 首页
首页如果你最近在关注机器人、AI 硬件或者智能设备赛道,一定已经被这三个词轮番轰炸过:Physical AI、具身智能、具身大模型。它们频繁出现在同一篇报道里,有时候指的像是同一件事,有时候又感觉在说完全不同的东西。本文试图把这三个词放在一起,讲清楚它们各自从哪里来、指向什么,以及在不同语境下该用哪一个。
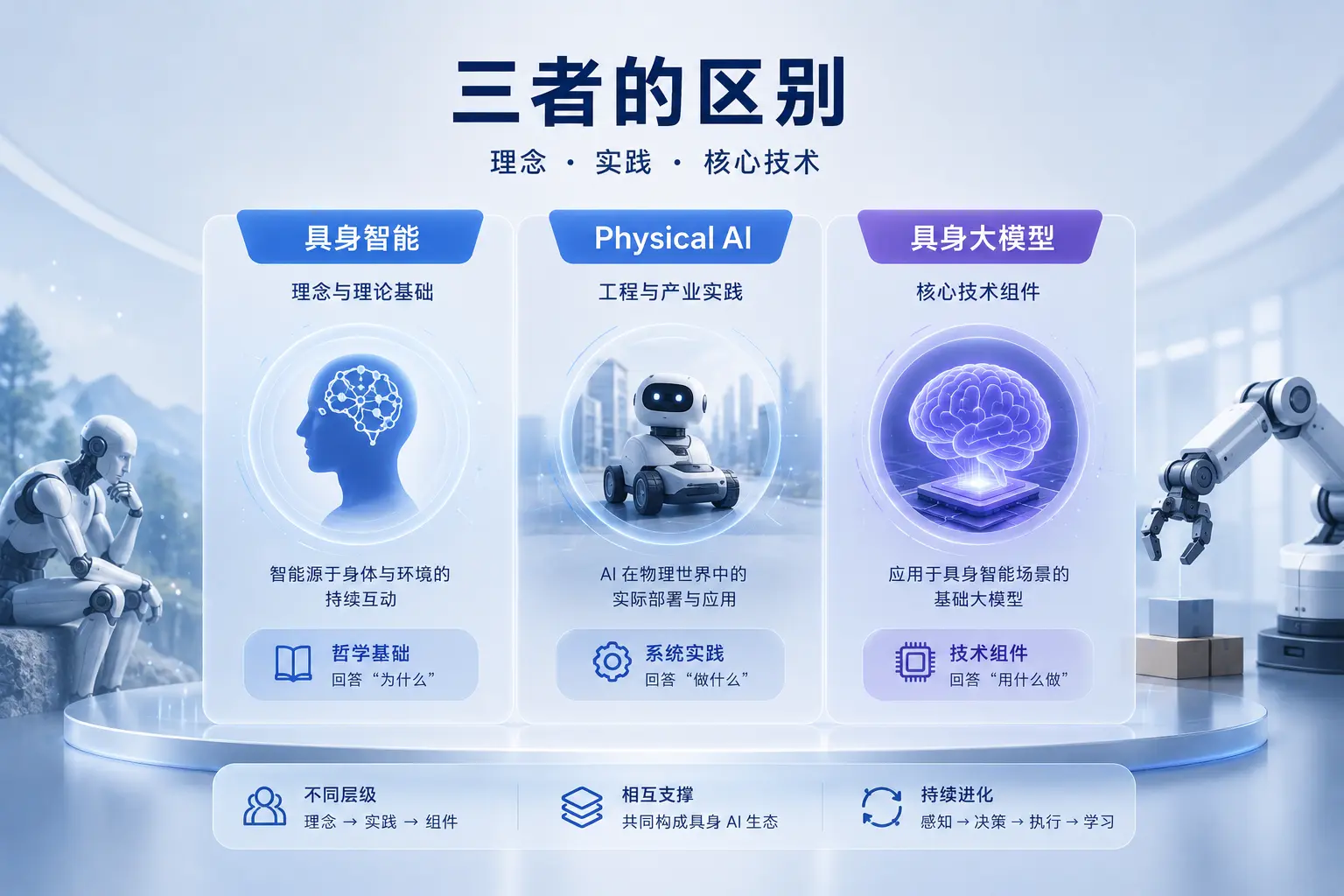
一. 三个词是怎么来的
具身智能:一个 30 年前的学术命题
具身智能(Embodied Intelligence,也译作 Embodied AI)这个概念,最早可以追溯到 1991 年。MIT 机器人学家 Rodney Brooks 在一篇名为《Intelligence Without Representation》的论文里提出:真正的智能不需要先建立世界的内部表征,而是通过身体与环境的直接互动涌现出来的。
这是对当时主流 AI 研究路线的正面挑战——彼时的 AI 研究者普遍相信,智能的核心是符号推理和知识表示,身体只是执行指令的工具。Brooks 的观点反其道而行:没有身体,就没有真正的智能;智能必须在与物理世界的持续互动中生长出来。
这个命题在认知科学、哲学和机器人学里引发了长达十余年的讨论,逐渐形成了”具身认知(Embodied Cognition)”这一研究范式。其核心主张是:智能不是大脑单独计算的结果,而是大脑、身体、环境三者交互的产物。
因此,具身智能从根子上是一个理论命题,关心的是”智能从何而来”这个哲学问题。
Physical AI:英伟达造的产业词
Physical AI 这个说法,真正被大范围传播,是从 2024 年英伟达 CEO 黄仁勋在 CES 上的演讲开始的。他用这个词来描述”能在物理世界中感知、推理和行动的 AI 系统”,并宣布这是继互联网 AI、生成式 AI 之后,下一个 AI 浪潮的核心方向。
这个词本身并不复杂——”物理的 AI”,强调 AI 从数字空间走向物理空间,从处理数据走向作用于真实世界。英伟达随即将自己的机器人基础模型(GR00T)、仿真平台(Isaac Sim)、机器人芯片(Jetson)全部纳入”Physical AI”的叙事框架,使其迅速成为产业界最通行的表述。
与具身智能不同,Physical AI 是一个工程导向的概念,关心的是”怎么做”和”做成什么”,而不是”智能从哪里来”。它更像是一个产品品类的定义,而不是一个学术理论。
具身大模型:一个技术组件的名字
具身大模型(Embodied Foundation Model,或 Embodied Large Model)是随着大模型技术向机器人领域渗透而出现的新词,大约在 2023 年之后开始频繁出现。
它专指为具身智能/Physical AI 场景设计的基础大模型,代表性产品包括:NVIDIA GR00T、Google DeepMind 的 Gemini Robotics、Physical Intelligence(π)的 π0 模型,以及国内的多个机器人基础模型项目。
这类模型的核心能力是将视觉感知、语言理解和动作规划融合在一起,直接输出机器人的运动控制指令,这也是”视觉语言动作模型(VLA)”这个更具体的技术术语的来源。
具身大模型是一个技术组件的名字,不是一个系统,也不是一个哲学命题。它是 Physical AI 系统里”决策层”的核心实现方。
二. 三者的核心差异
把三个词放在同一张表里,差异会更清楚:
| 维度 | 具身智能 | Physical AI | 具身大模型 |
