 首页
首页本文为使用大型语言模型构建 AI 质量控制的分步指南
当我第一次听到用 AI 来评估 AI 的想法——也被称为“LLM 评审”(LLM-as-a-Judge)——我的第一反应是:
“好吧,我们是真的疯了。”
我们生活在一个连厕纸都打着“AI 驱动”营销的时代。我原以为这不过是混乱又快速发展的 AI 世界里另一个被炒作出来的趋势。
但当我真正深入了解 LLM 评审到底意味着什么时,我意识到我错了。让我解释一下。
有一张图,每一个数据科学家和机器学习工程师都应该牢记在心,它展示了模型复杂度、训练集规模与预期性能水平之间的完整光谱:
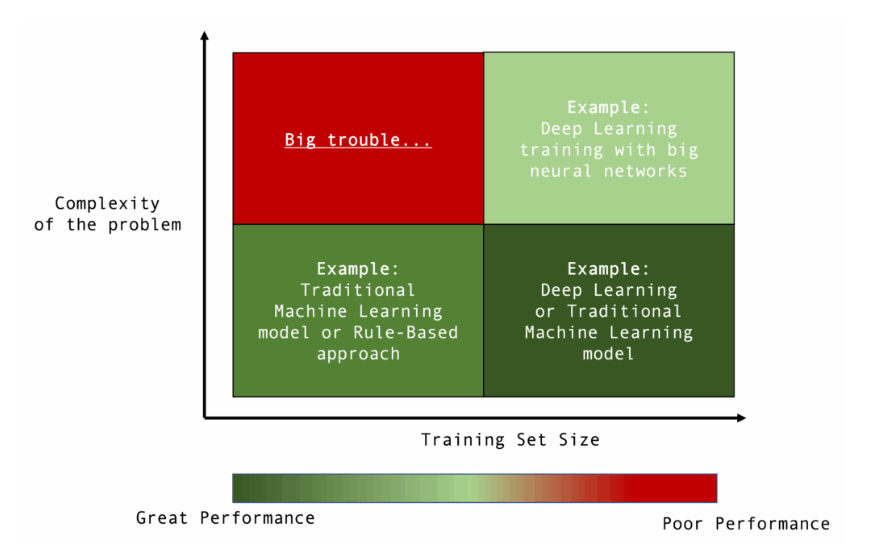
如果任务简单,拥有少量训练通常不是问题。在某些极端情况下,你甚至可以用简单的规则方法解决。即使任务变得更复杂,只要有大量且多样化的训练,通常也能达到高水平。
真正的问题在于任务复杂且你无法获得全面的训练集。到那时,就没有干净的配方了。你需要领域专家、人工数据收集和细致的评估流程,在最糟糕的情况下,你可能需要数月甚至数年的时间来建立可靠的标签。
那是在大型语言模型(LLM)出现之前。
LLM 评审范式
LLMs的承诺很简单:你可以通过一个API调用,获得接近“博士水平”的多个领域专业知识。我们可以(也应该)争论这些系统到底有多“智能”。越来越多的证据表明,LLM更像是一个极其强大的模式匹配器和信息检索器,而非真正智能的代理[你绝对应该关注这个]。
然而,有一件事很难否认。当任务复杂、难以形式化,且没有现成的数据集时,LLMs可以非常有用。在这种情况下,它们会随时为你提供高层次的推理和领域知识,远在你收集和标记足够数据来训练传统模型之前。
那么,让我们回到我们的“大麻烦”红方块。想象你有一个难题,而模型只有一个非常粗略的第一个版本。也许它是在一个很小的数据集上训练的,或者是你根本没有微调的现成模型(比如BERT或其他嵌入模型)。
在这种情况下,你可以用大型语言模型来评估这个V0模型的表现。LLM成为你早期原型的评估者(或评判者),能即时给你反馈,无需大量标签数据集或我们之前提到的巨大努力。
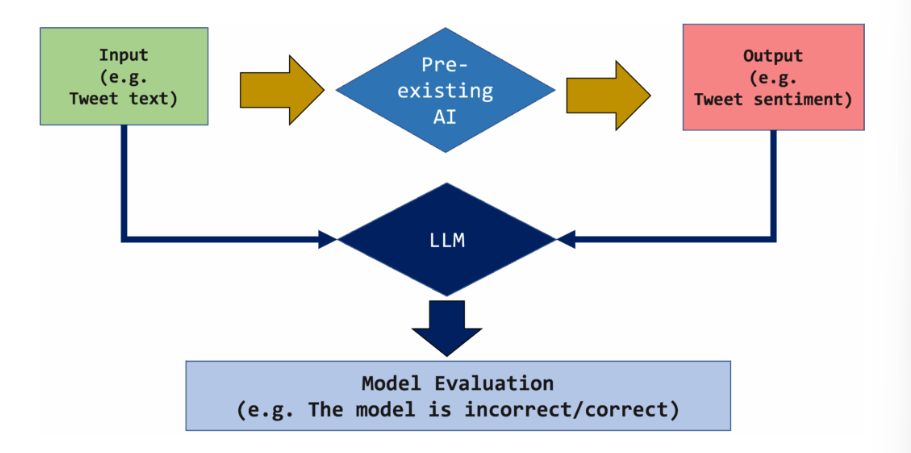
这将带来许多有益的下游应用:
- 评估 V0 的状态及其性能
- 构建训练集以改进现有模型
- 监控现有模型或微调版本的阶段(接着第2点)。
那我们就开始建造它吧!
大模型评审在真实业务中的落地
这里有一个假三段论:既然你不需要训练大型语言模型,而且它们在 ChatGPT / Anthropic / Gemini 界面上使用直观,那么构建LLM系统应该很容易。事实并非如此。
如果你的目标不是简单的即插即用功能,那么你需要积极努力,确保你的大型语言模型可靠、精准且尽可能无幻觉,设计它在失败时优雅地失败(不是“如果”,而是“当”)。
