K 歌 & 语聊
智能硬件
跟真人聊天是什么感觉?你说完一句话,对方几乎不会让你等着。你语气变了,对方也能感觉到。而AI语音对话恰恰相反:反应慢半拍,听不出情绪,说话永远一个调,偶尔还会撞话或冷场,体验始终差点意思。
为什么真人能做到的这些,AI却总是学不会?答案藏在几个看似平常、实则极难的技术挑战里。
低延迟:真人对话中的回应间隙超过半秒就会让人产生“没在听”的错觉。但AI从收声到回复,要经过“听清-理解-生成-合成”四个环节,每一步都得压缩到极致。
自然打断:真人聊天时,互相插话是常事,但大家知道什么时候该让、什么时候该接。AI如果被随口一句“嗯”就误判为打断而强行闭嘴,或者你明明想插话它却还在自说自话,都会让对话变得别扭。
上下文管理:你跟人聊一件事,不需要每句话都从头解释。而很多AI每轮对话都像初次见面,聊着聊着就串不上,用户得反复提示“我刚才说的那个”。这种“失忆”会迅速消耗耐心。
情感理解与表达:听懂“我没事”背后的低落,从语速变快判断对方着急,然后给出带着关心或加快节奏的回应,这已经超出了纯逻辑推理,需要AI具备对声音信号的细腻感知与输出能力。
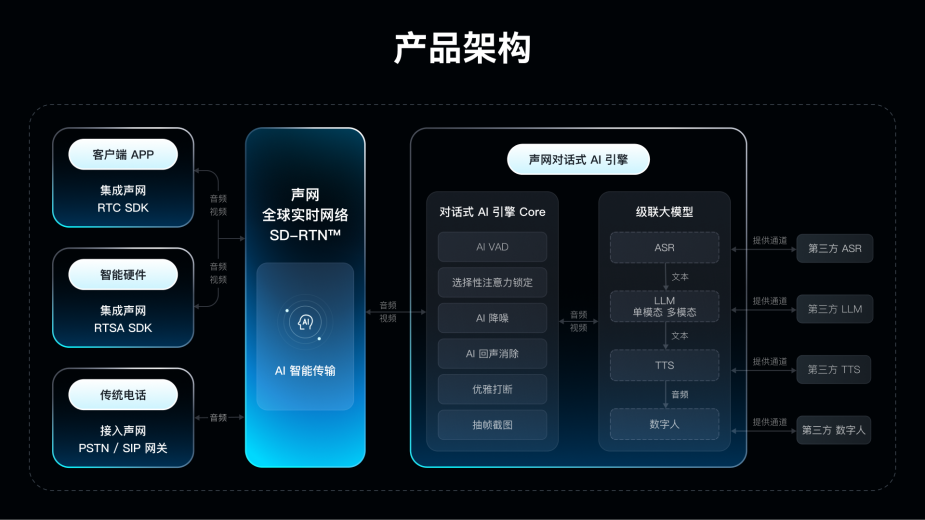
这四个技术挑战,单拎出来都不容易,合在一起更考验底层架构。声网对话式AI引擎正是从这些真实痛点出发设计的。
依托声网在实时互动领域多年的RTC技术积累,引擎将ASR、LLM、TTS模块嵌入实时传输链路,实现边传边处理,端到端语音延迟中位数做到650毫秒,用户几乎感觉不到在等AI回应。打断方面,自研的智能检测算法能在340毫秒内响应插话,同时过滤掉“嗯、啊”这类无意义口头禅,避免误触发。针对嘈杂环境,AI降噪加声纹识别可以屏蔽高达95%的环境人声,多人说话时也能精准锁定你。上下文管理则支持对接主流大模型,实现多轮对话的状态跟踪。情感表达上,TTS支持音色、语速、停顿的细粒度调节,让AI说话不再一个调门到底。
AI语音对话的进化方向,不是背更多的知识,而是更像一个真实的人——能及时接住你的话,能从语气里读懂情绪。而这,正是声网持续打磨底层实时互动能力想要抵达的目标。

