 首页
首页从半双工到全双工:对话系统的进化
请想象一下我们使用对讲机进行对话的场景:一个人说完话必须说“完毕”,然后松开按钮,另一个人才能开始说话。这种“你说完我再说”的模式就是半双工通信。传统的语音助手大多采用这种模式——用户说完一句话,系统检测到一段沉默后才开始回应。这就像两个人在打乒乓球,一个人发球,另一个人接球,循环往复。
而全双工对话系统则完全不同,它更像我们日常的面对面交谈。想想你和朋友聊天时的场景:
- 朋友说到一半,你可能会点头说“嗯嗯”表示在听
- 当你觉得朋友要说完了,可能会稍微吸一口气准备接话
- 有时你们甚至会同时说话,然后其中一个人会礼貌地让另一个人先说
- 偶尔还会出现两个人异口同声说出同样的话,然后相视一笑
这种自然流畅的对话方式,就是全双工对话系统追求的目标。系统能够一边说话一边听,实时处理用户的插话、反馈,甚至能预测用户何时要说话,提前做好准备。
轮次转换:全双工对话的核心挑战
如果说全双工对话是目标,那么轮次转换(Turn-taking)就是实现这个目标必须解决的核心问题。轮次转换研究的是对话中“谁在什么时候说话”的协调机制。
让我们通过一个生活化的例子来理解一下这个概念。假设你在给朋友讲一个精彩的故事:
“昨天我跟我朋友去了一家新开的餐厅……”(你暂停了一下,喝了口水)
这时你的朋友面临一个判断:这里我该接话吗?我应该给出一个反馈,还是安静的继续听你说?
这个看似简单的判断,实际上涉及多个复杂的信号:
1. 转换相关位置(TRP – Transition Relevant Place)
根据Sacks等人(1974)的经典定义,TRP是话轮构建单位(TCU)完成后可能发生话轮转换的位置。但重要的是,TRP并不是一个二元概念——研究表明它更像是一个概率连续体。某个时刻适合转换的程度可以从“几乎不可能”到“高度可能”连续变化。
让我们通过地图任务对话来理解(这是一个turn-taking研究的经典场景):
场景:A在给B描述地图路线
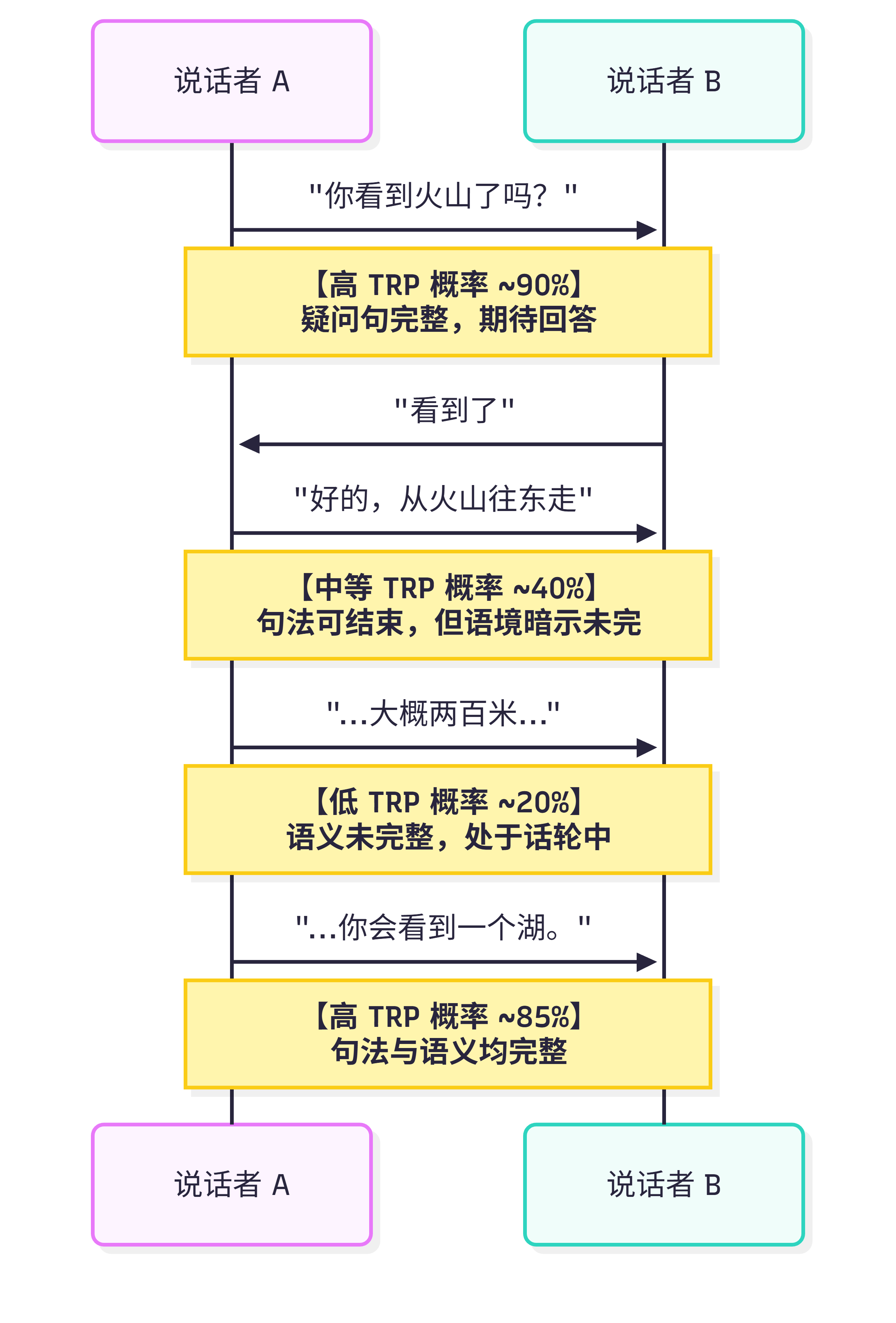
为什么TRP是概率性的?
研究发现,即使在明确的TRP位置,话轮转换也只是可能而非必然。根据Sacks等人的规则:
- 当前说话者可以选定下一个说话者(other-select)
- 如果没有选定,任何人可以自我选择(self-select)
- 如果无人接话,当前说话者可以继续
这种可选性,加上多种信号的相互作用,使得TRP本质上是概率性的。人类对话中典型的200毫秒间隙反应时间,说明听者在预测和准备,而不是被动等待。
2. 话间停顿单位(IPU – Inter-pausal Unit)
