 首页
首页这篇文章会带你用 Python 动手做一个简单的语音转文本模型。深度学习 + NLP 是现在非常热门的技能组合,而语音转文本正好是一个特别典型、特别实用的案例。我们会用一个真实的数据集,从原理到代码一步步带你搭起来。
一. 引言
“嘿 Google,今天天气怎么样?”过去十年,只要你用过智能手机,大概率说过类似的话。我现在几乎已经不再在搜索框里慢慢敲字了——随口问一句,Google 就把完整的天气情况展示给我。
不仅省时间,还特别方便。但你有没有想过:
- Google 是怎么听懂你说的话?
- 又是怎么把你说的语音变成屏幕上那串文字?
答案就是:语音转文本模型(Speech-to-Text)。Google 会结合深度学习模型和自然语言处理技术,先把语音信号转成文字,再理解你的问题、搜索结果,然后用文本和语音形式把答案反馈给你。同样的语音转文本技术,其实也被广泛应用在我们熟悉的语音助手里——比如 Amazon Alexa、Apple Siri 等等。不同公司内部的实现细节会有区别,但核心思想都是一样的。
之前我自己也专门研究过这类系统,就是想弄清楚:能不能只靠 Python + 深度学习,把一个语音转文本模型自己做出来?答案是:不仅可以,而且过程比想象中有趣得多。
所以在这篇文章里,我会先带你快速理解语音识别系统的基础原理(也可以理解为:一个对“信号处理”的入门介绍)。有了这些基础之后,我们再一步步用 Python 从零实现一个属于自己的 speech-to-text 小模型。
二. 语音识别技术简史:跨越数十年的进化之路
你对语音识别应该已经非常熟悉了——现在随处可见,从 Apple 的 Siri 到 Google Assistant 都在用。但这些语音助手其实都是最近十几年技术爆发后的产物。
不过你可能不知道:语音识别最早的研究可以追溯到 1950 年代!没错,这项技术已经走过了 半个多世纪。
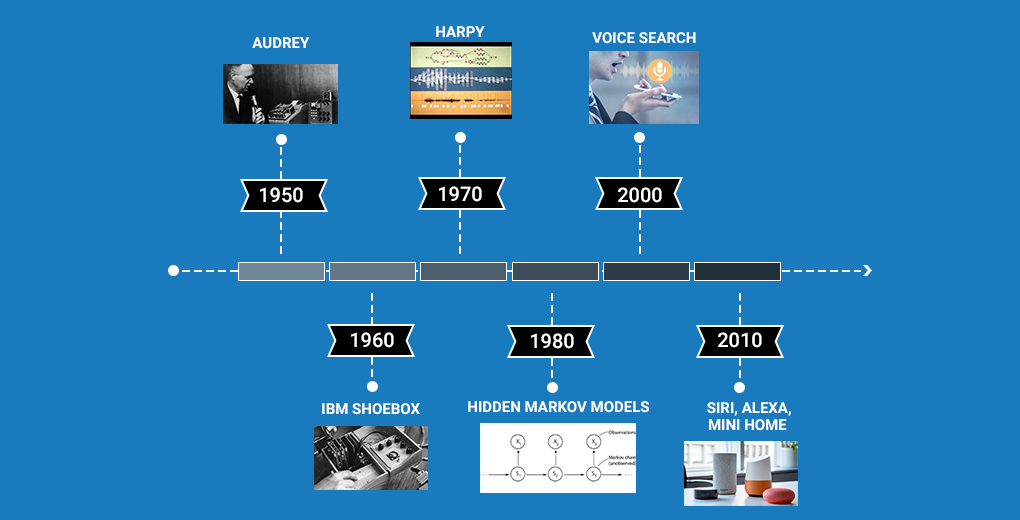
为了让你快速了解语音识别的发展脉络,我们特地整理了一份简洁直观的时间轴,带你看看这项技术是如何一步步演化到今天的智能语音助手。
- 最早的语音识别系统名叫 Audrey,由贝尔实验室的三位研究人员在 1952 年打造。不过它的能力非常有限——只能识别 0–9 这 10 个数字。
- 十年后,IBM 推出了自己的语音识别系统 IBM Shoebox。这一代的能力明显更强,已经可以识别 16 个单词(包括数字)。你甚至可以对它说:“Five plus three plus eight plus six plus four minus nine, total”。它会打印出结果:17。在当时,这是非常惊人的能力。
- 进入 1970 年代后,美国国防高级研究计划局 DARPA 对语音识别领域投入了重要资金。从 1971 到 1976 年,DARPA 连续五年资助了一个名为 Speech Understanding Research 的大型研究项目,最终产出了 Harpy 系统。Harpy 能识别 1011 个单词,这在当时代属于里程碑式的突破。