|---|---|---|---|
| 属性 | 理论框架 / 研究范式 | 产品品类 / 产业概念 | 技术组件 / 模型类型 |
| 起源圈子 | 学术界、认知科学 | 工业界、投资圈 | AI 技术社区、工程师 |
| 核心问题 | 智能从何而来? | 如何在物理世界部署 AI? | 机器人的大脑用什么模型? |
| 层级 | 理念层 | 系统层 | 组件层 |
| 典型使用者 | 学者、政策文件、媒体 | CEO、投资人、产品经理 | 算法工程师、机器人开发者 |
| 代表性表述 | “智能需要身体” | “AI 走进物理世界” | “机器人的通用基础模型” |
用一句话把三者的关系说清楚:具身智能是做这件事的哲学依据,Physical AI 是这件事的产业实践,具身大模型是实践中用到的核心技术工具。
三. 三者的关系:不是同一层面的概念
很多混淆来自于把三个不同层面的概念当作同级概念来对比。实际上,它们的关系更像是”为什么做 → 做什么 → 用什么做”。
具身智能:为什么要让机器人有”身体”
具身智能回答的是底层动机:一个只在数字空间里运作的 AI,无法真正理解”重量”、”摩擦”、”空间距离”这些只有通过物理交互才能习得的概念。要做出真正智能的系统,身体不是可选项,而是必要条件。
这个理念指导了整个 Physical AI 产业的技术路线选择——比如,为什么要用真实机器人采集训练数据(而不是纯仿真数据),为什么要在真实环境里做在线学习,为什么”世界模型”的研究被认为至关重要。
Physical AI:做什么样的系统
Physical AI 是具身智能理念的工程化落地,定义了这类系统应该具备的能力:感知物理环境、在其中自主行动、从交互中持续学习。它是一个产品系统的描述,覆盖了从传感器、执行器、通信网络到云端推理的完整技术栈。如果想了解这套技术架构的详细拆解,参见《什么是 Physical AI?底层技术逻辑、应用场景和商业价值》的“底层技术逻辑”章节。
一个工厂里的 AI 分拣机器人、一台家用陪伴机器人、一辆自动驾驶汽车,都可以被称为 Physical AI 系统,它们的共同点是 AI 的输出直接作用于物理世界。
具身大模型:用什么来驱动决策
在 Physical AI 系统的技术架构里,具身大模型承担的是”决策层”的职责——理解感知数据、规划行动方案、输出控制指令。它是整个系统里最”烧钱”、竞争最激烈的技术环节,NVIDIA、Google、Figure AI、宇树科技等公司都在这一层上重金押注。
但具身大模型只是 Physical AI 系统的一个组成部分,一个完整的 Physical AI 系统还需要传感器融合、实时通信、执行控制、安全监控等多个技术模块的协同配合,才能正常运转。
四. 不同语境下该用哪个词
理解了三者的层级关系,在不同场合选词就有了依据。
写政策文件、学术报告、政府白皮书
用具身智能。这是中文政策语境里最通行的表述,《政府工作报告》《”人工智能+”行动计划》均使用此词。它的学术渊源赋予了它一定的严肃性,适合需要权威感的正式文件。
做产品介绍、融资 PPT、市场传播
用Physical AI。这是当前国际产业界最通行、最容易被投资人和科技媒体理解的表述,能够快速建立”这是下一个大方向”的认知。英伟达的背书让这个词在全球科技圈拥有很高的辨识度。
讨论技术选型、模型架构、算法路线
用具身大模型或更具体的 VLA 模型。在工程师和算法研究者的讨论里,”具身大模型”比前两个词更精确,能直接指向”我们在讨论哪个技术组件”,避免在概念层面绕圈子。
面向普通用户、消费者、非技术媒体