以下是我们将涵盖的主要主题,以构建一个面向生产环境的LLM即法官系统。
- 系统设计
我们将定义LLM的角色、其应如何表现,以及在评估时应采用的视角或“角色”。 - 少数样本示例
我们将给LLM具体示例,准确展示不同测试用例中评估应如何进行。 - 触发思维
链 我们将要求LLM生成笔记、中间推理和置信度水平,以触发更可靠的思维链形式。这鼓励模型真正“思考”。 - 批量评估
为了降低成本和延迟,我们将一次性发送多个输入,并在一批示例中重复使用同一提示。 - 输出格式化
我们将使用Pydantic强制执行结构化输出模式,并直接将该模式提供给LLM,使集成更清晰且安全。
让我们深入解析代码吧!
代码
让我们先从一些基础工作开始。代码里的繁琐部分是通过 OpenAI 完成的,并由 llm_judge 进行了封装。因此,你所需要导入的全部内容就是下面这一段代码:
import os
from openai import OpenAI
import pandas as pd
from typing import List, Tuple
# Import our LLM-as-a-Judge framework
from llm_judge import LLMJudge, FewShotExample, JudgmentResult
os.environ["OPENAI_API_KEY"] = "your_api_key°
client = OpenAI()2. 我们的使用场景
假设我们有一个情感分类模型,想要评估它。该模型根据客户评价做出预测:正面、负面或 中立。
以下是我们模型分类的样本数据:
# Sample outputs from our AI sentiment classifier
model_predictions = [
{
"input": "This product is absolutely amazing! Best purchase ever!",
"model_output": "Positive",
"ground_truth": "Positive" # We'll use this later
},
{
"input": "The item arrived damaged and customer service was unhelpful.",
"model_output": "Negative",
"ground_truth": "Negative"
},
{
"input": "It's okay, nothing special but does the job I guess.",
"model_output": "Positive", # This looks wrong!
