K 歌 & 语聊
智能硬件



AI 外呼在客户服务、营销推广、人力资源、金融风控、市场调研、关怀通知等领域有了广泛应用,成本、效率、体验方面全面领先。





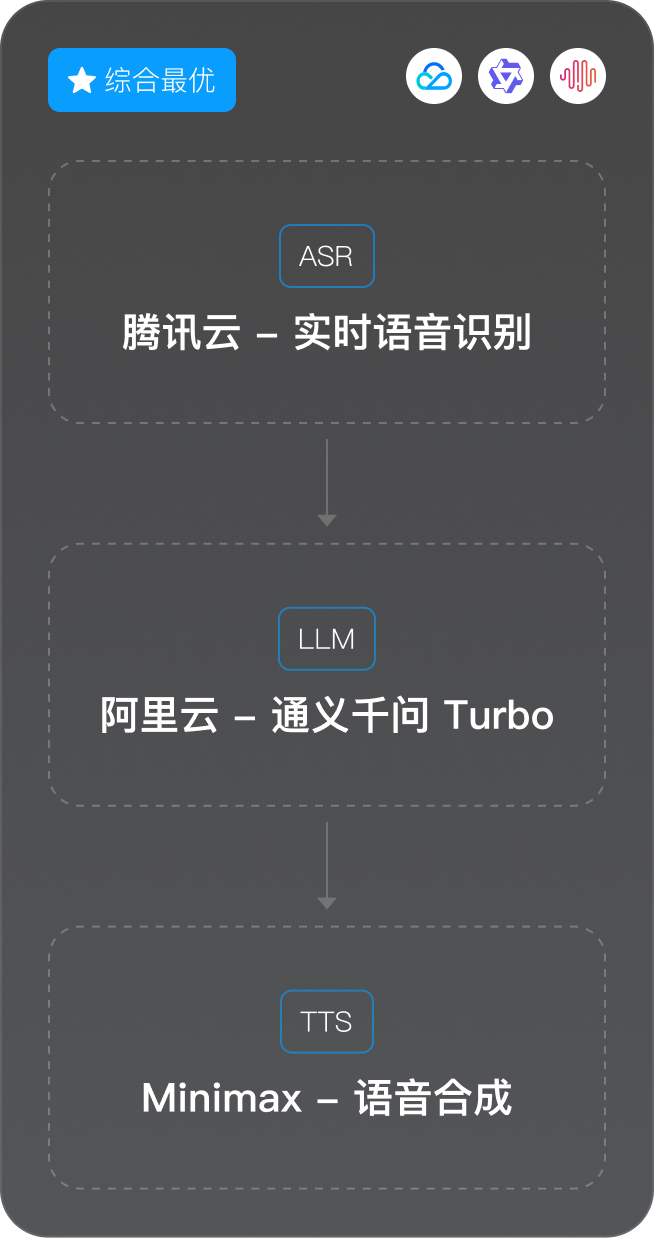

快速编排 ASR、LLM、TTS、数字人、语音体验,实时调试发布智能体
声网对话式 AI 引擎快速编排 ASR、LLM、TTS、数字人、语音体验,实时调试发布智能体






