 首页
首页我是声网AI产品Evan,曾主导过声网国内外多个对话式AI产品的落地工作。在项目推进过程中,“你有推荐的AI模型厂商吗?”是我被问到最多的问题;与此同时,我也见证了太多企业在模型选型中“踩坑”的真实案例:
- 案例1:金融智能外呼踩坑:一家金融公司为搭建智能外呼系统,选择了某知名厂商宣传的“最强”大模型。然而上线后,首字延迟竟超过3秒,用户投诉接踵而至,项目推进严重受阻。
- 案例2:AI陪伴机器人落地遇阻:一家智能硬件公司研发AI陪伴机器人时,测试环境下模型表现稳定,但部署到IoT设备后,因弱网环境频繁出现断句问题,用户交互体验大打折扣。
这些案例的背后,藏着企业选型时的共性认知偏差:过度迷信模型的宣传能力,却忽视了真实对话链路中延迟、断句、Token/s、弱网适配等关键指标,最终在真实业务场景中栽了跟头。今天,我就结合实战经验,拆解对话式AI模型选型的常见误区,分享科学的选型方法。
一、选型误区:五个高频陷阱,很多人都踩过
1.1 误区一:迷信基准测试,脱离真实业务场景
不少企业在选型时,会把公开的基准测试数据当作核心依据。但这些测试大多在理想环境下完成,与真实业务场景存在巨大鸿沟,根本无法反映模型的实际表现。
真实场景的复杂程度远超基准测试:用户输入可能夹杂口语化表达、方言、错别字,还可能存在背景噪音干扰;对话式AI需处理多轮上下文交互,而非单一轮次的问答。这些关键变量都会直接影响模型性能,但基准测试往往难以覆盖。仅凭基准测试数据选型,无异于“纸上谈兵”。
1.2 误区二:紧盯准确率,忽视延迟与吞吐的平衡
准确率固然是核心指标,但绝非唯一指标。要提升语音识别准确率,常见手段包括强化上下文理解、扩大模型吞吐量,而这必然会导致延迟增加——延迟与准确率本质上是“此消彼长”的关系,需要根据业务场景找到平衡点。