"ground_truth": "Neutral"
},
{
"input": "Terrible quality. Broke after one use. Very disappointed.",
"model_output": "Neutral", # This also looks wrong!
"ground_truth": "Negative"
},
]
# Display as DataFrame
df = pd.DataFrame(model_predictions)
print("AI Model Predictions to Evaluate:")
print(df)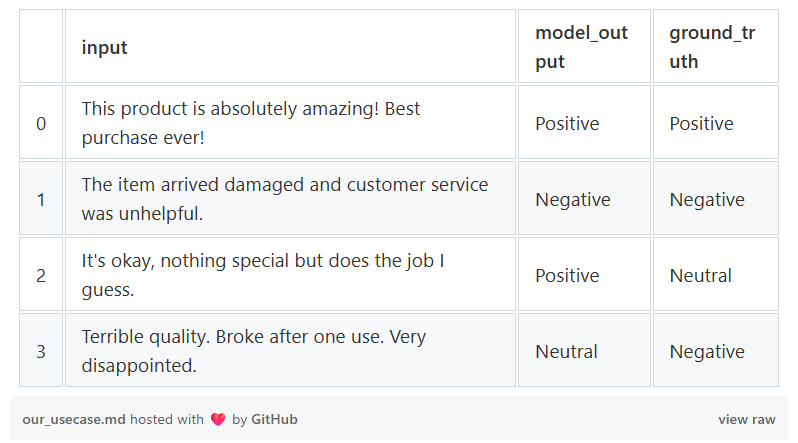
对于每个预测,我们都想知道:
——这个输出正确吗?
——我们对这个判断有多大信心?
——为什么是对的还是错的?
——我们怎么评价质量?
这正是LLM发挥作用的地方。注意ground_truth实际上并不在我们的现实数据集中;这也是我们最初使用LLM的原因。
你在这里看到它的唯一原因,是为了显示我们原始模型表现不佳的分类(指数2和指数3),在这种情况下,我们假装有一个较弱的模型,存在一些错误。在真实情况下,这种情况发生在你使用小模型或调整非微调深度学习模型时。
3. 角色定义
就像任何提示工程一样,我们需要明确定义:
1. 谁是评估者?LLM会像评委一样发挥作用,所以我们需要定义他们的专业和背景
2. 他们在评估什么?我们希望LLM评估的具体任务。
3. 他们应该采用哪些标准?LLM需要做什么来判断输出是好还是坏。
我们这样定义它:
# Define the judge's role
judge_role = """You are an expert evaluator of sentiment classification models.
You have 10 years of experience in natural language processing and understand the nuances
of sentiment analysis. Your job is to assess whether an AI model's sentiment predictions
are accurate and appropriate given the input text."""
# Define the evaluation task
evaluation_task = """For each AI model prediction, you must:
1. Read the original customer review
2. Examine the AI model's predicted sentiment
3. Determine if the prediction is correct
4. Consider nuances like sarcasm, mixed sentiment, and intensity
5. Provide a quality score (0-100), verdict, and detailed reasoning"""
# Define evaluation criteria
evaluation_criteria = """
A sentiment prediction is correct if:
- Positive: The review expresses satisfaction, praise, or positive experiences
- Negative: The review expresses dissatisfaction, complaints, or negative experiences
- Neutral: The review is factual, balanced, or lacks strong sentiment
Consider:
- Intensity of language (e.g., "amazing" vs "okay")
- Context and implications
- Mixed sentiments (judge the dominant sentiment)
"""
# Valid verdicts
verdicts = ["Correct", "Incorrect", "Partially Correct"]4. ReAct范式
ReAct模式(推理 + 行动)是我们框架内的。每项判决包括:
1. 得分(0-100):定量质量评估
2. 结论:二元或绝对判断
3. 信心:法官的确定性
4. 推理:思路链式解释
5. 注释:补充观察
这使得:
- 透明度:你可以看到LLM作为评委为何做出每一个决定
- 调试:识别错误中的模式
- 人在循环:将低信心判断转交给人类
- 质量控制:跟踪评委的表现随时间变化
5. 少量示例
现在,让我们再举一些例子,确保大型语言模型对如何评估现实世界案例有一些背景:
examples = [
FewShotExample(
input_text="This product exceeded all my expectations! Highly recommend!",
model_output="Positive",
expected_verdict="Correct",
expected_score=100.0,
reasoning="""The model correctly identified this as Positive sentiment.
