 首页
首页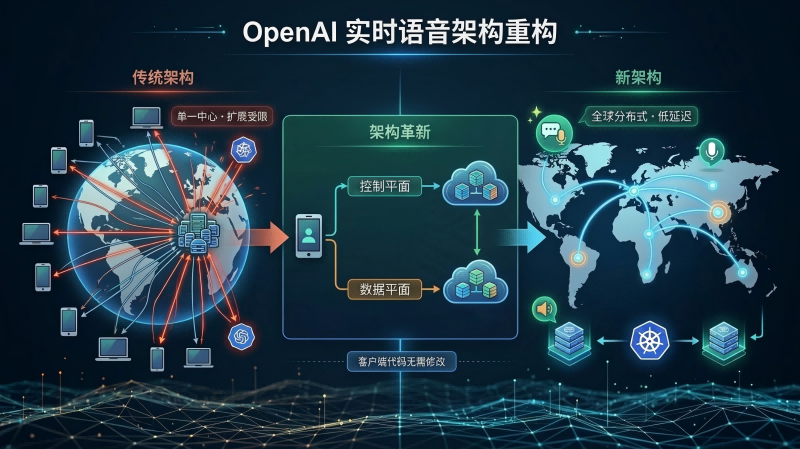
2026 年 5 月初,OpenAI 工程师 Yi Zhang 和 William McDonald 在官方博客发布了一篇罕见的基础设施技术披露,详细介绍了支撑 ChatGPT Voice 和 Realtime API 的 WebRTC 架构重构方案。这是 OpenAI 首次公开实时语音交互的底层技术细节。
当前该架构已全量部署上线,支撑超过 9 亿周活用户的实时媒体流量。重构的核心目标是在不修改客户端代码的前提下,解决传统 WebRTC 架构在大规模场景下的扩容瓶颈,同时降低端到端延迟。
一、为什么要重构WebRTC架构?
OpenAI 博客明确指出,传统WebRTC实践在规模化后遇到了三个相互冲突的约束。
- 第一个约束是传统的「一会话一端口」(one-port-per-session)媒体终止模式。在这种模式下,每个活跃的 WebRTC 会话需要占用一个独立的 UDP 端口。当并发会话数达到数百万级别时,端口资源迅速耗尽,这与 OpenAI 基于 Kubernetes 的基础设施设计产生了根本性冲突。
- 第二个约束是 WebRTC 协议中的有状态会话管理。ICE(Interactive Connectivity Establishment)和 DTLS(Datagram Transport Layer Security)会话都需要稳定的归属关系,不能在运行中随意迁移到其他节点。这在动态扩缩容的云环境中带来了额外的复杂度。
- 第三个约束来自全球化部署。为了保证用户体验,全球各地的用户必须能以最低延迟接入系统,这要求在保持首跳低延迟的同时,还能将流量正确路由到拥有会话状态的节点。
这三个约束在小规模场景下可以共存,但当用户规模达到 9 亿周活时,它们开始相互掣肘,必须从架构层面解决。
二、分离式架构:Relay与Transceiver的职责边界
OpenAI采用的解决方案是将数据包路由与协议终止物理分离,形成「Relay+Transceiver」双层架构。
Relay层:极简的无状态转发
据OpenAI工程博客描述,Relay是一个轻量级的UDP转发层,其职责被严格限定在数据包路由范围内。它不解密媒体流,不运行ICE状态机,也不参与编解码器协商。Relay只读取数据包元数据中足够的信息以选择目标,然后将数据包转发给拥有该会话的Transceiver。
这种设计带来了显著的简化。Relay 持有的信息极其精简:一条内存中的转发映射表,加上少量监控计数器和过期定时器。没有持久化存储,没有协议参与。如果 Relay 实例崩溃重启,下一个数据包到达时就能自动重建路由状态。
Transceiver层:完整的WebRTC端点
Transceiver是有状态的WebRTC端点,拥有完整的协议栈。它负责ICE连通性检测、DTLS握手、SRTP加密解密,以及整个会话的生命周期管理。
Transceiver仍然看到标准的WebRTC流,从客户端角度来看,WebRTC会话没有任何变化。
这种分离设计的价值在于,Relay 可以暴露极小且固定的公网 UDP 端口,而 Transceiver 则运行在 Kubernetes 集群内部,无需直接暴露在公网。这让整套架构能够在 Kubernetes 环境下正常运行,同时也简化了安全策略和负载均衡的实现。
三、首包路由:利用ICE ufrag编码路由信息
分离式架构面临一个关键技术挑战:当用户的第一个数据包到达Relay时,Relay还没有任何关于这个会话的路由信息,如何在不暂停查询外部服务的情况下,将数据包正确转发?