对话式AI的核心是“实时交互”,延迟直接决定用户体验:首字延迟超过2秒,用户就能明显感知卡顿;流式响应速度过慢,会直接打断对话节奏;遇到高峰期并发请求激增时,若模型吞吐能力不足,还可能导致服务瘫痪。这些性能指标与准确率同等重要,却常常被企业忽视。
1.3 误区三:只测理想环境,无视弱网与硬件限制
企业选型测试时,往往采用稳定网络+标准服务器的理想环境,但实际部署场景却复杂得多:
- 网络环境:移动网络波动、WiFi信号不稳定等弱网场景;
- 硬件条件:IoT设备算力有限、内存不足的资源约束;
- 通信链路:电话线路的窄带编码、复杂环境的噪音干扰。
真实环境中,模型的断句处理能力、降级策略有效性、资源优化水平,才是决定其能否落地的关键。理想环境下的测试结果,根本无法反映模型在真实场景的表现。
1.4 误区四:缺乏系统评估,凭经验“拍板”选型
很多企业的选型决策依赖“过往经验”或“行业口碑”,没有建立系统性的评估体系。但不同业务场景对模型的核心需求差异极大,盲目套用经验必然踩坑:
- 智能客服场景:依赖电话沟通,天然存在较高延迟,若模型本身延迟高,叠加效应会严重恶化用户体验,因此“低延迟”是核心诉求;
- 智能硬件场景:受限于硬件算力和不稳定网络,模型的弱网适配、断句处理能力至关重要,否则易出现交互中断、频繁重连问题;
- 在线智能体场景:用户对交互质量期待高,模型需具备优质的输出质量和内容多样性,才能满足复杂对话需求。
缺乏明确的评估维度和量化指标,选型决策必然带有主观性,踩坑概率大幅提升。
1.5 误区五:计量单位混乱,成本预估失真
对话式AI涉及ASR(语音识别)、TTS(语音合成)、LLM(大语言模型)三个核心环节,而三者的计费逻辑和计量单位完全不同:
- ASR:按音频时长计费,单位为分钟或秒;
- LLM:按字符数计费,计量对象为合成文本的字符数;
- TTS:按Token数计费,计量对象为输入Token与输出Token之和。