The review contains strong positive indicators: 'exceeded expectations' and
'highly recommend'. The prediction is accurate and appropriate."""
),
FewShotExample(
input_text="Worst purchase of my life. Complete waste of money.",
model_output="Negative",
expected_verdict="Correct",
expected_score=100.0,
reasoning="""The model correctly identified this as Negative sentiment.
The review contains strong negative indicators: 'worst' and 'waste of money'.
The prediction is accurate."""
),
FewShotExample(
input_text="It's fine, does what it says on the box.",
model_output="Positive",
expected_verdict="Incorrect",
expected_score=20.0,
reasoning="""The model incorrectly classified this as Positive when it should be Neutral.
The review is lukewarm at best - 'fine' and 'does what it says' indicate no strong sentiment.
This is a clear misclassification that could skew model performance metrics."""
),
FewShotExample(
input_text="Great features but terrible battery life really ruins it.",
model_output="Neutral",
expected_verdict="Partially Correct",
expected_score=60.0,
reasoning="""The model classified this as Neutral, which is defensible but not ideal.
The review has mixed sentiment: positive ('great features') and negative ('terrible battery').
However, the word 'ruins' suggests the negative aspect dominates. A Negative classification
would be more accurate, but Neutral shows the model recognized the mixed nature."""
),
FewShotExample(
input_text="Meh. Nothing to write home about.",
model_output="Negative",
expected_verdict="Incorrect",
expected_score=30.0,
reasoning="""The model incorrectly classified this as Negative when it should be Neutral.
'Meh' and 'nothing to write home about' indicate indifference, not negativity.
While slightly negative-leaning, this is more neutral disappointment than active dissatisfaction."""
),
]我们将这些示例与提示一起展示,以便LLM根据我们提供的示例学习如何完成任务。
6. LLM 评估定义
整个过程被以下代码块包装:
# Create the LLM Judge
sentiment_judge = LLMJudge(
llm_client=client,
role=judge_role,
task_description=evaluation_task,
evaluation_criteria=evaluation_criteria,
valid_verdicts=verdicts,
few_shot_examples=examples,
model_name="gpt-4o-mini",
temperature=0.3 # Low temperature for consistency
)就这么简单。10行代码。我们用这个:
7. 开始执行
以下是运行整个LLM Judge API调用的方法:
# Judge each model prediction
print("=" * 100)
print("JUDGING AI MODEL OUTPUTS")
print("=" * 100)
for i, pred in enumerate(model_predictions, 1):
print(f"\n### Case {i} ###")
print(f"Input: {pred['input']}")
print(f"Model's Prediction: {pred['model_output']}")
print(f"Ground Truth (for reference): {pred['ground_truth']}")
print("^ Note: Ground truth shown here for education, but NOT passed to the judge!")
# Judge the model's output - NO ground_truth parameter!
# The judge evaluates purely based on input + model_output
judgment = sentiment_judge.judge_single(
input_text=pred['input'],
model_output=pred['model_output']
)
print(f"\n{'JUDGE VERDICT:':<20} {judgment.verdict}")
print(f"{'Quality Score:':<20} {judgment.score}/100")
print(f"{'Confidence:':<20} {judgment.confidence}%")
print(f"\nReasoning: {judgment.reasoning}")
if judgment.notes:
print(f"Notes: {judgment.notes}")
print("\n" + "=" * 100)
view rawLLMJudgeRun.py hosted with ❤ by GitHub
### Case 1 ###
Input: This product is absolutely amazing! Best purchase ever!