- 到了 1980 年代,语音识别研究迎来了另一次技术飞跃——隐马尔可夫模型(HMM)开始被应用于语音识别。HMM 是一种用于处理“序列数据”的统计模型,在许多实际应用(包括语音识别)中都有极强的表现。它奠定了之后几十年语音识别算法的基础。
- 进入 21 世纪后,语音识别开始真正进入大众视野。2001 年Google 发布了 Voice Search,用户第一次可以“对着机器说话”来完成查询。这是第一款真正意义上“被大量使用的语音应用”,让人与机器的交互变得前所未有地自然。
- 2011 年Apple 推出了 Siri。从此,用户只用说一句话,就能实时操作手机、查天气、发短信、设提醒……语音交互真正走进日常生活。如今,Amazon Alexa 和 Google Home 已成为全球范围最受欢迎的智能语音助手,语音指令正在逐渐成为一种新的输入方式。
如果我们也能用自己的机器学习技能做出这样的语音应用,那不是很酷吗?别急,这正是我们接下来在这个教程里要动手实现的!
三. 信号处理基础入门
在真正开始写语音转文本的代码之前,我非常建议你先把信号处理(Signal Processing)的基本概念过一遍。理解这些原理会让你:更容易看懂后面出现的 Python 代码,对 NLP 和深度学习的底层机制有更扎实的理解,在构建自己的模型时更加得心应手。
所以,我们先来认识几个处理音频信号时常见的概念。

3.1 什么是音频信号(Audio Signal)?
其实很好理解:任何会振动的物体都会产生声音。那我们为什么能听到别人的声音?答案就是:声音的传播依靠音频波(声波)。简单来看,声波的形成过程如下,
- 物体振动:一个物体开始振动时,它会带动周围的空气分子一起来回运动。
- 空气分子发生“往复震荡”:这些空气分子并不是离开原地,而是在自己的平衡位置附近不停前后振荡。
- 能量不断向外传播:震荡的空气分子把能量传递给下一批分子,就像多米诺骨牌一样,一层一层往外扩散。
- 形成声波,传到你的耳朵:当这些声波抵达我们的耳膜时,我们的大脑就会把它解释成“声音”。
也就是说,声波其实就是由空气分子振动产生的能量传输过程,而音频信号就是这种声波的数字化表示。
3.2 音频信号的常见参数
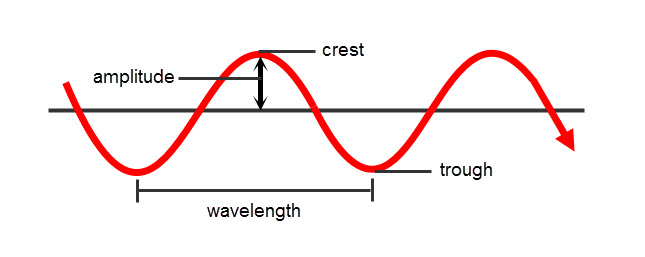
- Amplitude(振幅):空气分子相对静止位置的最大偏移量。振幅越大,声音越响。
- Crest / Trough(波峰 / 波谷):波峰是波形的最高点;波谷是波形的最低点。
- Wavelength(波长):两个相邻波峰(或波谷)之间的距离。
- Cycle(周期):音频信号的一个完整“向上→向下”波动,即一个周期。
- Frequency(频率):单位时间内信号完成的周期数。频率越高,信号变化越快。
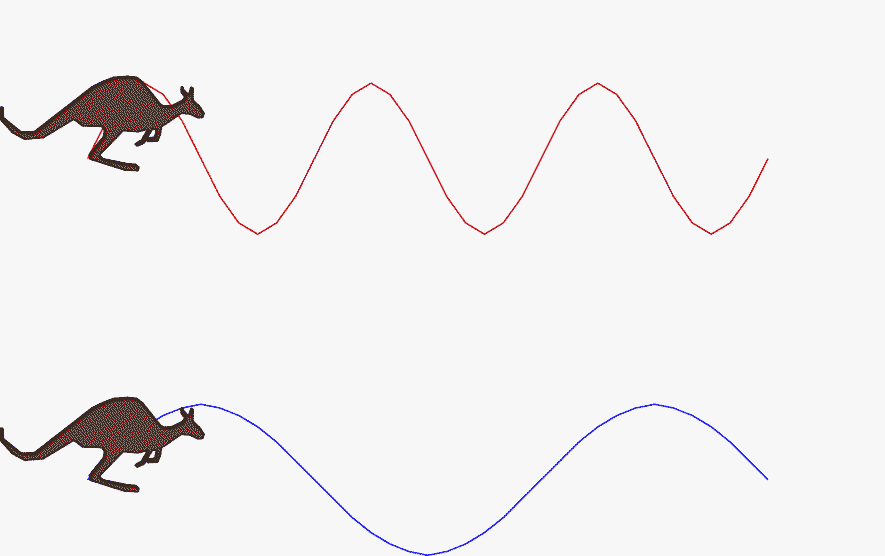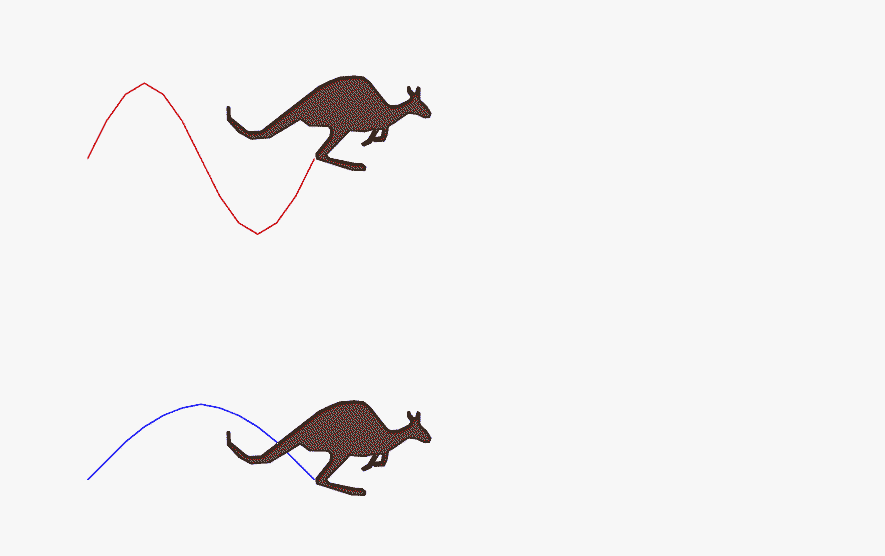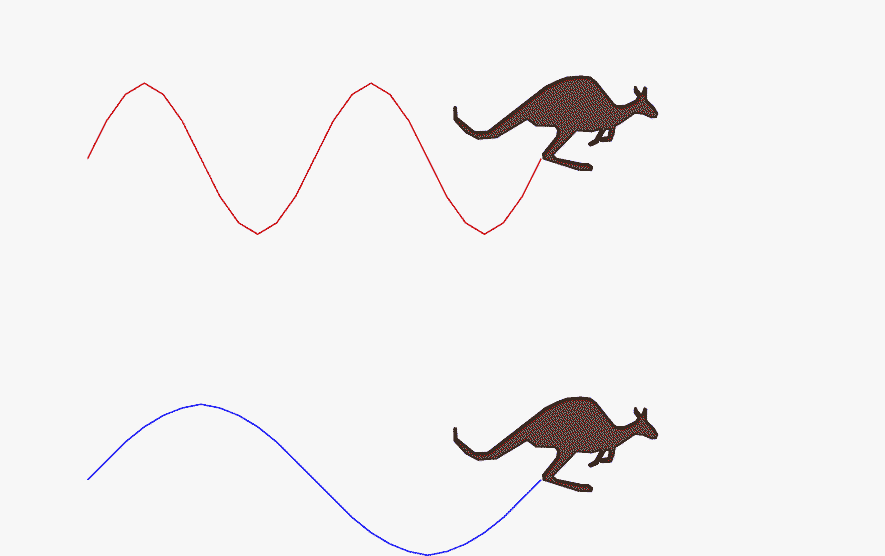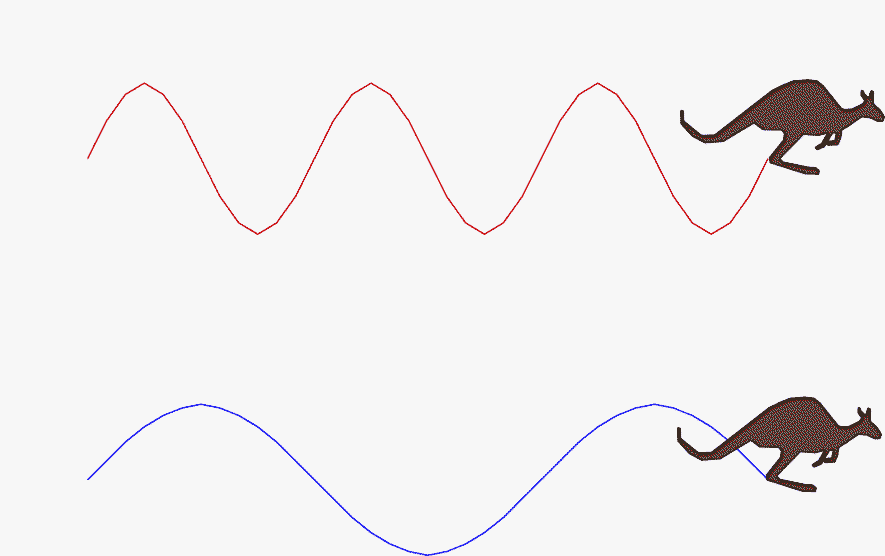
下面的 GIF 清晰展示了高频与低频信号的差异:
在下一部分,我会介绍我们日常生活中常见的几类信号类型。