更复杂的是,不同厂商的定价结构差异巨大,有的按分钟计费,有的按Token计费,还有的按请求次数计费。企业选型时,很难将不同模型的成本统一到同一维度对比,导致成本预估不准确,往往上线后才发现成本远超预期。
二、关键指标:对话式AI引擎的核心考核维度
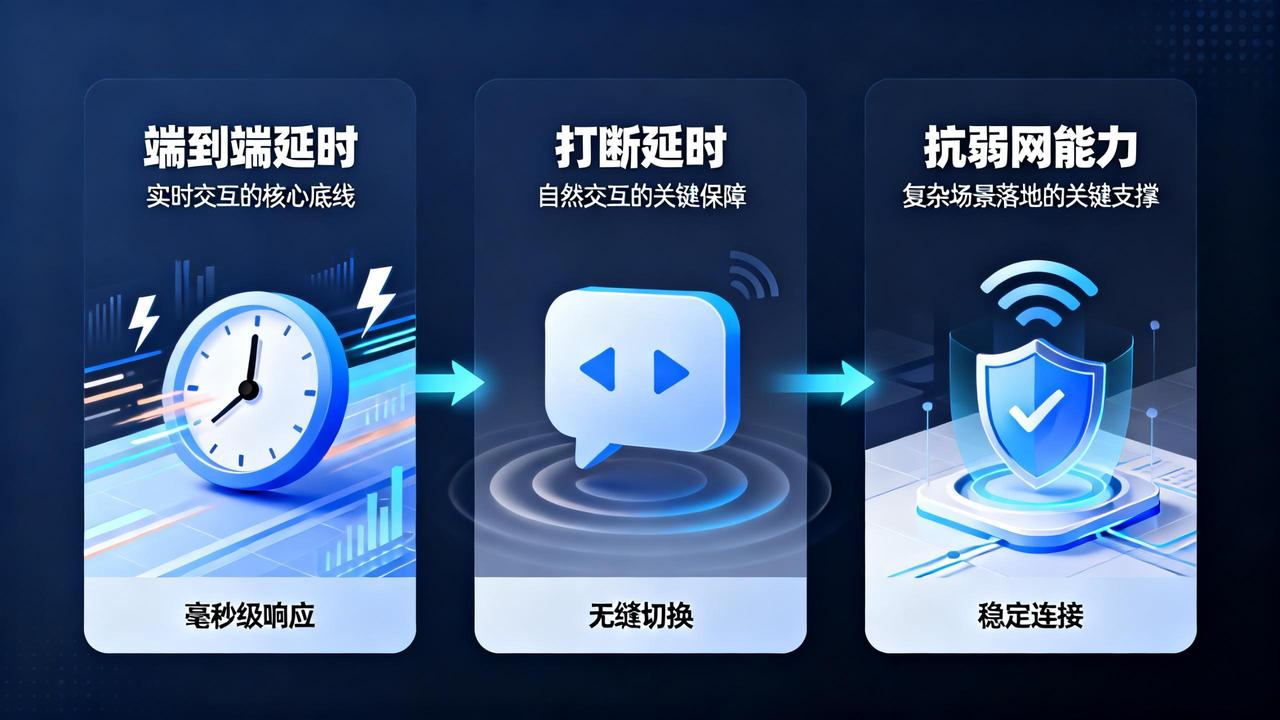
对话式AI引擎的核心考核维度图示
2.1 端到端延时:实时交互的核心底线
端到端延时是对话式AI引擎最核心的性能指标,指从用户发起语音输入(或文本输入)开始,到系统生成并返回有效响应(语音/文本)的全链路耗时,直接决定用户交互体验的优劣。相较于单一的首字延迟,端到端延时更能反映引擎的综合处理能力,其核心细分维度包括:首字延迟(Time to First Token,TTFT)、流式响应持续延时、末字延迟(Time to Last Token,TTLW)。其中,首字延迟超过1.5秒用户会产生明显等待感,端到端总延时若超过3秒,将直接打破对话的自然节奏,导致用户注意力分散甚至放弃交互。对于智能外呼、实时客服等强实时场景,端到端延时需控制在2秒内才能保障良好体验。
2.2 打断延时:自然交互的关键保障
打断延时是衡量对话式AI交互自然度的核心指标,指用户在系统响应过程中发起打断指令(如语音插话、按键打断)后,系统停止当前响应并切换至接收新输入状态的耗时。真实对话场景中,用户常因需求变更、信息补充等原因需要打断系统,若打断延时过长(超过500毫秒),会出现“用户已说完但系统仍在继续响应”的尴尬情况,严重破坏交互连贯性。优质的对话式AI引擎需将打断延时控制在300毫秒内,同时具备精准的打断检测能力,既能快速响应有效打断,又能避免被背景噪音、短暂停顿误触发,保障对话的流畅性与自然度。
2.3 抗弱网能力:复杂场景落地的关键支撑
