 首页
首页传统实时 ASR 依赖缓冲式推理,通过重叠音频窗口维持上下文,在规模化场景下面临计算冗余、显存膨胀和延迟漂移等问题,难以支撑高并发语音智能体。NVIDIA Nemotron Speech ASR 基于 FastConformer 架构与 8 倍下采样,引入缓存感知流式处理机制,仅对新增音频增量进行计算,避免重复编码与注意力重算,实现线性扩展和可预测性能。在多种 GPU 平台上,其并发吞吐量提升最高达 5 倍,同时保持零延迟漂移。模型支持运行时动态延迟配置,在低延迟与低 WER 之间灵活权衡,并实现业界领先的 time-to-final 转写速度。Daily 与 Modal 的真实部署验证表明,该架构能够在高负载下维持稳定、接近人类反应速度的端到端语音交互,为实时语音智能体确立了新的技术基线。
在语音 AI 交互领域,我们长期被一个熟悉的权衡所困扰:速度 vs. 准确性。传统的实时自动语音识别(ASR)通常依赖于缓冲式推理(buffered inference)——一种通过反复重新处理重叠音频窗口来维持上下文的变通方案。从计算角度看,这相当于每翻一页书就要重读前几页内容。
NVIDIA Nemotron Speech ASR 是一款专为实时语音智能体打造的全新开源模型,它打破了这一循环。该模型基于 FastConformer 架构,采用 8 倍下采样,并引入了缓存感知(cache-aware)技术,只处理新到达的音频“增量(delta)”。通过复用历史计算结果而非重复计算,它在效率上相比传统缓冲式系统最高可提升 3 倍。
在本文中,我们将探讨缓存感知架构如何重新定义实时语音智能体的性能上限,并展示 Daily 与 Modal 在高并发、低延迟语音智能体工作负载中的真实应用效果。
挑战:为什么流式 ASR 在规模化时会失效
许多被称为“流式 ASR”的系统,实际上并非为真正的大规模实时交互而设计。作为 NVIDIA Nemotron 开源模型家族的一部分,Nemotron Speech 使开发者能够将语音能力无缝接入自定义的智能体工作流(agentic workflows)。
缓冲式推理并不是真正的流式处理