3.3 常见的信号类型
我们日常接触的信号主要分为两类:数字信号(Digital) 和 模拟信号(Analog)。
1)Digital Signal(数字信号)
数字信号是对真实信号的离散化表示——在任意两个时间点之间,只存在有限数量的采样点。 举例: 按年份统计的击球手(batsman)平均得分,就是一个数字信号,因为每一年只有一个离散的样本点。
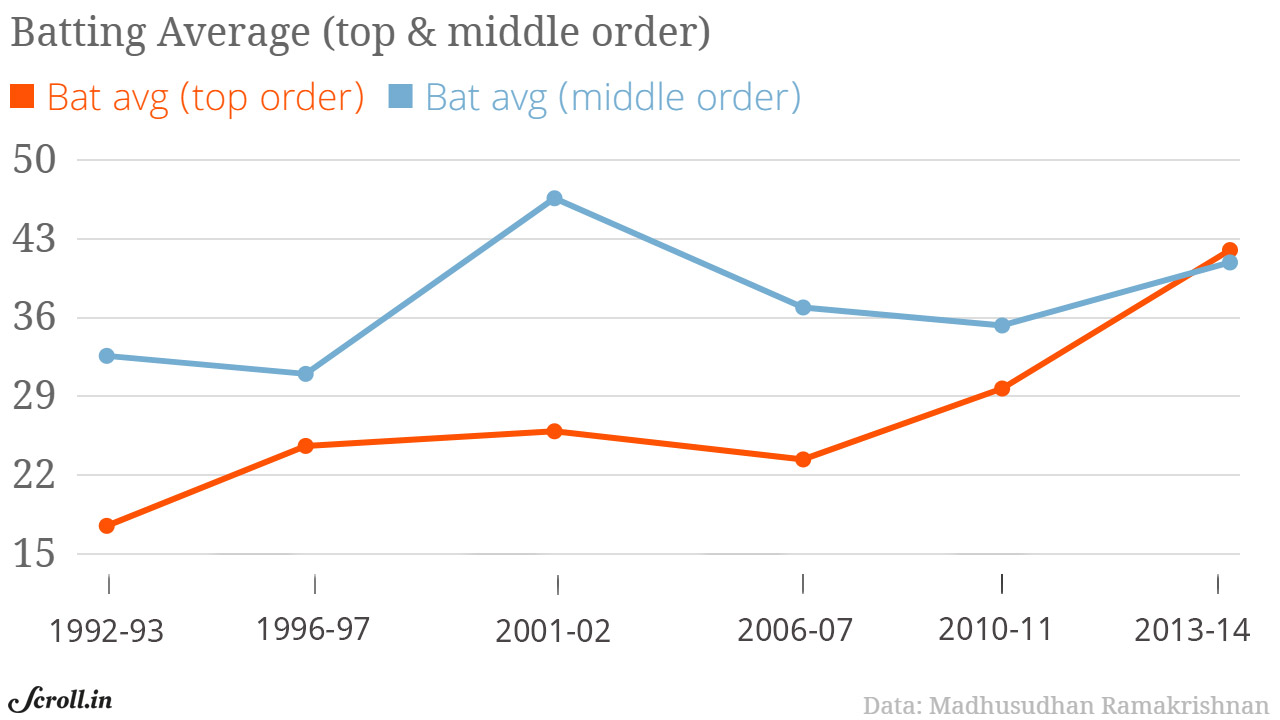
2)Analog Signal(模拟信号)
模拟信号是对真实信号的连续表示——在任意两个时间点之间,都包含无限多的取值。 举例: 音频信号就是典型的模拟信号,因为声音在时间维度上是连续变化的。
好奇“音频信号有无限多个采样点,那怎么存储”吗?别急,这就是下一节的内容。
3.4 什么是采样(Sampling),为什么需要采样?
音频信号本质上是一个随时间连续变化的振幅函数。时间分辨率甚至可以细到皮秒级,因此它属于模拟信号。
模拟信号的问题很明显:无限采样点极度占用存储、连续信号直接处理计算量极高。因此,我们需要一种方法把它转换成数字信号,这样才能高效存储与处理。
Sampling(采样)是从连续的模拟信号中,每秒选取固定数量的点,把它转成离散的数字信号。这样,音频信号在内存中就变得“可管理”了。
下面这张示意图很好地展示了一个连续的模拟音频信号,如何通过采样变成可以保存的数据点。
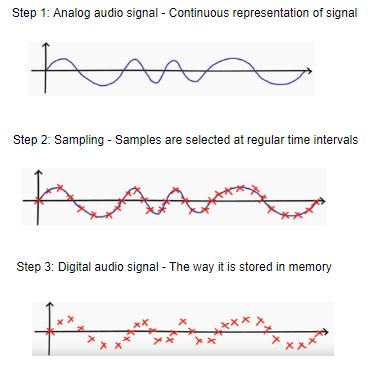
从上图可以看出,只要采样率足够高,即使把模拟信号采样成离散点,我们仍然可以重建出与原信号非常接近的波形。
四. 音频信号的特征提取方法
语音识别的第一步就是从音频信号中提取特征,后续模型会基于这些特征进行学习和预测。下面介绍几种常见的音频特征提取方式。
4.1 Time-domain(时域)
在时域中,音频信号以振幅(Amplitude)随时间变化的形式表示。简单理解:时域特征 = 不同时间点的振幅值。也就是把音频看成“振幅—时间”的序列,特征就是这些振幅本身。
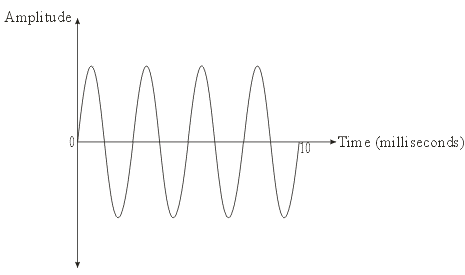
时域分析的局限在于:它只关注振幅随时间的变化,却忽略了信号变化速度(即频率成分)的信息;而这些信息正是频域分析所能补充的。因此,接下来我们继续讨论频域特征。
4.2 Frequency domain(频域)
在频域分析中,音频信号以“振幅随频率变化”的形式表示,本质上就是频率—振幅的关系图;对应的特征就是不同频率下的振幅值。
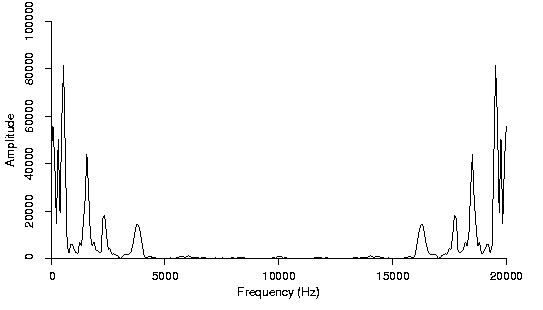
频域分析的局限在于:它只关注各频率下的能量分布,却无法体现信号随时间变化的顺序或时序信息,这部分内容只能由时域分析来补充。
时域分析忽略频率成分,而频域分析又不包含时间信息。我们可以通过 声谱图(spectrogram) 获得“随时间变化的频率”信息。
4.3 声谱图(spectrogram)
声谱图是什么?简单来说,它是一个以时间和频率为轴的二维图,每个点用颜色的强弱表示某个频率在某个时刻的振幅。声谱图展示了不同频率随时间变化的整体分布。