抗弱网能力是对话式AI引擎在真实场景中落地的核心支撑指标,直接决定引擎能否适配移动网络波动、WiFi信号不稳定、电话线路窄带等复杂网络环境。其核心评估维度包括:弱网环境下的响应稳定性(无频繁断句、卡顿)、网络抖动时的降级策略有效性、低带宽适配能力(如窄带编码下的语音识别/合成质量)以及网络恢复后的会话接续能力。优秀的对话式AI引擎需具备自适应网络调节机制,例如在弱网时自动优化数据传输格式、降低非核心数据冗余,保障基础交互功能正常;同时支持会话状态缓存,网络恢复后可无缝接续此前对话上下文,无需用户重新发起交互,避免因网络问题导致用户体验断层。
三、行业趋势:对话式AI从“能用”到“好用”的核心转变
当前,对话式AI正从概念验证走向规模化应用,企业对模型的选型逻辑也在发生三大关键转变:
- 从“选最好的”到“选最合适的”:不再盲目追求模型参数规模或单一维度的准确率,而是结合业务场景匹配核心需求——客服场景优先选低延迟模型,内容生成场景优先选强能力模型;
- 从“单点优化”到“全链路优化”:企业开始关注从用户输入到结果输出的全链路表现,包括网络传输、模型推理、结果返回等各个环节,而非只聚焦模型本身;
- 从“一次性选型”到“持续评估”:模型在迭代,业务需求在变化,选型不再是“一锤子买卖”,而是伴随业务发展的动态优化过程。
四、声网 AI 模型评测平台:科学选型的5条实践路径
4.1 建立多维度评估体系,锚定真实场景
选型的核心是建立系统性的评估体系,覆盖性能、成本、稳定性等多个维度,且所有评估必须在真实业务场景下开展,而非依赖理想环境测试。
声网AI模型评测平台(对话式)基于声网对话式AI引擎的真实运行环境,提供延迟、断句、Token/s、弱网表现等多维度性能数据。这些数据均来自实际对话链路的测试结果,而非理想环境的基准测试,能为企业选型提供更可靠的参考。
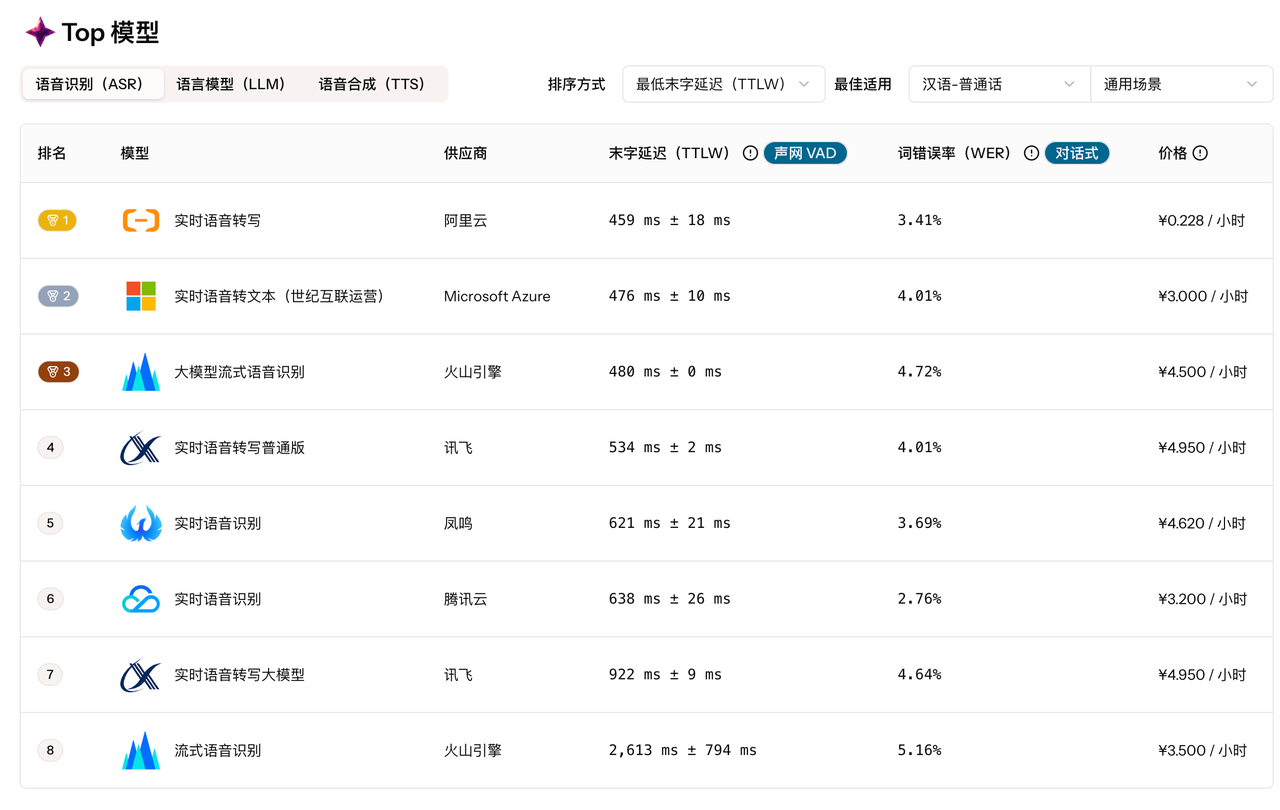
声网AI模型评测平台(对话式)界面