在许多生产系统中,“流式”是通过缓冲式推理实现的:音频以滑动窗口方式进行处理,每一个新窗口都会与前一个窗口产生重叠,以保持上下文连续性。虽然这种方法可以生成正确的转写结果,但从根本上来说,它是低效的。
模型为了维持连续性,不得不反复处理已经看过的音频内容,有时甚至会多次重复计算同一段音频。
重叠窗口造成计算资源浪费
这种重叠带来了每一步的冗余计算:
- 相同的音频帧被重复编码
- 相同的注意力上下文被反复计算
- GPU 的计算负载增长速度快于实际音频流本身
在低并发场景下,这种低效尚可接受;但在大规模部署时,它会变得昂贵且脆弱。
延迟漂移破坏对话式智能体体验
随着并发流数量的增加,缓冲式系统往往会遭遇扩展性断崖。延迟开始不断累积,系统响应相对于用户语音越来越滞后。
这种延迟漂移并非调度问题,而是硬件资源问题。由于缓冲式推理不断重复计算重叠上下文,GPU 显存中充斥着冗余的激活值和中间状态。随着内存压力上升,系统受到越来越多的约束,被迫降低执行速度、削弱批处理效率,甚至在高负载下被直接限流。
对于对话式智能体而言,这是致命的:即便是微小的延迟,也会破坏轮次切换(turn-taking)和打断处理(interruption handling)等下游任务,使交互显得不自然。随着时间推移,系统逐渐严重落后于真实语音,最终无法支持实时对话——或者在必须维持严格延迟阈值的情况下,根本无法扩展规模。
这正是传统流式 ASR 的核心局限:它在单实例或低负载环境中尚可运行,但在真实的多用户系统中,会在计算和延迟压力下迅速崩溃。
解决方案:缓存感知流式 ASR,实现更低延迟、线性扩展与可预测成本
Nemotron Speech ASR 引入了一种新一代流式架构,彻底取代了传统系统中的缓冲式推理模型。其缓存感知设计使实时、高并发的语音智能体成为可能,在不牺牲准确性和鲁棒性的前提下,实现稳定延迟、线性扩展和显著更高的 GPU 吞吐率。
核心优势
- 更低的端到端延迟:减少 ASR 处理时间和冗余计算,显著降低包含 LLM 推理与文本转语音(TTS)在内的整体语音智能体链路延迟。
- 高并发下的高效表现:即使并发提升至原来的 3 倍,延迟仍基本保持平稳,避免了缓冲式系统中常见的性能骤降。在实际应用中,延迟呈次线性增长,只有在并发显著升高后才会出现明显变化。
