 首页
首页2024 年,当英伟达 CEO 黄仁勋在 CES 舞台上宣布”Physical AI 时代已经到来”,整个科技行业的目光迅速聚焦到这个词上。2025 年,具身智能被写入中国《政府工作报告》,成为国家战略级别的技术方向。到 2026 年,工厂里的机械臂开始能够理解口头指令、自主规划操作步骤;街道上的服务机器人能够识别行人情绪、主动发起对话;儿童卧室里的 AI 玩具能够记住孩子的偏好,每天讲不重样的故事。
Physical AI,正在从实验室走进真实世界。
但对于大多数开发者和产品经理来说,Physical AI 仍然是一个边界模糊的概念。它和机器人有什么区别?和具身智能是同一回事吗?和我们熟悉的 ChatGPT、Sora 这类 AI 又有什么本质不同?为什么它对延迟的要求比任何一种 AI 应用都要苛刻?本文将从定义出发,系统拆解 Physical AI 的底层逻辑、技术架构、应用场景、商业价值与核心痛点,帮你建立一张完整的认知地图。
一. Physical AI 是什么
一句话定义:Physical AI 是能够感知物理世界、在其中行动,并从中持续学习的人工智能系统。
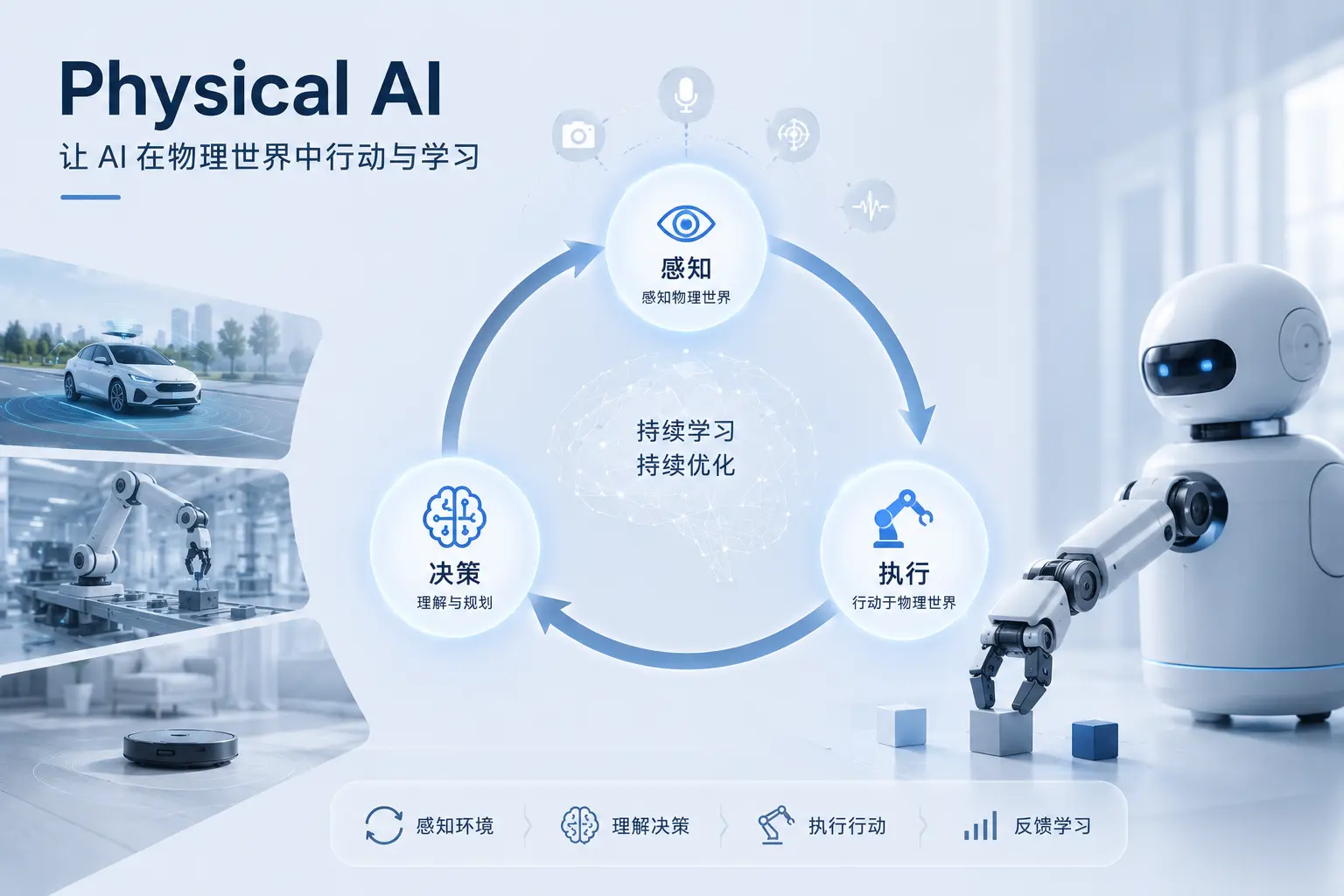
不同于运行在服务器上、处理文字和图片的传统 AI,Physical AI 拥有一个”身体”,可以是机械臂、移动机器人、智能设备,甚至是自动驾驶汽车。它通过传感器感知真实环境,通过执行器作用于物理世界,并在这个过程中不断积累经验、优化自身行为。
一个聊天机器人说错了话,用户最多感到失望;一台 Physical AI 驱动的手术机器人判断失误,后果则是不可逆的物理损伤。这种”行动有代价”的特性,是 Physical AI 区别于一切数字 AI 最根本的地方。
Physical AI 的三个核心要素
Physical AI 系统的运行依赖三个不可缺少的环节,形成一个持续循环的闭环:
- 感知(Perception):通过摄像头、麦克风、力觉传感器、激光雷达等多模态传感器,实时采集物理世界的状态信息。这是 Physical AI 与现实世界建立连接的第一步,也是决策质量的上限所在——感知不准,后续一切都会失真。
- 决策(Reasoning):将感知到的信息输入 AI 模型,理解当前环境、预测下一步变化、规划最优行动方案。这一步的核心是”理解”而不是”查表执行”——传统机器人按程序走,Physical AI 按理解走。