他们利用了 WebRTC 协议本身的一个机制:ICE username fragment,简称 ufrag。这是在 WebRTC 会话建立阶段双方交换的一个短标识符,后续客户端发送的每个 STUN 连通性检查包都会携带这个字段。
OpenAI 的做法是在生成服务端 ufrag 时,将路由所需的元数据编码在其中。Relay 解析 ufrag 即可推断出目标集群和拥有该会话的 Transceiver,无需额外的数据库查询或服务调用。这保证了首包能够确定性投递,避免了热路径上的延迟。
在信令阶段,Transceiver 分配会话状态后,会在 SDP 应答中返回一个共享的 Relay 虚拟 IP(VIP)和 UDP 端口。客户端看到的是单一稳定的目标地址,但实际上背后可能有多个 Relay 实例在处理流量。
四、Global Relay:全球分布式入口
当Relay的公网暴露面缩小到少量固定地址和端口后,OpenAI将这套转发逻辑在全球各地复制部署,形成了「Global Relay」。
这是一组地理分布式的 Relay 入口点,运行相同的数据包转发行为。用户的数据包在离自己最近的入口进入 OpenAI 网络,然后通过内部骨干网到达目标 Transceiver。与直接穿越公网相比,这种方式能够降低延迟、减少抖动、降低丢包率。
信令也采用了地理导向(geo-steering),确保初始连接请求被路由到最近的 Transceiver 集群。
这种组合优化了建立路径和媒体路径,让全球用户都能以较低延迟接入。
五、工程实现:Go语言与Pion WebRTC
Transceiver基于Go语言实现,底层使用开源的Pion WebRTC库。这个选择值得关注,因为Pion在此之前主要被中小型RTC项目采用,OpenAI的9亿周活用户规模验证了开源Go WebRTC栈在大规模生产环境下的可行性。
在性能优化方面,OpenAI 工程师提到了几个关键技术点。
- 首先是 SO_REUSEPORT,这是一个 Linux 套接字选项,允许多个 Relay worker 进程绑定同一个 UDP 端口,由内核负责将数据包分发到不同的 worker,实现了并行处理。
- 其次是线程绑定(thread pinning)。通过将每个 UDP 读取协程固定到特定的操作系统线程上,可以提升缓存局部性,减少上下文切换开销。
- 再者,低分配解析(low-allocation parsing)。在高吞吐场景下,频繁的内存分配会触发垃圾回收,增加延迟抖动。通过预分配缓冲区和复用内存,可以显著降低 GC 压力。
OpenAI 没有使用 DPDK 等内核旁路框架。经过上述优化后,用户态的 Go 实现对于他们的工作负载已经足够。
六、架构价值:Kubernetes兼容与固定暴露面
这次重构带来的收益是多方面的。
首先,整套架构可以运行在Kubernetes上,不需要为每个会话暴露独立的UDP端口。据OpenAI说明,这解决了动态端口范围管理的难题,让WebRTC服务能够像其他无状态服务一样进行调度和扩缩容。
其次,公网暴露面被缩小到少量固定的地址和端口。这不仅简化了安全策略的配置,也让负载均衡变得更加直接。传统方案中,每新增一批会话就需要预留一段端口范围,这在云环境下很难管理。
第三,客户端完全无感知。从 WebRTC 客户端的视角来看,它们仍然在与标准的 WebRTC 端点通信,信令流程、媒体流处理、ICE/DTLS 握手都没有任何变化。这意味着现有的浏览器、移动应用、桌面客户端都能无缝接入,无需任何代码修改。
七、行业意义:开源栈的生产级验证
这次披露有两个值得关注的信号。
- 一是 OpenAI 选择公开基础设施细节。这家公司很少披露底层技术实现,此次主动发布长达数千字的工程博客,说明他们认为这套架构具有行业参考价值,也可能是在为未来更大规模的语音 AI 应用铺路。
- 二是开源技术栈的背书。Pion WebRTC 是社区驱动的纯 Go 实现,在 OpenAI 之前,它更多被用于中小型项目或教学场景。现在,9 亿周活用户和 ChatGPT Voice、Realtime API 这样的生产服务,证明了开源 WebRTC 栈在极端规模下的可靠性。
对于正在构建实时语音 AI 服务的团队,这份官方披露提供了一个真实的工程参考。当然,OpenAI 没有公开所有实现细节,比如 ufrag 的具体编码格式、Relay 的精确转发算法、Transceiver 的定制优化等。但架构思路和核心取舍已经足够清晰。
当语音成为大模型的主要交互方式,传输层的优化不再是可选项。OpenAI 用实践证明,在模型能力趋同的当下,基础设施的深度投入能够带来可感知的用户体验差异。
参考来源
《How OpenAI delivers low-latency voice AI at scale》
原文链接:https://openai.com/index/delivering-low-latency-voice-ai-at-scale/