- 线性内存扩展:缓存感知流式处理避免了内存爆炸,使性能可预测、批处理稳定。
- 更高 GPU 利用率,更低成本:最大化单 GPU 上的并行流处理能力,降低单路语音流的整体成本。
Nemotron Speech ASR 内部架构:FastConformer 与 8 倍下采样
Nemotron Speech ASR 基于 FastConformer RNNT 架构 构建,与此前的 NVIDIA Parakeet ASR 模型一脉相承,并针对流式推理进行了端到端优化。
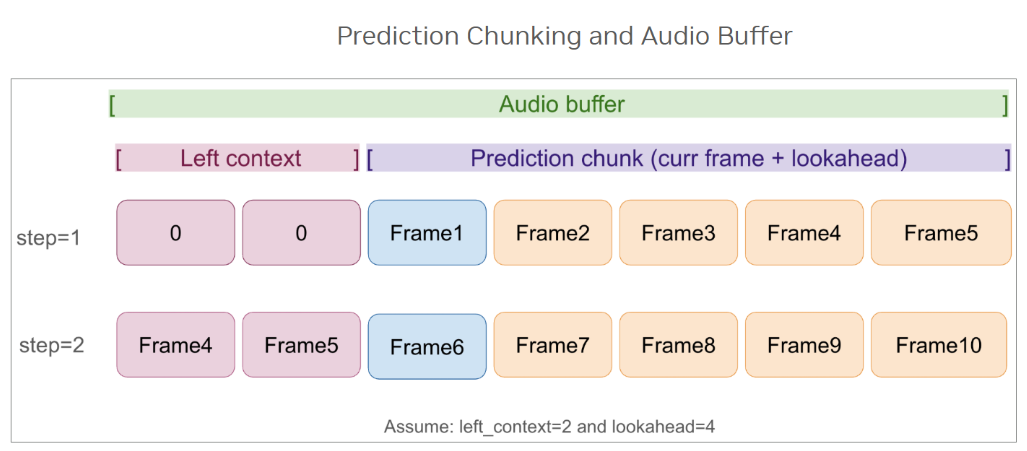
其关键创新之一是通过深度可分离卷积下采样实现 8 倍下采样。相比传统的 4 倍下采样系统,编码器每秒需要处理的 token 数量显著减少,从而降低显存占用并提升 GPU 吞吐能力。
关键工程参数
- 架构:FastConformer,24 层编码器 + RNNT 解码器
- 参数规模:6 亿参数,针对高吞吐 NVIDIA GPU 优化
- 输入:16 kHz 流式音频
- 输出:带标点和大小写的英文流式文本
- 动态可配置延迟模式(运行时调整,无需重新训练):80 ms、160 ms、560 ms、1.12 s
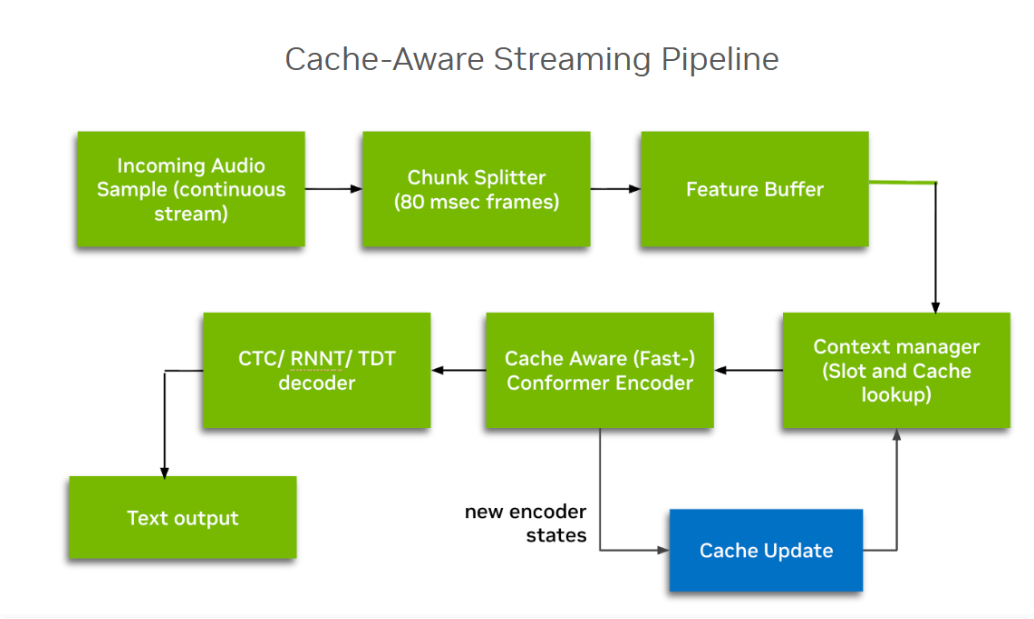
缓存感知流式处理的工作原理
Nemotron Speech ASR 不再对重叠音频窗口进行重复编码,而是在所有自注意力层和卷积层中维护编码器表示的内部缓存。当新的音频到达时,模型只更新缓存状态,而不是重新计算已有上下文。
每一帧音频只会被处理一次,不存在重叠或冗余计算。
这一设计从根本上消除了缓冲式推理的两大问题:
- 对同一音频的重复计算
- 并发增加时的延迟漂移
最终实现的效果是:在高负载条件下仍能保持可预测的端到端延迟与线性扩展能力。
结果:规模化场景下的吞吐量、准确性与速度
高负载下依然稳定的吞吐能力
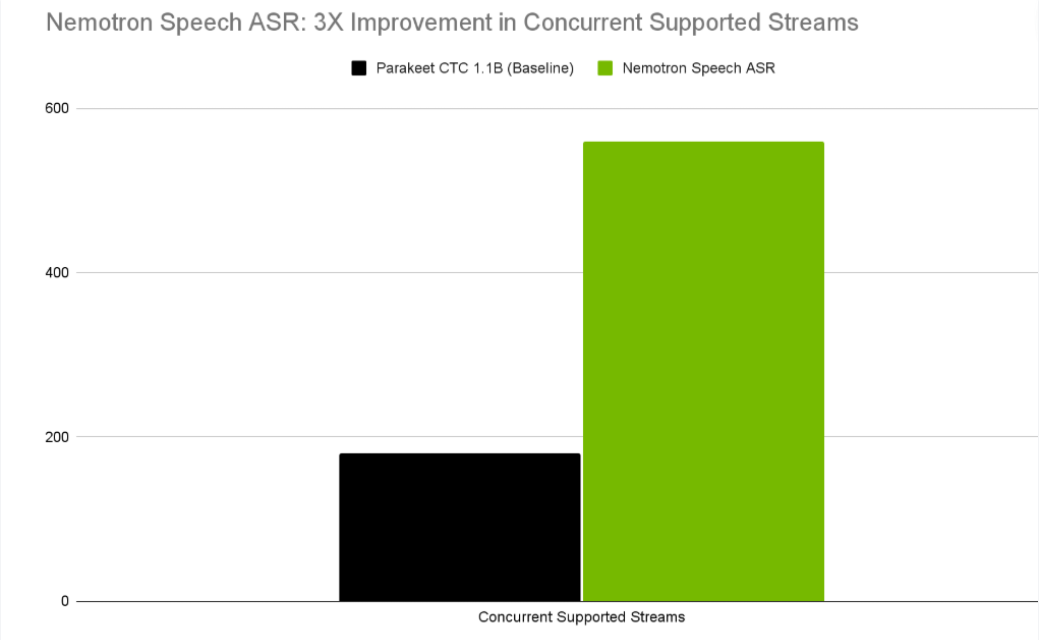
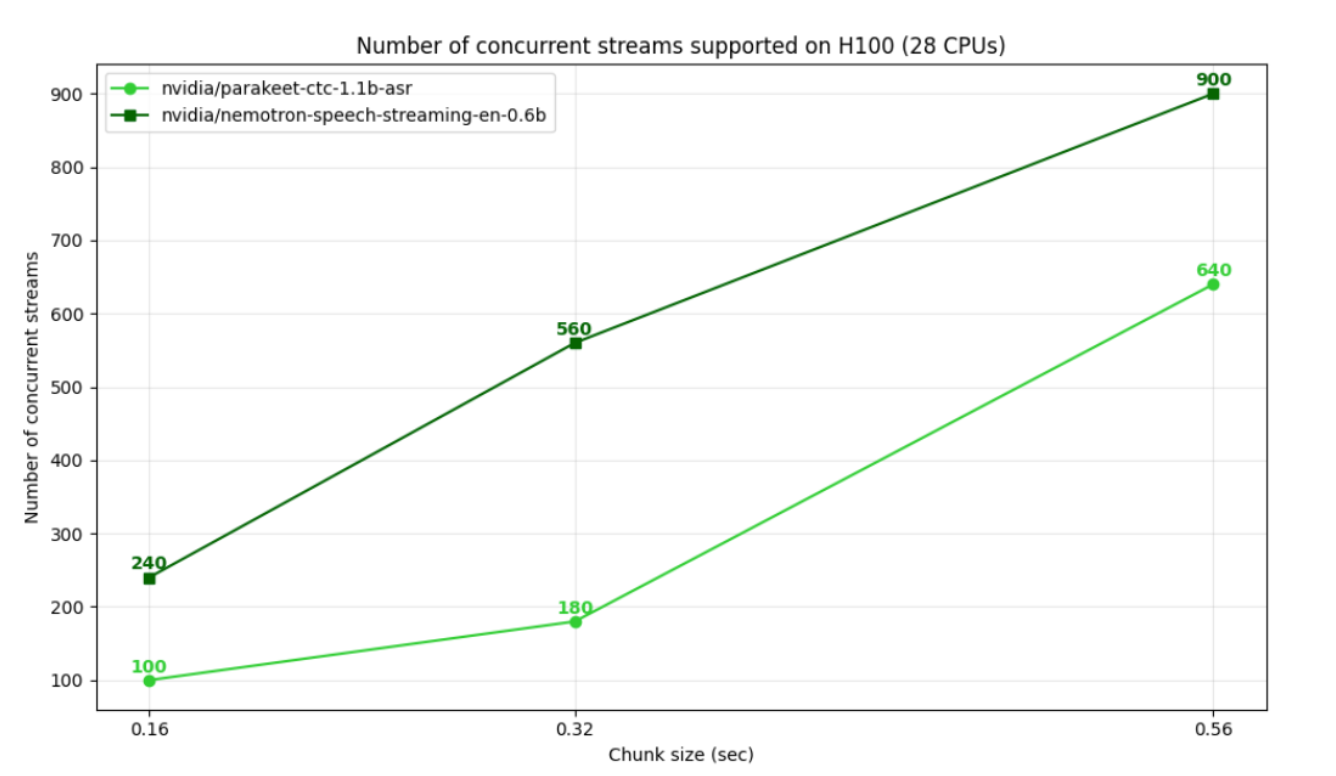