- 执行(Action):将决策结果转化为具体的物理动作,驱动机械结构完成操作。关键在于,执行必须足够快——物理世界不会暂停等待 AI 思考,任何超出容忍范围的延迟都会让系统失控或让用户体验崩坏。
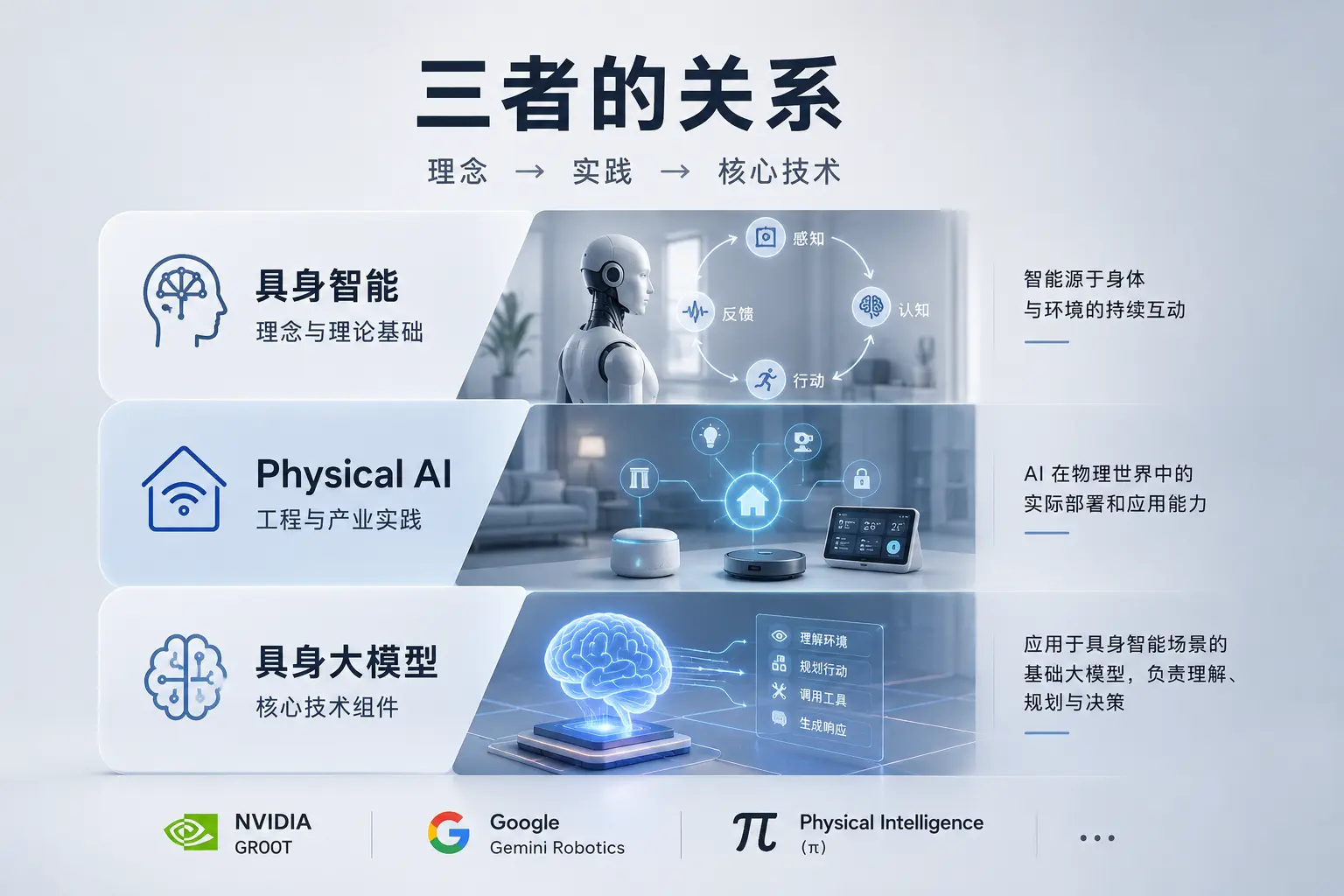
Physical AI、具身智能、具身大模型:三者有什么区别?
这三个词在行业内频繁混用,但含义有所侧重,厘清它们有助于在沟通中避免误解:
- 具身智能(Embodied Intelligence / Embodied AI):更偏学术,强调”智能必须通过身体与环境的互动才能真正涌现”这一理论主张。这个概念源自 1991 年 MIT 机器人学家 Rodney Brooks 的经典论文,是 Physical AI 的哲学与理论基础。
- Physical AI:更偏工程和产业,强调 AI 在物理世界中的实际部署和应用能力。这是当前产业界、投资圈和政策文件中最常用的表述,尤其在英伟达将其定义为下一个 AI 浪潮之后,使用频率迅速攀升。
- 具身大模型:专指应用于具身智能场景的基础大模型,如 NVIDIA GR00T、Google Gemini Robotics、Physical Intelligence(π)等,是 Physical AI 系统的”大脑”组件之一,负责感知理解与行动规划。
三者的关系可以这样理解:具身智能是理念,Physical AI 是实践,具身大模型是其中的核心技术组件。
二. Physical AI 与传统软件 AI 的本质区别
理解 Physical AI,最直接的方式是把它和我们已经熟悉的传统软件 AI 放在一起比较。
传统软件 AI:无论是大语言模型、图像识别算法,还是推荐系统,都运行在一个”干净”、”可控”、”可回退”的数字环境中。输入是数据,输出是数据,错了可以重试,慢了最多降低用户体验。
Physical AI 则完全不同。它面对的是嘈杂、动态、不可预测的物理世界,它的输出是真实的物理动作,错误不可撤销,延迟直接影响安全与体验。
| 对比维度 | 传统软件 AI | Physical AI |
|---|---|---|
| 作用对象 | 数字数据与信息 | 物理世界与实体对象 |
| 输出结果 | 文字、图片、预测值、分类标签 | 物理动作、移动轨迹、操作力度 |
| 错误代价 | 可撤销、可重试,代价低 | 可能造成物理损伤,不可逆 |
| 对延迟的敏感度 | 低,秒级响应通常可接受 | 极高,毫秒级要求,超时即失控 |
| 运行环境 | 稳定、结构化的数字环境 | 嘈杂、动态、不可预测的物理环境 |
