 首页
首页清晨的街道上,脚步声、风声和呼吸声交织在一起。一个正在跑步的用户,气喘吁吁地对着手机里的 AI 喊了一句:“帮我订一家苏州的酒店。”
AI 沉默了两秒,伴随着滋啦滋啦的电流声,自信地回答:“好的,正在为您播放《苏三起解》的乐曲。”
对用户来说,这是一个标准的“人工智障”时刻。但对任何做过实时语音与对话系统的工程团队来说,这简直是一场找不到嫌疑人的“悬案”。
问题究竟出在哪里?
- 是耳朵背?(ASR 语音识别错把“苏州”听成了“苏三起解”)
- 还是反应慢?(网络卡顿导致音频丢包,AI 根本没听全)
- 又或者,是多种因素叠加后的一次系统性失误?
在真实世界中,只要涉及实时语音采集、网络传输与即时生成,几乎所有语音对话系统都会面临类似挑战。
在这个“万物皆可对话”的时代,做一个能聊天的 Demo 并不难;真正困难的是——在嘈杂环境、弱网条件、用户情绪不可控的情况下,依然保持自然、稳定、可打断的对话体验。
也正因为如此,行业里逐渐形成了一个共识:如果只靠人肉测试,永远无法真正覆盖真实世界。
为了终结这种“出了问题却不知道该怪谁”的局面,越来越多工程团队开始尝试用系统化的方法,去逼近真实场景。在这样的背景下,我们开始尝试搭建一套针对对话式 AI 的自动化“AI 魔鬼训练营”。
我们把它们扔进最恶劣的环境里,进行 24 小时不间断的“特种兵体检”。
第一关:五官科体检(专治“耳背”)
很多人以为 AI 听不懂是因为傻,其实多半是因为“聋”。
在安静的实验室里,AI 的听力都能达到专八水平。但现实世界是残酷的。

在我们的训练营里,AI 每天要接受成千上万次“听力轰炸”。这不是简单的播放录音,我们构建了一个“噪声注入系统”:
- 模拟“菜市场”:我们在纯净的语音指令中,实时叠加高分贝的人声嘈杂、装修电钻声、甚至是呼啸的风声。
- 方言攻击:我们让“虚拟测试员”不再说播音腔,而是操着一口塑料普通话,甚至中英文夹杂(“帮我 check 一下那个 offer”)。
我们盯着一个叫 WER(词错误率) 的指标。如果 AI 不能在背景音比说话声还大的情况下,把“退票”这两个字精准地抠出来,那它连走出实验室的资格都没有。
第二关:抗压测试(模拟“路怒症”用户)
听清了只是第一步。现在的用户被短视频惯坏了,不仅要求 AI 听得懂,还要求 AI “秒回”。
这就涉及到了一个交互流畅性指标: 用户停止说话后到AI回复第一个字的时间。
- 1~2秒:用户觉得还行。
- 3秒:用户开始看手机屏幕,怀疑是不是死机了。
- 5秒:用户已经在心里骂人了。
为了测试这个,我们设计了一群“暴躁型”考官。它们不讲武德,专门搞“打断测试”(Barge-in):

当 AI 正在喋喋不休地朗读酒店列表时,考官会突然插嘴:“太贵了!我要 500 以下的!”