缓存感知流式架构所带来的结构性效率提升,直接转化为显著的吞吐量增益。在 NVIDIA H100 上,Nemotron Speech ASR 在 320 ms 分块大小条件下可支持 560 路并发语音流,相比基线系统(180 路并发)实现了约 3 倍提升。类似的性能提升在整个硬件栈中均有体现:NVIDIA RTX A5000 的并发能力提升超过 5 倍,而 NVIDIA DGX B200 在 160 ms 和 320 ms 配置下的吞吐量最高可提升 2 倍。
更为关键的是,这些基准测试验证了系统在极限负载下的稳定性:即使并发达到峰值,系统依然能够保持零延迟漂移。这一能力并非依赖反复计算,而是得益于受控的内存增长机制与缓存复用策略,从而确保在高并发条件下仍具备可预测的性能表现。
关键场景下的准确性:延迟–WER 权衡
大多数 ASR 排行榜是在离线模式下评估模型的,这在一定程度上掩盖了低延迟在真实世界中的成本。而在流式 ASR中,准确性与延迟是不可分割的。
Nemotron Speech ASR 提供了运行时动态可调的灵活性,使开发者能够在推理阶段(而非训练阶段)选择合适的性能工作点。
当分块延迟从 0.16 秒提高到 0.56 秒时,模型能够捕获更多的音位上下文信息,使 词错误率(WER) 从 7.84% 降低至 7.22%,同时仍然保持实时交互所需的响应能力。
最快的最终转写完成时间(Time-to-Final Transcription)
Nemotron Speech ASR 在本地部署和 API 方案对比中,均展现出业界领先的最终转写完成时间:
- Nemotron Speech ASR:24 ms(中位数)
- 替代方案(本地部署,NVIDIA L40 GPU):90 ms
- 替代模型(基于 API):200 ms 以上
尤为关键的是,即使在长语音输入场景下,最终转写完成时间依然保持稳定——这是实时语音智能体能够自然交互的一个核心特性。
验证(Real-World Validation)
Modal:在规模化场景下验证最小延迟漂移
Nemotron Speech ASR 与 Modal 合作,采用异步 WebSocket 流式传输方式进行评测,以衡量系统在大规模并发条件下的延迟稳定性。