| 学习方式 | 以离线数据集训练为主 | 需要在真实物理环境中持续交互学习 |
这张表中,延迟敏感度是最容易被低估的差异。延迟,是 Physical AI 产品体验的真正底线。这也正是 Physical AI 系统对底层通信基础设施提出极高要求的根本原因。
三. 底层技术逻辑
Physical AI 不是单一技术,而是多个技术层的协同系统。要真正理解它的运作方式,需要自底向上拆解每一层的职责与挑战。
感知层:多模态传感器融合
Physical AI 的”眼睛、耳朵和皮肤”由多种传感器构成:
- 视觉:RGB 摄像头、深度摄像头(如 Intel RealSense)、立体视觉系统,用于物体识别、空间定位和场景理解
- 听觉:麦克风阵列,用于语音识别、声源定位和环境噪声过滤
- 力觉与触觉:六维力/力矩传感器、压力传感器,用于精细操作时的力度控制
- 空间感知:激光雷达(LiDAR)、IMU 惯性测量单元,用于定位导航和动态避障
感知层的核心挑战在于多模态融合。如何将来自不同传感器、不同频率、不同格式的数据实时对齐,形成对当前物理状态的统一、准确认知。这是当前 Physical AI 系统最容易出错的环节之一。
决策层:视觉语言动作模型(VLA)与世界模型
决策层是 Physical AI 的”大脑”,负责理解感知数据并生成行动方案。当前最主流的技术路线是视觉语言动作模型(Vision-Language-Action Model,VLA)。
VLA 模型将大语言模型的语言理解能力与视觉感知能力、运动控制能力融合在一起。简单来说,它能够同时”看懂”摄像头拍到的画面、”听懂”用户的语音指令,并直接输出机器人的运动控制指令,而不需要人工编写每一个操作规则。
代表性模型包括:
- NVIDIA GR00T N1.6:专为人形机器人设计的开放基础模型,2026 年 1 月更新
- Google Gemini Robotics:谷歌 DeepMind 推出的机器人 AI 模型,具备强大的泛化能力
- Physical Intelligence π:专注于通用机器人操作能力的基础模型
与 VLA 模型紧密相关的是世界模型(World Model)的概念。世界模型让 AI 在内部构建一个对物理环境如何运作的”仿真”——比如预测”如果我向左推这个物体,它会滑向哪里”。有了世界模型,Physical AI 可以在执行前进行内部推演,大幅降低试错成本。
执行层:从决策到动作的实时下发