IPU是语音处理中的基础概念,指一段连续的、没有明显停顿的语音。Brady(1965)最早使用这个概念来自动分析话轮模式。技术上,IPU通过语音活动检测(VAD)来识别,停顿阈值通常设为200毫秒。
关键区分:停顿(Pause) vs 间隙(Gap)
- 停顿:同一说话者的IPU之间的沉默
- 间隙:不同说话者IPU之间的沉默
研究发现的关键数据
- 话内停顿平均时长:520ms(Ten Bosch等,2005)
- 话轮间隙平均时长:200ms(Levinson & Torreira,2015)
这个反直觉的发现——停顿比间隙长——说明沉默时长并不是判断话轮结束的可靠指标。如果系统简单地使用700ms的沉默阈值:
- 问题1:在520ms的思考停顿处错误地接话(打断用户)
- 问题2:在200ms的话轮间隙后还在等待(反应迟钝)
这就是为什么现代对话系统需要更复杂的模型,而不能仅依赖沉默检测。
3. 话轮构建单位(TCU – Turn Constructional Unit)
Sacks等人(1974)提出的TCU是话轮组织的核心概念。TCU是在特定语境下能够构成完整交际行为的最小单位。每个TCU结束后都有一个TRP,但不是所有TRP都会发生话轮转换。
Ford & Thompson(1996)的完整性层次:
- 句法完整:语法结构完整
- 语用完整:构成完整的交际行为 + 具有”终结”韵律
看一个实际例子(改编自Ford & Thompson的研究):

关键洞察:
- Ford & Thompson发现约50%的句法完整点也是语用完整点
- 在语用完整点,约50%会发生实际的话轮转换
- 这说明TCU边界是必要但不充分的转换条件
TCU vs IPU:

虽然有3个IPU(物理切分),但只有1个TCU(语义单位)。系统不应在IPU边界处接话,而应等待TCU完成。
4. 话轮转换信号(Turn-taking Cues)
人类会使用丰富的多模态信号来协调话轮转换,就像交响乐团的不同乐器共同演奏。让我们通过一个朋友聚会的场景来理解这些信号:
场景:朋友A在讲述周末经历
语义信号
- 让出话轮:“所以我就去了那家新开的餐厅。”(句法完整+语用完整)
- 保持话轮:“所以我就去了那家新开的餐厅,然后…”(”然后”明确表示继续)
- 填充停顿:“那个…嗯…怎么说呢…”(用填充词占住话轮)
韵律信号
- 升调↗:“你们去过那家餐厅吗?”(疑问,期待回应)
- 降调↘:“味道真的很不错。”(陈述完成,可以接话)
- 平调→:“味道不错,服务也好,环境…”(列举中,请勿打断)
- 拉长音:“那个味道啊——”(拖长音准备结束或在思考)
呼吸模式
想象朋友A说到激动处:
- 深吸一口气 “你们绝对想不到…” ← 明显的“我要开始说了”