评测设置:
- ASR:Nemotron Speech ASR
- 服务配置:NVIDIA H100 GPU,560 ms 延迟模式
- 负载规模:127 个并发 WebSocket 客户端
- 测试时长:连续 3 分钟 流式输入
该评测用于验证在高并发、长时间运行条件下,系统是否仍能保持稳定、可预测的低延迟表现。
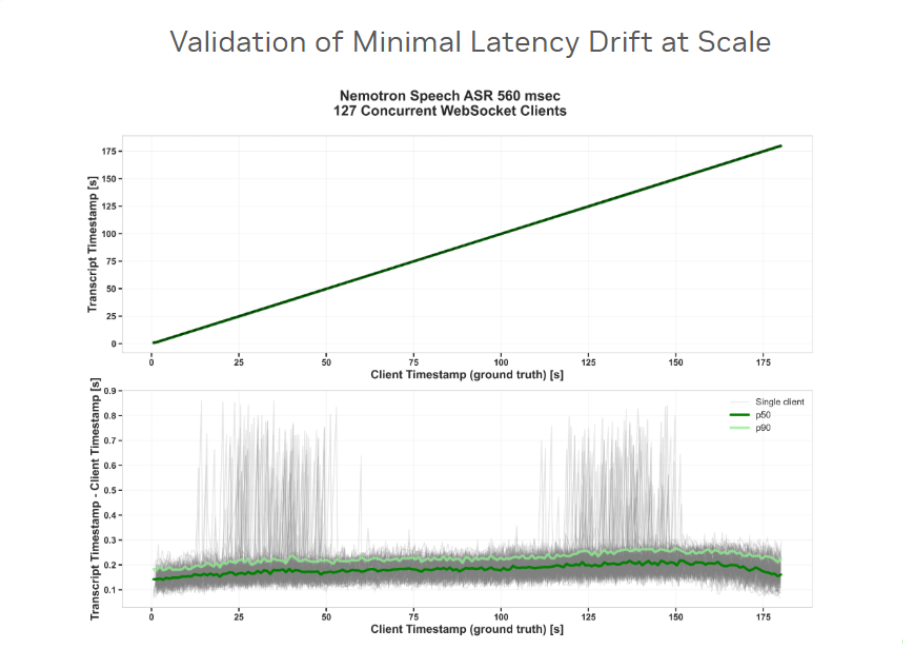
在 127 个并发客户端同时运行的情况下,Nemotron Speech ASR 在 3 分钟的连续流式测试中依然保持了稳定的端到端延迟,几乎没有出现延迟漂移。对于语音智能体而言,这种差异具有决定性意义:哪怕仅仅几秒钟的延迟累积,都会破坏对话轮次切换(turn-taking),并使打断处理(interruption handling)变得不可行。
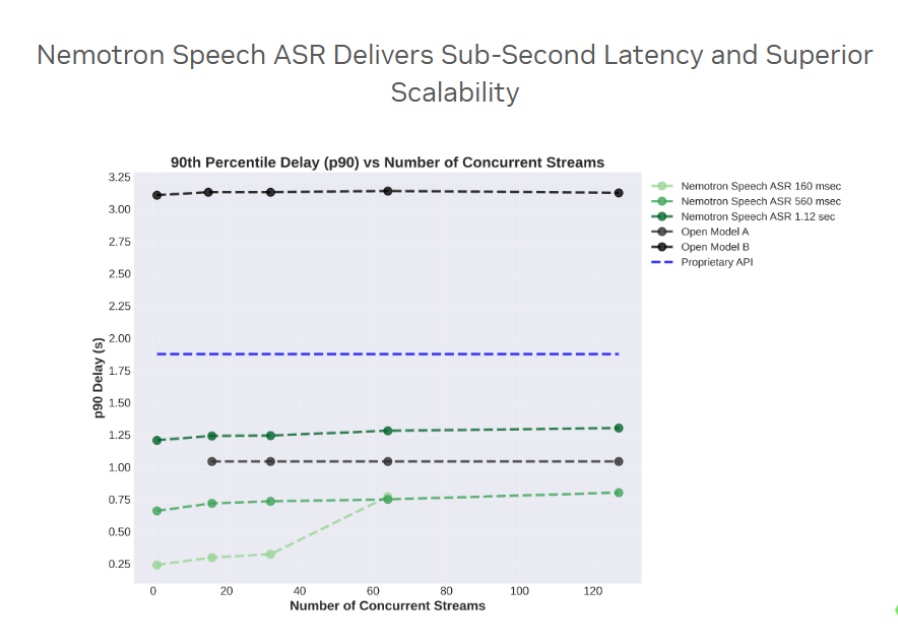
如下所示,Nemotron Speech ASR 实现了此前被认为在实时语音 AI 中难以企及的效率水平。其中,160 ms 延迟配置充分展现了模型的原始速度,在高要求的实时交互场景中,提供了目前最快的“最终转写完成时间(time-to-final)”。
真正让这一架构具有革命性意义的,是其智能化的资源管理能力。在 160 ms 延迟设置下,系统能够将硬件并发能力推至极限;而 Nemotron 同时具备独特的灵活性,可根据需求切换至高容量模式(如 560 ms 或 1.12 s 延迟),从而彻底“压平性能曲线”。这使得即便在大规模企业级部署中,用户依然能够体验到零延迟漂移、接近人类反应速度的交互体验——这是现有的专有 API 难以长期维持的。
Daily:端到端语音智能体性能
Daily 为开发者构建实时音视频基础设施,服务于以语音优先和多模态为核心的应用场景——从 AI 会议助手、客户支持智能体,到实时协作工具。对 Daily 的用户而言,可预测的低延迟语音处理流水线至关重要:任何延迟或抖动都会直接导致对话不自然,显著降低用户体验。
为评估真实世界中的性能表现,Daily 将 Nemotron Speech ASR 集成进一套接近生产环境的完整语音智能体流水线,其组成包括:
- ASR:Nemotron Speech ASR
- 大脑(LLM):Nemotron 3 Nano 30B
- 语音合成:Magpie TTS(多语言),支持 7 种语言、5 种音色
- 编排框架:Daily 的 Pipecat
- 运行平台:Modal、DGX Spark、RTX 5090
在该配置下,Nemotron Speech ASR 的最终转写完成时间(time-to-final)中位数仅为 24 ms,且不随语音长度变化。长语音片段与短语音片段几乎同时完成最终转写——这一特性对于用户发言不可预测的交互式智能体而言至关重要。
从端到端来看,在本地部署条件下,完整的“语音输入 → 语音输出”闭环耗时不足 900 ms。这使系统能够在持续交互过程中依然保持自然的轮次对话体验以及稳定、可预测的低延迟——这正是 Daily 的开发者构建高响应、可投入生产、值得用户信赖的语音智能体所必需的能力。
结论:实时语音智能体的新基线
大多数 ASR 系统最初都是为离线转写而设计,随后才被“移植”到流式场景中。当这些传统方案被推向高并发使用时,其局限性便暴露无遗:延迟漂移、基础设施成本上升,以及用户体验的显著下降。
语音智能体对语音识别提出了根本不同的要求。流式处理和实时交互不再是事后补充的功能,而必须成为一等设计目标。要应对语音优先应用的复杂性,ASR 架构必须从一开始就为低延迟、可扩展性以及高负载下的持续性能而设计。
缓存感知流式处理(cache-aware streaming)正在重塑这一基础。
借助 Nemotron Speech ASR,语音智能体不再需要在速度、准确性和可扩展性之间做取舍。通过消除冗余计算并实现可预测的线性扩展,该模型在大规模场景下提供了亚 100 ms 级响应速度、高并发下的稳定延迟以及真正可用于生产环境的性能表现。
Nemotron Speech ASR 正在为实时、语音优先的 AI 系统确立一个全新的行业基线。
原文链接:https://huggingface.co/blog/nvidia/nemotron-speech-asr-scaling-voice-agents
原文作者:Kunal Dhawan