Model's Prediction: Positive
Ground Truth (for reference): Positive
^ Note: Ground truth shown here for education, but NOT passed to the judge!
JUDGE VERDICT: Correct
Quality Score: 100.0/100
Confidence: 100.0%
Reasoning: The model correctly identified this as Positive sentiment. The review contains strong positive indicators such as 'absolutely amazing' and 'best purchase ever', which clearly express satisfaction and enthusiasm. The prediction is accurate and aligns perfectly with the sentiment expressed in the review.
====================================================================================================
### Case 2 ###
Input: The item arrived damaged and customer service was unhelpful.
Model's Prediction: Negative
Ground Truth (for reference): Negative
^ Note: Ground truth shown here for education, but NOT passed to the judge!
JUDGE VERDICT: Correct
Quality Score: 100.0/100
Confidence: 95.0%
Reasoning: The AI model correctly identified the sentiment as Negative. The review clearly expresses dissatisfaction with two strong indicators: 'arrived damaged' and 'customer service was unhelpful'. Both phrases indicate a negative experience, confirming the model's prediction is accurate and appropriate.
====================================================================================================
### Case 3 ###
Input: It's okay, nothing special but does the job I guess.
Model's Prediction: Positive
Ground Truth (for reference): Neutral
^ Note: Ground truth shown here for education, but NOT passed to the judge!
JUDGE VERDICT: Incorrect
Quality Score: 25.0/100
Confidence: 90.0%
Reasoning: The model incorrectly classified this review as Positive when it should be Neutral. The phrase 'It's okay' suggests a lukewarm sentiment, and 'nothing special' reinforces a lack of strong positive feelings. The statement 'does the job I guess' implies a sense of resignation rather than enthusiasm. Overall, the review does not express satisfaction or praise, making the Positive classification inaccurate.
Notes: The model should improve its understanding of nuanced expressions of indifference or mild approval.
====================================================================================================
### Case 4 ###
Input: Terrible quality. Broke after one use. Very disappointed.
Model's Prediction: Neutral
Ground Truth (for reference): Negative
^ Note: Ground truth shown here for education, but NOT passed to the judge!
JUDGE VERDICT: Incorrect
Quality Score: 20.0/100
Confidence: 90.0%
Reasoning: The model incorrectly classified this review as Neutral when it should be Negative. The phrases 'terrible quality' and 'broke after one use' are strong indicators of dissatisfaction and negative sentiment. The expression 'very disappointed' further emphasizes the negative experience. Overall, the review conveys clear dissatisfaction, making the model's prediction a significant misclassification.
Notes: The model should improve its ability to detect strong negative sentiment in phrases that clearly express disappointment.因此我们可以立刻看到 LLM Judge 正确地判断了“模型”的表现。特别是识别最后两个模型输出是错误的,这也是我们的预期。
虽然这有助于表明一切正常,但在生产环境中,我们不能仅仅在控制台“打印”输出:我们需要存储并确保格式标准化。我们的做法如下:
batch_input = [
(pred['input'], pred['model_output'])
for pred in model_predictions
]
# Batch judge
judgments = sentiment_judge.judge_batch(batch_input)
# Create results DataFrame
results_df = pd.DataFrame([
{
'input': pred['input'][:50] + '...' if len(pred['input']) > 50 else pred['input'],
'model_output': pred['model_output'],
'ground_truth': pred['ground_truth'],
'verdict': j.verdict,
'score': j.score,
'confidence': j.confidence,
}
for pred, j in zip(model_predictions, judgments)
])这就是它的样子

8. 奖金
现在,关键来了。假设你有一个完全不同的任务需要评估。假设你想评估你的模型的聊天机器人响应。整个代码可以通过几行重构:
# Create a judge for chatbot responses
chatbot_role = """You are an expert evaluator of customer service chatbot responses.