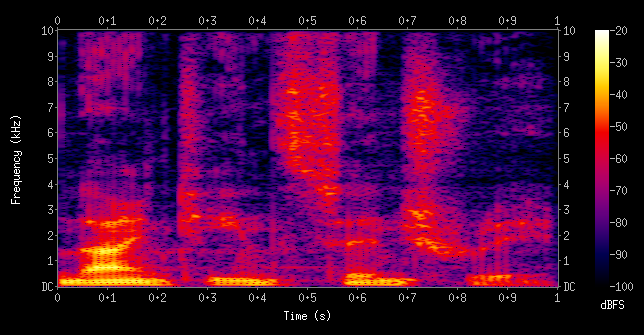
从音频中提取哪些特征,取决于具体要解决的任务场景。说到这儿,是时候真正开干了 —— 打开 Jupyter Notebook,上手实战吧。
五. 理解本项目的任务目标:构建一个语音转文本模型
在开始实现之前,我们先明确项目要解决的问题。
我们身边的屏幕越来越多,几乎所有日常设备都在被“重新发明”:加上 Wi-Fi、加上触控屏。语音交互被视为对抗“屏幕依赖”的一种更自然的解决方式。
TensorFlow 最近发布了 Speech Commands Dataset,包含约 65,000 条、每条 1 秒 的短语音,由不同人录制,共覆盖 30 个简单指令词。在这个项目中,我们将基于该数据集构建一个能识别这些简单口令的语音识别系统。
点击查看下载数据集。
六. 用 Python 实现语音转文本模型
终于到上手的时候了。现在我们来从零搭建自己的 Speech-to-Text 模型。
6.1 导入所需的库
首先需要在 notebook 中导入所有必要的库,其中 LibROSA 和 SciPy 是常用的音频信号处理库。下面是对应的 Python 代码:
import os
import librosa #for audio processing
import IPython.display as ipd
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import wavfile #for audio processing
import warnings
warnings.filterwarnings("ignore")时序域下的音频信号可视化接下来,我们先把音频信号在时序域中绘制出来,看看它随时间的变化情况:
train_audio_path = '../input/tensorflow-speech-recognition-challenge/train/audio/'
samples, sample_rate = librosa.load(train_audio_path+'yes/0a7c2a8d_nohash_0.wav', sr = 16000)
fig = plt.figure(figsize=(14, 8))
ax1 = fig.add_subplot(211)
ax1.set_title('Raw wave of ' + '../input/train/audio/yes/0a7c2a8d_nohash_0.wav')
ax1.set_xlabel('time')
ax1.set_ylabel('Amplitude')
ax1.plot(np.linspace(0, sample_rate/len(samples), sample_rate), samples)采样率(Sampling rate)
我们先查看当前音频的采样率:
ipd.Audio(samples, rate=sample_rate)
print(sample_rate)
重采样(Resampling)
可以看到原始音频的采样率是 16,000 Hz。