这时候,我们通过毫秒级的探针去监测 AI 的反应:
- 耳朵是否灵敏? 能否在自己说话的声音中,精准捕捉到用户的插话(AEC 回声消除)。
- 反应是否果断? 必须立刻切断当前的语音流(VAD Cutoff),不能像个复读机一样把那句“为您推荐…”念完。
只有在1秒完成“闭嘴、聆听、重新思考、生成新答案”一整套动作的 AI,才算通过了抗压测试。
第三关:极限生存(穿越“信号隧道”)
你肯定遇到过这种情况:电梯门一关,电话那头就喂喂喂听不见了。
对于实时语音 AI 来说,弱网就是噩梦。音频包一旦丢失,用户听到的就是鬼畜般的卡顿。
为了复现这种噩梦,我们不需要真的去坐地铁,而是直接在网络层制造“人造灾难”:
在这样极端的环境下,我们测试 AI 的“脑补能力”(丢包补偿技术)。优秀的 AI,即使丢了一半的音频包,也能通过算法把声音“补”得像模像样,至少让用户听起来是连贯的,而不是一串电音。
第四关:全方位演习与“众测”
通过了上面所有的酷刑,AI 能不能让人”舒服”。
但我们怎么知道它回答得好不好?靠人听?我们每天有几万条测试数据,把测试人员听聋了也听不完。
于是,我们引入了多维的评测维度,综合运用了VAD等传统的方法。
由于主观体验是个多维度综合的体验指标——流畅度、准确性、共情能力、边界感等等。
所以,我们也准备了最传统的方法众测。
我们让真实的人去听每一场对话,去感受每一次交互的温度,去标注每一个细节——这句话有没有踩到用户的痛点?
那个回答是不是太机械了?这个转折是否自然?这些来自真实用户的标注,汇聚成了我们最宝贵的财富:一个系统的、庞大的语料库。
它记录着人类对“好对话”的真实理解,也记录着 AI 每一次进步和每一次失误。
这不是黑科技,这是人肉堆出来的智慧。每一份标注,都是为了让 AI 更懂人。
尾声
在这个”魔鬼训练营”里,每一天都在上演着成千上万次并没有人类参与的对话。
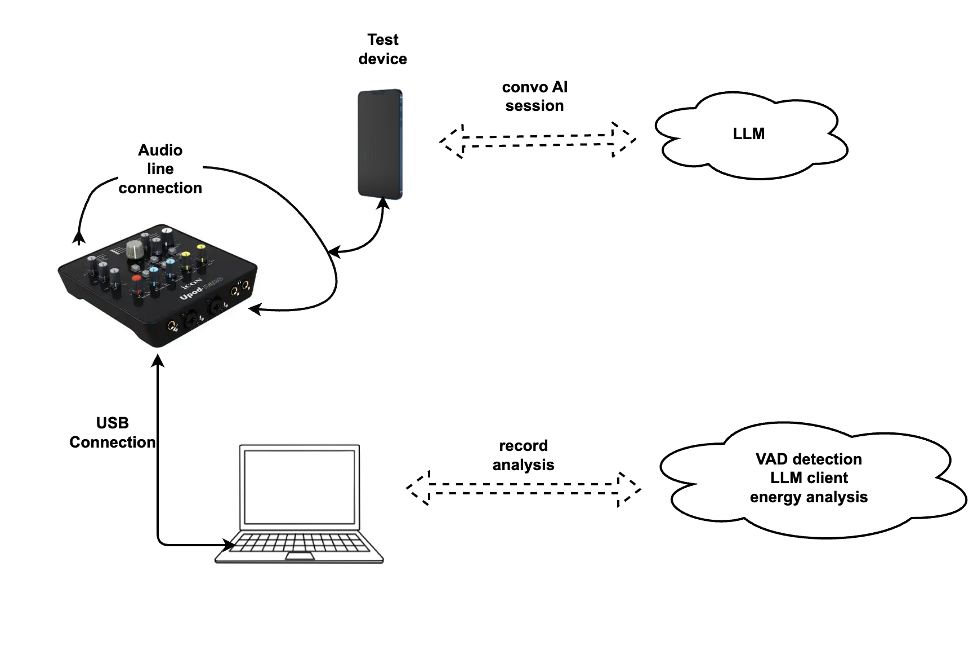
我们搭建了一套自动化测试系统,制造噪音、切断网络、模拟暴躁用户,本质上都是在做一件事:
把所有的”人工智障”时刻,都拦截在实验室里。但光有机器测试还不够。
每一场对话结束后,我们还会让真实的人去听、去感受、去标注。
这些来自众测的反馈,汇聚成我们最庞大的语料库——它记录着人类对”好对话”的真实理解,也记录着AI每一次进步和每一次失误。
这样,当你下次在寒风中对着手机喊出指令时,得到的不再是冰冷的”我不理解”,而是一句温暖且及时的回应。
这大概就是我们要把测试做到极致的全部意义。

