则化” 机制,丢弃部分历史语音 token、保留文本语义,提升长对话(如 90 分钟方言 podcast)的连贯性。
(四)推理优化:跨方言语音克隆与方言引导
解决 “方言 prompt 稀缺” 问题,实现 “单方言 prompt 生成多方言对话”,核心方法为:
- 跨方言语音克隆(Dialect-Guided Prompting, DGP):当用普通话 prompt 生成目标方言时,在输入文本前添加 “方言典型句子”(如生成四川话时 prepend “各位巴适得板的听众朋友们”),通过方言特征强引导,让模型生成符合目标方言特性的语音;
- 动态 token 生成:推理时按训练阶段的 “文本 – 语音交错序列” autoregressive 生成,确保每轮对话的 speaker 身份、方言类型、副语言特征(如方言对话中的自然叹息)一致。
如果你是新手小白,想尝试门槛较低的方言AI,那可以参考下方代码:
import os
import json
import torch
import argparse
import s3tokenizer
import soundfile as sf
from soulxpodcast.config import SamplingParams
from soulxpodcast.utils.parser import podcast_format_parser
from soulxpodcast.utils.infer_utils import initiate_model, process_single_input
def run_inference(
inputs: dict,
model_path: str,
output_path: str,
llm_engine: str = "hf",
fp16_flow: bool = False,
seed: int = 1988,
):
model, dataset = initiate_model(seed, model_path, llm_engine, fp16_flow)
data = process_single_input(
dataset,
inputs['text'],
inputs['prompt_wav'],
inputs['prompt_text'],
inputs['use_dialect_prompt'],
inputs['dialect_prompt_text'],
)
print("[INFO] Start inference...")
results_dict = model.forward_longform(**data)
target_audio = None
for wav in results_dict["generated_wavs"]:
if target_audio is None:
target_audio = wav
else:
target_audio = torch.cat([target_audio, wav], dim=1)
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sf.write(output_path, target_audio.cpu().squeeze(0).numpy(), 24000)
print(f"[INFO] Saved synthesized audio to: {output_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = argparse.ArgumentParser()
parser.add_argument("--text", required=True, help="The text used for generating real audio")
parser.add_argument("--prompt_text", required=True, help="The text used for prompt")
parser.add_argument("--dialect_prompt", default="", help="The prompt dialect text used for prompt")
parser.add_argument("--prompt_audio", required=True, help="Path to the input JSON file")
parser.add_argument("--model_path", required=True, help="Path to the model file")
parser.add_argument("--output_path", default="outputs/result.wav", help="Path to the output audio file")
parser.add_argument("--llm_engine", default="hf", choices=["hf", "vllm"], help="Inference engine to use")
parser.add_argument("--fp16_flow", action="store_true", help="Enable FP16 flow")
parser.add_argument("--seed", type=int, default=1988, help="Random seed")
args = parser.parse_args()
data = {
"speakers":{
"S1":{
"prompt_audio": args.prompt_audio,
"prompt_text": args.prompt_text,
"dialect_prompt": args.dialect_prompt,
}
},
"text": [
["S1", args.text]
]
}
inputs = podcast_format_parser(data)
run_inference(
inputs=inputs,
model_path=args.model_path,
output_path=args.output_path,
llm_engine=args.llm_engine,
fp16_flow=args.fp16_flow,
seed=args.seed,
)如果你是进阶高手,想尝试多人方言播客、方言和普通话自由转换,可以参考以下代码:
import os
import json
import torch
import argparse
import s3tokenizer
import soundfile as sf
from soulxpodcast.config import SamplingParams
from soulxpodcast.utils.parser import podcast_format_parser
from soulxpodcast.utils.infer_utils import initiate_model, process_single_input
def run_inference(
inputs: dict,
model_path: str,
output_path: str,
llm_engine: str = "hf",
fp16_flow: bool = False,
seed: int = 1988,
):
model, dataset = initiate_model(seed, model_path, llm_engine, fp16_flow)
data = process_single_input(
dataset,
inputs['text'],
inputs['prompt_wav'],
inputs['prompt_text'],
inputs['use_dialect_prompt'],
inputs['dialect_prompt_text'],
)
print("[INFO] Start inference...")
results_dict = model.forward_longform(**data)
target_audio = None
for wav in results_dict["generated_wavs"]:
if target_audio is None:
target_audio = wav
else:
target_audio = torch.cat([target_audio, wav], dim=1)
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sf.write(output_path, target_audio.cpu().squeeze(0).numpy(), 24000)
print(f"[INFO] Saved synthesized audio to: {output_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = argparse.ArgumentParser()
parser.add_argument("--json_path", required=True, help="Path to the input JSON file")
parser.add_argument("--model_path", required=True, help="Path to the model file")
parser.add_argument("--output_path", default="outputs/result.wav", help="Path to the output audio file")
parser.add_argument("--llm_engine", default="hf", choices=["hf", "vllm"], help="Inference engine to use")
parser.add_argument("--fp16_flow", action="store_true", help="Enable FP16 flow")
parser.add_argument("--seed", type=int, default=1988, help="Random seed")
args = parser.parse_args()
with open(args.json_path, "r") as f:
data = json.load(f)
inputs = podcast_format_parser(data)
run_inference(
inputs=inputs,
model_path=args.model_path,
output_path=args.output_path,
llm_engine=args.llm_engine,
fp16_flow=args.fp16_flow,
seed=args.seed,
)三,应用场景
一直以来,声音都是传递信息和情感的重要媒介,也最能在沟通中赋予“情绪温度”和“陪伴感”。通过声网实时音视频的技术,Soul用户积极通过语音实时互动,表达自我、分享交流,收获新关系,语音成为用户构建链接的“情感纽带”,“语音社交”也成为平台颇具代表性的标签之一。
本次SoulX-Podcast团队结合其自身的开源技术,创建了具有方言和副语言多样性的长篇博客制作方案,实现了多轮、多角色的长对话生成:
此次 SoulX-Podcast 的开源,是 Soul 在开源社区领域的一次全新尝试,也是一个新的起点。 Soul团队表示,未来将持续聚焦语音对话合成、全双工语音通话、拟人化表达、视觉交互等核心交互能力的提升,并加速技术在多样化应用场景与整体生态中的融合落地,为用户带来更加沉浸、智能且富有温度的交互体验,持续提升个体的幸福感与归属感。同时,团队将进一步深化开源生态建设,与全球开发者携手,共同拓展 AI 语音等前沿能力的边界,探索 “AI +社交” 的更多可能。