由于大部分语音有用信息主要集中在 8,000 Hz 附近,我们将音频重采样到 8,000 Hz:
samples = librosa.resample(samples, sample_rate, 8000)
ipd.Audio(samples, rate=8000)
在,我们来看一下每个语音指令各有多少条录音样本:
labels=os.listdir(train_audio_path)
#find count of each label and plot bar graph
no_of_recordings=[]
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
no_of_recordings.append(len(waves))
#plot
plt.figure(figsize=(30,5))
index = np.arange(len(labels))
plt.bar(index, no_of_recordings)
plt.xlabel('Commands', fontsize=12)
plt.ylabel('No of recordings', fontsize=12)
plt.xticks(index, labels, fontsize=15, rotation=60)
plt.title('No. of recordings for each command')
plt.show()
labels=["yes", "no", "up", "down", "left", "right", "on", "off", "stop", "go"]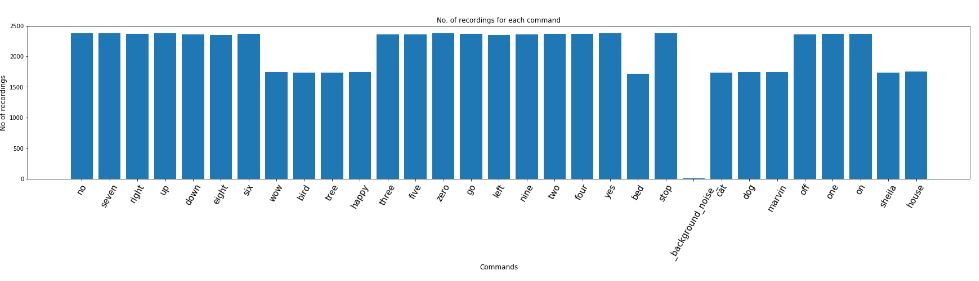
6.2 录音时长
接下来,我们查看录音时长的分布情况:
duration_of_recordings=[]
for label in labels:
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path + '/' + label + '/' + wav)
duration_of_recordings.append(float(len(samples)/sample_rate))
plt.hist(np.array(duration_of_recordings))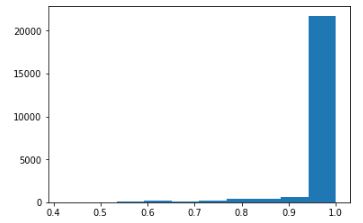
音频预处理
在前面的数据探索中,我们发现部分录音时长不足 1 秒,并且采样率偏高。接下来我们需要读取音频数据,并通过以下两步进行预处理:
- 重采样(Resampling)
- 移除时长不足 1 秒的录音
下面的代码片段将这两个预处理步骤组织成函数方便后续使用:
train_audio_path = '../input/tensorflow-speech-recognition-challenge/train/audio/'
all_wave = []
all_label = []
for label in labels:
print(label)
waves = [f for f in os.listdir(train_audio_path + '/'+ label) if f.endswith('.wav')]
