 首页
首页在自然语言处理(NLP)领域,槽位填充(Slot Filling)是一个重要的任务,尤为常见于对话系统和问答系统中。槽位填充的主要目的是从用户输入的文本中提取相关信息,并将其映射到事先定义的槽位上。这些槽位通常用于构建用户意图并进一步处理。
槽位填充是什么
槽位填充的基本概念是将用户的输入映射到预定义的结构化形式。例如,如果用户询问天气:“明天在北京的天气如何?”,我们可能需要填充如下槽位:

在这个例子中,“时间”、“城市”、“主题”都是槽位,而相应的值则是从用户的输入中提取的。
工作原理
1. 算法和模型
进行槽位填充的模型通常包括意图识别和槽位提取两部分。意图识别用于确定用户的意图,而槽位填充则用于提取具体的信息。常用的模型有循环神经网络(RNN)、长短时记忆网络(LSTM)以及近年兴起的预训练语言模型,如BERT、GPT等。
2. 数据准备
在实现槽位填充前,首先需要准备数据集。常见的数据集格式为:
{"text": "明天在北京的天气如何?", "slots": {"时间": "明天", "城市": "北京", "主题": "天气"}}3. 代码示例
以下是使用Python和Transformers库实现简单槽位填充的示例代码。我们将使用BERT模型进行槽位提取。
4. 安装所需库
首先,确保安装了transformers和torch包:
pip install transformers torch
import torch
from transformers import BertTokenizer, BertForTokenClassification
from torch.nn import functional as F
# 加载BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForTokenClassification.from_pretrained("bert-base-uncased", num_labels=3)
# 定义输入文本
text = "明天在北京的天气如何?"
inputs = tokenizer(text, return_tensors="pt")
# 模型推理
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# Softmax计算标签概率
probs = F.softmax(logits, dim=-1)
predictions = torch.argmax(probs, dim=-1)
# 打印预测结果
print("输入文本: ", text)
print("预测槽位标签: ", predictions)5. 输出分析
上述代码首先加载了一个预训练的BERT模型,然后对输入文本进行分词和模型推理。模型输出的predictions包含预测的槽位标签,可以进一步将这些标签映射回具体的槽位。
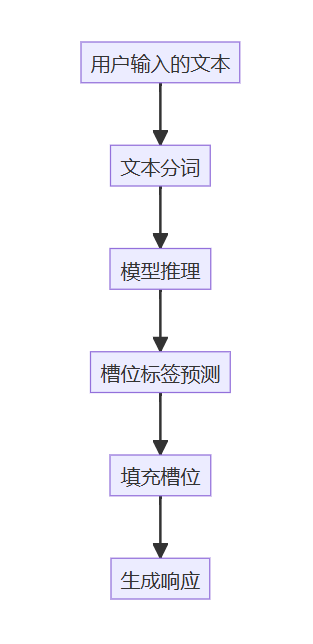
6. 流程分析
以下是一个简化的槽位填充流程图:
应用案例
信息提取:从用户的自然语言输入中识别出关键信息,例如时间、地点和主题等。
对话系统:在对话系统中,槽位填充可以通过实体识别来优化用户交互,使得系统能够更准确地理解用户意图并提供相关建议。