You assess whether chatbot answers are helpful, accurate, and appropriately professional."""
chatbot_task = """Evaluate whether the chatbot's response:
1. Answers the customer's question
2. Is accurate and helpful
3. Maintains appropriate tone
4. Provides actionable information"""
chatbot_criteria = """
A good chatbot response should:
- Directly address the customer's question
- Be accurate (no hallucinations or false information)
- Be concise but complete
- Use professional, friendly tone
- Provide next steps when appropriate
"""
chatbot_examples = [
FewShotExample(
input_text="How do I reset my password?",
model_output="To reset your password, click 'Forgot Password' on the login page, enter your email, and follow the link sent to you.",
expected_verdict="Correct",
expected_score=95.0,
reasoning="The response directly answers the question with clear, actionable steps. It's concise, accurate, and helpful."
),
FewShotExample(
input_text="When will my order arrive?",
model_output="We offer free shipping on all orders!",
expected_verdict="Incorrect",
expected_score=10.0,
reasoning="The response completely ignores the question about delivery time. It provides irrelevant information about shipping cost instead of addressing the customer's concern."
),
]
chatbot_judge = LLMJudge(
llm_client=client,
role=chatbot_role,
task_description=chatbot_task,
evaluation_criteria=chatbot_criteria,
valid_verdicts=["Correct", "Incorrect", "Partially Correct"],
few_shot_examples=chatbot_examples,
model_name="gpt-4o-mini",
temperature=0.3
)
# Test chatbot responses
chatbot_test = [
{
"input": "What's your return policy?",
"output": "You can return items within 30 days for a full refund. Items must be unused and in original packaging."
},
{
"input": "Is this product waterproof?",
"output": "This is a great product! Many customers love it!"
},
]
print("Evaluating Chatbot Responses:")
print("=" * 100)
for i, test in enumerate(chatbot_test, 1):
print(f"\n### Chatbot Exchange {i} ###")
print(f"Customer: {test['input']}")
print(f"Chatbot: {test['output']}")
judgment = chatbot_judge.judge_single(
input_text=test['input'],
model_output=test['output']
)
print(f"\nVerdict: {judgment.verdict}")
print(f"Score: {judgment.score}/100")
print(f"Reasoning: {judgment.reasoning}")
print("=" * 100)Evaluating Chatbot Responses:
====================================================================================================
### Chatbot Exchange 1 ###
Customer: What's your return policy?
Chatbot: You can return items within 30 days for a full refund. Items must be unused and in original packaging.
Verdict: Correct
Score: 90.0/100
Reasoning: The response accurately answers the customer's question about the return policy by specifying the time frame for returns and the condition of the items. It is clear, concise, and provides actionable information that the customer can follow. The tone is professional and appropriate for customer service.
====================================================================================================
### Chatbot Exchange 2 ###
Customer: Is this product waterproof?
Chatbot: This is a great product! Many customers love it!
Verdict: Incorrect
Score: 15.0/100
Reasoning: The response does not answer the customer's question about whether the product is waterproof. Instead, it provides irrelevant information about customer satisfaction, which does not address the inquiry. The lack of a direct answer makes it unhelpful and inaccurate.由于两个不同的“评委”仅根据我们提供给LLM的提示词而更换,因此两种不同评估之间的修改非常简单。
结论
LLM作为“评委”是一个简单但具有强大实际力量的想法。当模型比较粗糙、任务复杂且没有标注数据集时,LLM可以帮助你评估输出、理解错误并加快迭代速度。
这是我们建造的:
- 评委的角色和形象都很明确
- 以下是指导其行为的少数示例
- 透明的思路链推理
- 批量评估以节省时间和成本
- 使用Pydantic的结构化输出用于生产用途
结果是一个灵活的评估引擎,可以在不同任务间仅做少量改动即可重复使用。它不能替代人工评估,但在你还没办法收集到足够数据之前,它是一套非常有力、可快速启动的解决方案。
原文作者:Piero Paialunga
原文链接:https://towardsdatascience.com/llm-as-a-judge-what-it-is-why-it-works-and-how-to-use-it-to-evaluate-ai-models/