for wav in waves:
samples, sample_rate = librosa.load(train_audio_path + '/' + label + '/' + wav, sr = 16000)
samples = librosa.resample(samples, sample_rate, 8000)
if(len(samples)== 8000) :
all_wave.append(samples)
all_label.append(label)将输出标签转换为整数编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y=le.fit_transform(all_label)
classes= list(le.classes_)现在把整数编码的标签转换为 one-hot 向量,因为这是一个多分类问题:
from keras.utils import np_utils
y=np_utils.to_categorical(y, num_classes=len(labels))
将二维数组 reshape 成三维数组,因为 Conv1D 的输入必须是 3D 张量:
all_wave = np.array(all_wave).reshape(-1,8000,1)
将数据划分为训练集和验证集
我们将使用 80% 的数据进行训练,剩下 20% 用于验证:
from sklearn.model_selection import train_test_split
x_tr, x_val, y_tr, y_val = train_test_split(np.array(all_wave),np.array(y),stratify=y,test_size = 0.2,random_state=777,shuffle=True)本任务的模型结构
我们将使用一维卷积(Conv1D)来搭建语音转文本模型。Conv1D 是一种只在单一维度上执行卷积运算的卷积神经网络。下面是本模型的具体结构:
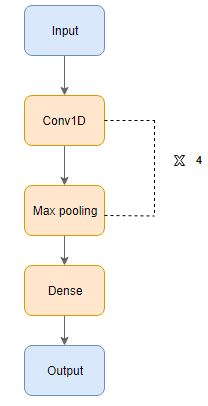
模型构建
接下来我们使用 Keras 的 Functional API 来实现这个模型。
from keras.layers import Dense, Dropout, Flatten, Conv1D, Input, MaxPooling1D
from keras.models import Model
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras import backend as K
K.clear_session()
inputs = Input(shape=(8000,1))
#First Conv1D layer
conv = Conv1D(8,13, padding='valid', activation='relu', strides=1)(inputs)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.3)(conv)
