 首页
首页NLU模型置信度是什么
NLU模型置信度 是模型对每个意图预测的“可信程度”或“自信度”,通常是一个 0~1 之间的实数,表示模型认为该预测正确的概率大小。这种概念在分类问题中尤其常见,其中模型会为每个类别分配一个概率值,这个值表示模型认为输入数据属于该类别的可能性有多大。置信度是模型输出的一部分,通常通过softmax函数或其他概率函数得到。也就是说,一个良好校准的置信度意味着:当模型说“我有 0.8 的置信度”时,这类预测在现实中应有约 80% 是正确的。
NLU模型置信度的工作原理
1. 生成过程
- 用户输入一个语句(utterance);
- NLU 模型对输入进行意图分类(intent classification);
- 模型返回一个“N-best 列表”:多个可能的意图假设(intent hypotheses),并为每个假设分配一个置信度(confidence estimate)。
{
'utterance': 'U',
'top_intent': 'intent_1',
'intent_ranking': {
'intent_1': conf_1, # rank 1
'intent_2': conf_2, # rank 2
...
'intent_N': conf_N # rank N
}
}每个 conf 值反映模型对该意图预测正确的“信任度”。
2. 计算逻辑
- 不同 NLU(如 Watson、LUIS、Rasa)采用不同的计算机制,有的独立对每个意图求概率(多二分类),有的视为多类互斥分类。
- 最常见做法是通过模型输出层(如 softmax)将得分归一化为概率形式,使各置信度加和为 1。
3. 评估与校准
论文提出衡量置信度可靠性的关键指标:
- Reliability Diagram(可靠性图):可视化置信度与真实准确率之间的对应关系。完美校准应接近对角线。
横轴(x-axis):模型预测的平均置信度(confidence estimate);
纵轴(y-axis):在该置信度范围内的真实准确率(accuracy);
理想情况(perfect calibration):点应落在对角线(y = x)上;
偏离对角线 → 代表模型过度自信或低估自信。
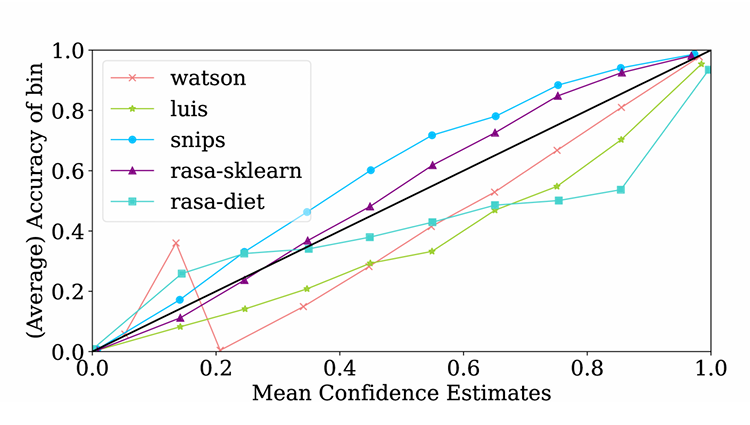
展现了五种不同的 NLU(自然语言理解)系统可靠性曲线
- Spearman相关系数:衡量置信度与预测准确性的单调相关性。越接近1表示越可信。
取每个模型在测试集中所有预测样本:
X:每个预测的置信度(0–1);
Y:对应的真实标签是否正确(正确为1,错误为0)。
将这两组数据的排名差值 dᵢ 代入公式:
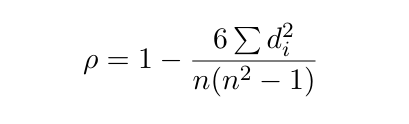
ρ 越接近 1,说明模型的置信度与实际准确率越一致(即“校准得好”)
应用场景
NLU置信度在对话系统(dialogue systems)中起到以下关键作用:
- 对话决策与澄清机制
- 当置信度高时,系统可直接执行意图;
- 当置信度低时,可选择澄清或确认用户意图(例如“您是想查询天气还是订机票?”)。
- 歧义检测(Ambiguity Detection)
- 如果两个意图置信度接近(如 0.48 vs 0.46),系统可识别出潜在的语义歧义并进行二次确认。
- 动态策略选择
- 置信度信息可用于选择不同的“grounding strategy”,例如当置信度较低时采取更谨慎的应答方式。
- NLU模型选择与评估
- 置信度校准可以帮助开发者选择更适合其应用场景的 NLU 服务。
(例如 Rasa-Sklearn 校准最好,而 Watson 性能最高,但校准较差
- 置信度校准可以帮助开发者选择更适合其应用场景的 NLU 服务。
置信度和准确率有什么关系
置信度和准确率是机器学习和深度学习中评估模型性能时常用的两个不同的概念,它们从不同的角度描述模型的预测能力:
置信度(Confidence):如之前所述,置信度是模型对其单次预测结果的确信程度,通常表现为概率值。例如,在分类任务中,置信度表示模型认为其预测正确的可能性有多大。一个预测的置信度可能非常高(例如,模型预测一个图像表示“猫”的概率为95%),但这并不保证预测是正确的。
准确率(Accuracy):准确率是评估模型整体性能的一个指标,它计算的是模型正确预测的比例。例如,在一个分类任务中,准确率是模型正确分类的样本数除以总样本数。准确率给出了模型预测正确的频率,但它不提供单次预测的置信水平。
置信度和准确率之间的主要关系在于,高置信度的预测希望能对应高准确率,但实际情况可能并非如此。模型可能对某些错误预测非常自信,或者对正确的预测不够自信。这种现象可能指示模型过拟合、数据不平衡或其他潜在问题。
理想情况下,模型的置信度应与其准确性相匹配。也就是说,当模型对预测非常确信时,这些预测也应该更有可能是正确的。然而,实际中经常会遇到模型对错误预测过于自信的情况,这就需要通过校准过程调整模型,使其预测置信度更真实地反映预测的正确可能性。
在实践中,研究人员可能会同时考虑置信度和准确率(以及其他性能指标,如精确度、召回率和F1得分),以全面评估模型的性能。特别是在关键应用中,理解模型预测的不确定性(通过置信度)和整体性能(通过准确率)都非常重要。