执行层负责将决策层输出的行动指令转化为电机驱动信号,控制机械结构完成具体操作。这一层的关键问题是端到端延迟:从传感器采集到电机响应,整个链路的时间消耗必须控制在场景允许的范围内。
不同场景对延迟的容忍度差异极大:
- 语音对话交互:< 200ms,超过此值用户明显感受到”卡顿”
- 机器人遥操作:< 50ms,延迟会导致操作失控
- 手术机器人辅助:< 10ms,任何延迟都可能危及生命安全
通信层:Physical AI 最容易被忽视的关键基础设施
在感知、决策、执行三层之外,还有一层至关重要却常常被忽视的基础设施——实时通信层。
Physical AI 系统中,大量计算是在云端或边缘服务器完成的,推理结果需要通过网络实时传输回设备端执行。与此同时,设备端采集的音视频数据也需要实时上传供模型处理。这一双向的实时数据流,对通信链路的延迟、稳定性和抗弱网能力提出了极高要求。
如果通信层不稳定,即便感知再准确、模型再聪明,最终的用户体验也会因为”传不到”或”传太慢”而彻底崩坏。这正是专业实时音视频通信基础设施(RTC)在 Physical AI 系统中不可替代的原因。
四. 主要应用场景
Physical AI 的应用场景已经从实验室延伸到多个真实行业,成熟度和商业化进展因场景而异。
工业与仓储:最成熟的商业化场景
在工厂和仓库中,Physical AI 驱动的机器人正在承担分拣、搬运、质检等高重复性工作。这也是目前商业化落地最成熟的场景——亚马逊仓储机器人 Sparrow 对已训练物体类别的分拣成功率已达 95%~99%。Physical AI 在此场景的价值是降本增效:相比人工,机器人可以 24 小时不间断运转,且不会因疲劳产生失误。
服务与陪伴:情感价值驱动的新场景
AI 陪伴机器人是 Physical AI 近年来增长最快的消费级场景之一。这类机器人不需要完成复杂的物理操作,但对语音交互的自然度和实时性要求极高——用户期望的是”像在和一个有温度的朋友对话”,而不是和一台机器交流。面向老人和儿童的陪护机器人、情感支持设备,正在这一逻辑下快速进入市场。
教育:AI 互动玩具与 STEM 学习机器人
教育是 Physical AI 最接近普通消费者的场景。AI 互动玩具可以识别儿童的语音、记忆偏好、自适应调整内容难度,在陪伴中完成个性化学习。相比传统的点读机和早教平板,Physical AI 玩具引入了双向的、有情境的真实交互,学习效果和用户黏性均显著提升。
医疗:高精度、高安全要求场景