- “…后来发生了什么!” 长呼气 ← “我说完了,该你们了”
- “那个服务员” *快速吸气* “他居然…” ← 快速补充,别插话
视觉信号
- 目光轨迹:讲述时看别处→结束时扫视大家→最后定格在某人(选定下一个说话人)
- 手势节奏:双手比划→手势完成→手放下(像指挥家放下指挥棒)
- 身体姿态:身体前倾讲述→讲完后靠回椅背(物理性”退场”)
5. 反馈渠道(Backchannels)
Yngve(1970)首次提出“反馈渠道”概念,指听者在不打断说话者的情况下给出的简短反馈,有时候也会被简称为“BC words”。这些信号表明听者在积极参与对话,但不构成话轮转换。
Schegloff(2000)的合作性重叠分类:
- 终端重叠:预测话轮结束,稍早开始说话
- 反馈渠道:简短的声音反馈(”嗯”、”是的”)
- 条件性接入:协助完成说话者的句子
- 齐声说话:同时说出相同内容
下面这个是一个反馈渠道的实例分析:

区分反馈渠道 vs 话轮尝试的声学特征(French & Local, 1983):
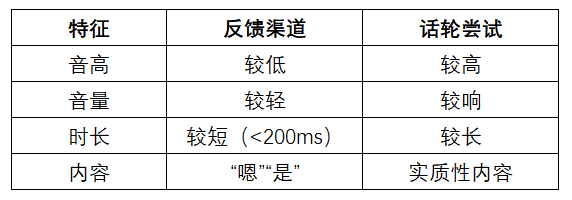
反馈渠道的时机(Ward, 1996):
- 日语:低音高区域后约200ms
- 英语:升调后更容易引发反馈(Gravano & Hirschberg, 2011)
为了实现一个全双工的对话系统,我们必须想办法实时判断用户的发声是反馈信号还是插话尝试,这将直接影响是否应该停止当前话轮。
从理论到实践:全双工对话系统的实现
实现全双工对话系统就像教会计算机跳探戈——需要精确的时机把握、对伙伴意图的理解,以及优雅的进退配合。系统需要:
- 持续感知:不仅在用户说话时听,自己说话时也要保持”耳朵张开”
- 预测能力:根据多种信号预测用户何时要说话,提前准备
- 灵活响应:能够优雅地处理打断、重叠和各种意外情况
- 自然生成:产生合适的话轮保持信号(如“嗯…”表示在思考)和话轮转让信号
这种从“乒乓球式”对话到“舞蹈式”对话的转变,代表着人机交互向更自然、更人性化方向的重要进步。全双工对话系统不仅让交流更高效,更重要的是让用户感受到被理解、被尊重,就像在和一个真正懂得倾听的朋友交谈。随着技术的发展,我们正在逐步接近这个目标。从简单的沉默检测,到复杂的多模态信号融合,从被动等待到主动预测,全双工对话系统正在让人机对话变得越来越像人与人之间的自然交流。这不仅是技术的进步,更是对人类交流本质的深入理解和精妙模仿。
版权声明:本文由作者授权上海声网科技有限公司发表。未经许可,不得转载。
本文内容为作者个人观点,仅用于技术交流与分享,不代表上海声网科技有限公司的官方立场或承诺。
如涉嫌侵权,请联系我们:blog@shengwang.cn