4.2 搭建模型“竞技场”,直观对比核心差异
选型的关键是客观对比,但不同模型在不同环境下的表现差异巨大,如何实现公平对比?声网Benchmark的“竞技场”功能给出了答案:让多个模型在相同条件下同台竞技,直观展示末字延迟(TTLW)、词错误率(WER)、级联模型总延迟等关键指标。
同时,平台还提供“组合Top 10”排名,汇总不同ASR、LLM、TTS组合的综合表现。企业可根据业务场景(如“最佳适用中文”“低延迟优先”)快速筛选,精准找到最适配的模型组合,避免“纸上谈兵”。
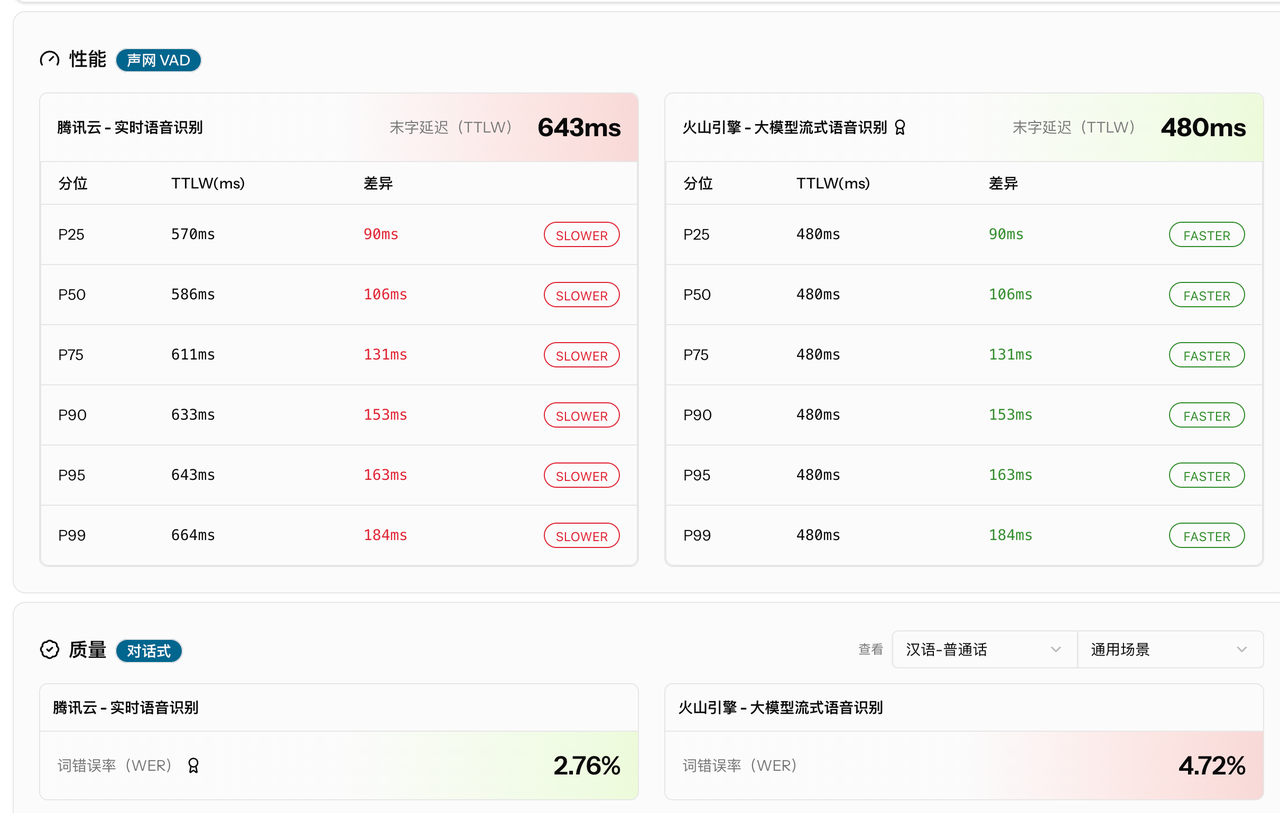
声网 Benchmark 竞技场功能
4.3 统一成本核算维度,提前规划预算
成本是选型的重要考量,但ASR、TTS、LLM的计量单位差异大,不同厂商定价结构混乱,导致成本对比难度极大。声网Benchmark的“价格估算”功能,可将三个环节的成本统一核算,输出级联模型的总价格。
企业只需输入预期调用量、并发规模等参数,就能提前估算不同模型组合的总成本,无需手动换算复杂单位。平台还提供“综合最优”“响应最快”“价格最低”等多维度推荐组合,每个组合均标注级联模型总延迟和总价格,帮助企业在性能与成本之间找到平衡点。
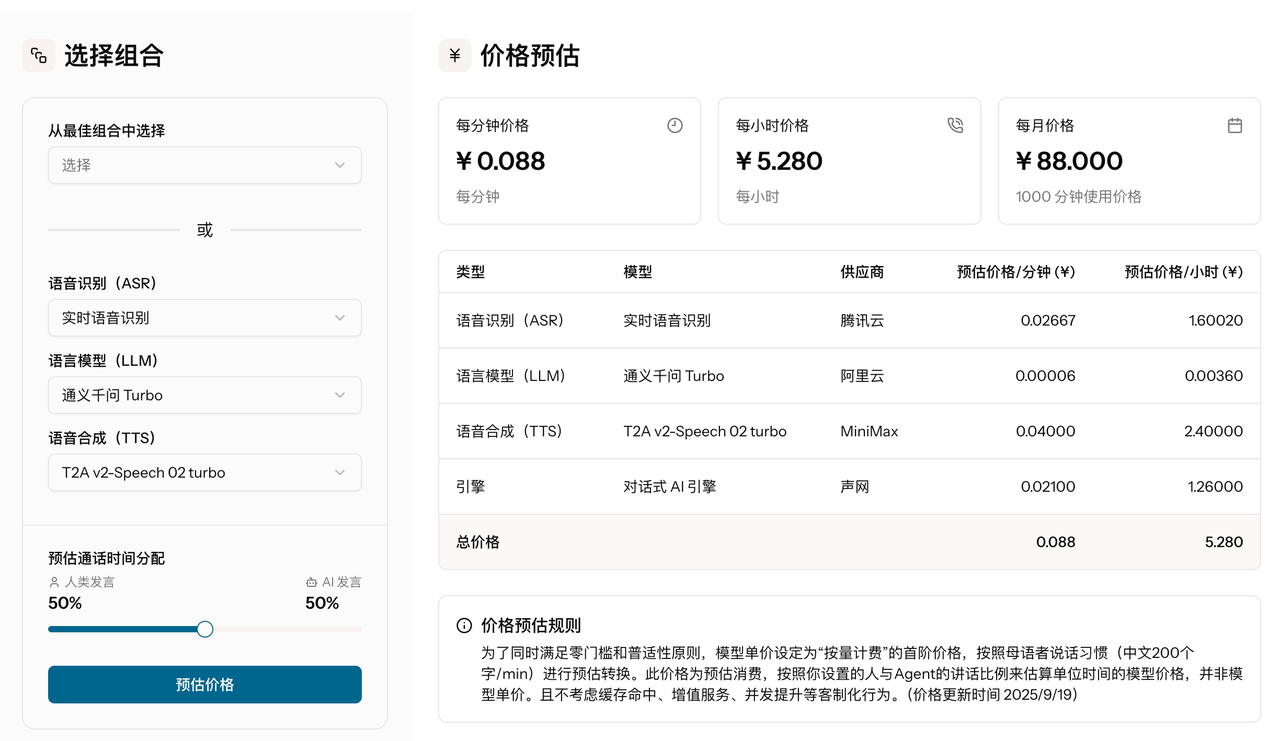
声网 Benchmark 的“价格估算”功能
4.4 量化对比指标,让数据驱动决策
避免主观判断和经验依赖的核心,是用量化数据说话。声网Benchmark能精准呈现延迟、断句、Token/s、弱网表现等关键指标,全面展现模型在真实环境中的性能。这些数据来自声网对话式AI引擎适配各主流模型的实时性能测试,确保真实性和可参考性,让选型决策更科学。
4.5 聚焦真实数据,拒绝被宣传“绑架”