#Second Conv1D layer
conv = Conv1D(16, 11, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.3)(conv)
#Third Conv1D layer
conv = Conv1D(32, 9, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.3)(conv)
#Fourth Conv1D layer
conv = Conv1D(64, 7, padding='valid', activation='relu', strides=1)(conv)
conv = MaxPooling1D(3)(conv)
conv = Dropout(0.3)(conv)
#Flatten layer
conv = Flatten()(conv)
#Dense Layer 1
conv = Dense(256, activation='relu')(conv)
conv = Dropout(0.3)(conv)
#Dense Layer 2
conv = Dense(128, activation='relu')(conv)
conv = Dropout(0.3)(conv)
outputs = Dense(len(labels), activation='softmax')(conv)
model = Model(inputs, outputs)
model.summary()由于这是一个多分类任务,损失函数使用 categorical cross-entropy:
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
Early Stopping 和 Model Checkpoint 用作回调,用来在合适的时机终止训练,并在每个 epoch 保存当前表现最好的模型:
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10, min_delta=0.0001)
mc = ModelCheckpoint('best_model.hdf5', monitor='val_acc', verbose=1, save_best_only=True, mode='max')
我们使用 batch size = 32 来训练模型,并在留出集上评估模型表现:
history=model.fit(x_tr, y_tr ,epochs=100, callbacks=[es,mc], batch_size=32, validation_data=(x_val,y_val))
诊断图(Diagnostic plot)
我们再次借助可视化,观察模型在训练过程中的性能变化趋势:
from matplotlib import pyplot
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='test')
pyplot.legend() pyplot.show()加载表现最好的模型:
from keras.models import load_model
model=load_model('best_model.hdf5')
定义一个函数,用于对给定音频进行预测并输出对应的文本:
def predict(audio):
prob=model.predict(audio.reshape(1,8000,1))
index=np.argmax(prob[0])
return classes[index]开始预测:在验证集上生成模型的预测结果:
import random
index=random.randint(0,len(x_val)-1)
samples=x_val[index].ravel()
print("Audio:",classes[np.argmax(y_val[index])])
ipd.Audio(samples, rate=8000)
print("Text:",predict(samples))精彩的部分来了!下面这段脚本会提示用户录制语音指令,你可以录一段自己的指令并用这个模型来测试效果:
import sounddevice as sd
import soundfile as sf
samplerate = 16000
duration = 1 # seconds
filename = 'yes.wav'
print("start")
mydata = sd.rec(int(samplerate * duration), samplerate=samplerate,
channels=1, blocking=True)
print("end")
sd.wait()
sf.write(filename, mydata, samplerate)现在读取刚保存的语音指令,并将其转换成文本:
os.listdir('../input/voice-commands/prateek_voice_v2')
filepath='../input/voice-commands/prateek_voice_v2'
#reading the voice commands
samples, sample_rate = librosa.load(filepath + '/' + 'stop.wav', sr = 16000)
samples = librosa.resample(samples, sample_rate, 8000)
ipd.Audio(samples,rate=8000)
predict(samples)这是我用同事录制的语音指令测试后生成的视频示例:
查看Github获取代码。
结语
深度学习和 NLP 的力量总是令人惊叹。这只是它们众多应用中的一个小例子,我也非常鼓励你亲自尝试。
在这篇文章中,我们从基础概念讲起,并用 Python 从零实现了一个完整的语音识别模型。 希望今天的内容对你有所启发。
原文作者:Aravind Pai
原文链接:https://www.analyticsvidhya.com/blog/2019/07/learn-build-first-speech-to-text-model-python/