三个词都尽量少用,改用具体的场景描述。”一台能看懂你手势、听懂你说话、走过来递东西给你的机器人”,比术语都更容易理解。
五. 三个常见的混用误区
误区一:把”具身智能”当 Physical AI 的中文翻译
这是最普遍的混用。很多中文报道直接把 Physical AI 翻译成”具身智能”,但两者并不完全对等。Physical AI 的外延更广——一台能在物理世界执行任务的 AI 系统,即便它的设计者完全不了解具身认知理论,也可以叫 Physical AI。而具身智能强调的是”智能通过身体与环境互动涌现”这一理论主张,侧重点在学习机制而不是部署形态。
更准确的对应关系是:Physical AI ≈ 实体 AI / 物理 AI;具身智能 ≈ Embodied Intelligence / Embodied AI。但由于这两个词在实际使用中高度重叠,在非学术场合混用通常不会造成严重问题。
误区二:以为有了具身大模型就有了 Physical AI
这是工程师圈子里常见的误区。具身大模型再强大,也只是 Physical AI 系统的决策层。一个能输出完美运动控制指令的 VLA 模型,如果通信层延迟过高导致指令无法实时下发,或者感知层噪声过大导致输入数据失真,整个系统照样无法正常工作。
Physical AI 是一个系统工程问题,具身大模型是其中最受关注的组件,但不是全部。
误区三:认为”具身智能”一定需要人形机器人
人形机器人是当下最受关注的 Physical AI 形态,但不是唯一形态。一台安装在工厂流水线旁的 AI 视觉质检系统、一个能够自主导航的仓储 AGV、一套会根据学生反应调整教学节奏的桌面 AI 教育设备,都可以属于 Physical AI 或具身智能的范畴。具身智能的核心不是”像不像人”,而是”有没有通过身体与物理世界产生真实互动”。
六. 三个词的未来走向
这三个词的使用边界,会随着产业发展而继续演化。
具身智能在中国会持续被政策文件和主流媒体使用,并逐渐从学术圈渗透到大众语汇,成为”AI 机器人”的高级替代说法。
Physical AI 将随着英伟达和全球科技巨头的持续投入,在国际产业语境里占据主导地位。国内也会有越来越多的企业和媒体直接使用这个英文词,而不做翻译。
具身大模型作为技术术语,会随着这一领域的技术竞争加剧而被使用得越来越精细——从”具身大模型”细分到”VLA 模型”、”世界模型”、”运动基础模型”等更具体的分类,就像 NLP 领域从”语言模型”细分到”指令微调模型”、”RLHF 模型”的过程一样。
对于开发者和产品团队来说,最实用的建议是:在对外传播里用 Physical AI,在政策沟通里用具身智能,在技术讨论里用具身大模型或 VLA。
七. 三个词的共同前提:实时通信
无论叫具身智能、Physical AI,还是具身大模型驱动的机器人系统,有一个底层需求是所有这些系统共享的:实时、低延迟的数据传输能力。
感知数据要实时上传,推理结果要实时下发,语音交互要毫秒级响应,遥操作要近乎零延迟的双向同步。”具身智能”机器人和”Physical AI”机器人,在通信层面临的挑战是完全相同的。
声网基于超过十年的实时音视频通信技术积累,为 Physical AI 系统提供从端侧语音交互到云端数据回传的完整通信基础设施。2026 年 1 月,声网联合博通集成发布的 R2 全场景 AI 机器人开发套件,正是将实时通信能力与本地视觉感知、多自由度运动控制融合在一起的完整方案。如果你正在这个方向上构建产品,欢迎了解声网对话式 AI 开发套件的详细方案。