模型厂商的宣传往往只突出优势、回避短板,仅凭宣传材料很难全面了解模型真实表现。声网Benchmark的模型总览功能,汇总了各主流模型在不同指标下的真实表现,企业可基于这些数据,结合自身业务需求,做出不被宣传干扰的理性决策。
五、实践思考:3个关键动作,彻底避开选型陷阱
5.1 先明确业务需求,再锁定选型标准
选型前,必须先理清业务场景的核心诉求,比如:目标首字延迟是多少?预期并发量能达到多少?部署环境是云端、IoT设备还是电话线路?成本预算范围是什么?这些需求将直接决定评估指标的优先级,避免盲目选型。
5.2 建立持续评估机制,动态优化选型策略
模型迭代永不停歇,业务需求也会随发展变化,因此必须建立持续评估机制,定期对比不同模型的表现,及时调整选型策略。声网Benchmark会持续更新各主流模型的性能数据,企业可定期查看最新结果,评估现有模型是否仍适配业务需求,让选型从“一次性决策”变为“动态优化过程”。
5.3 兼顾短期落地与长期发展,提前规划可扩展性
选型不能只关注当前需求,还要考虑长期成本与可扩展性。比如,模型是否支持升级迭代?能否适配未来业务量的增长?成本是否会随规模扩大而合理优化?这些问题都需要在选型阶段提前规划,避免后期因模型无法适配业务发展而重新选型,增加额外成本。
六、结语:选型是起点,持续优化才是成功关键
模型选型是对话式AI项目的起点,但绝非终点。选型的质量决定了系统的性能上限,而项目的最终成功,还需要后续的持续优化和迭代。
在对话式AI从“能用”走向“好用”的浪潮中,数据驱动的选型决策是最可靠的路径。通过声网AI模型评测平台这类工具开展量化评估,能帮助企业跳出主观判断和经验依赖的误区,选到真正适配业务场景的模型。
声网AI模型评测平台基于真实对话链路提供多维度性能数据,通过模型对比、价格估算等核心功能,让选型决策“有数据可依”,而非“被宣传绑架”。科学选型是对话式AI项目成功的第一步,只有选对模型,才能为后续的全链路优化和规模化落地打下坚实基础。