医疗是 Physical AI 应用门槛最高、但潜力也最大的场景。手术辅助机器人可以在医生的远程操控下完成毫米级精度的操作;康复训练机器人可以根据患者实时的力反馈动态调整训练强度;医院巡检机器人可以自主完成病区环境监控和药品配送。这一场景对延迟、安全性和可靠性的要求达到了所有场景中最高的级别。
消费电子:智能家居与语音交互硬件
智能音箱、家用服务机器人、AI 宠物设备等消费电子产品,是 Physical AI 渗透最广泛的品类。这些设备通过语音和视觉与用户互动,承担家庭环境感知、日程提醒、娱乐陪伴等功能。随着大模型能力的下沉,这类设备正在从”执行指令”向”主动理解用户意图”进化。
人形机器人:通用场景的终极探索
人形机器人是 Physical AI 最前沿、也最受资本关注的方向。Figure AI、波士顿动力、宇树科技、智元机器人等公司正在竞速推进人形机器人的商业化。人形机器人的目标是打造一台能够适应任何人类生活和工作场景的通用机器人——无需为特定任务单独设计机械结构,依靠 AI 能力泛化到新任务。这一目标目前仍处于早期探索阶段,但 2026 年已有多款产品进入小规模工厂部署。
五. 商业价值
Physical AI 的商业价值体现在多个层面,从市场规模到具体的降本逻辑,都在快速清晰化。
市场规模:高速增长的千亿赛道
根据行业研究机构数据,全球具身智能市场规模在 2025 年达到约 440 亿元人民币,预计到 2030 年将超过 1600 亿元,年复合增长率约 39%。其中,工业自动化和仓储物流是当前最大的收入来源,消费级陪伴与教育场景则是增速最快的细分方向。
中国市场尤为值得关注:具身智能已被列入《”人工智能+”行动计划》重点发展方向,多个省市出台专项政策支持人形机器人和 Physical AI 的研发与量产。
降本逻辑:替代重复性人工
对企业客户而言,Physical AI 最直接的商业价值是替代高重复性、高体力消耗的人工岗位。工厂分拣、仓库搬运、商超盘点、安保巡逻——这些工作的共同特点是高频、低创造性、对人体有一定损耗。Physical AI 机器人可以 24 小时不间断工作,不受情绪和疲劳影响,单次部署后的边际成本极低。
溢价逻辑:情感价值与个性化服务
在消费端,Physical AI 的商业价值不在于”更便宜”,而在于”更有价值”。一台能够识别孩子情绪、记住孩子喜好、每天讲不重样故事的 AI 玩具,其用户付费意愿远高于功能固定的传统玩具。情感陪伴、个性化教育、主动式健康管理——这些场景的溢价空间,是 Physical AI 消费级市场最核心的商业逻辑。
国家战略层面:政策红利加速落地
Physical AI 不仅是产业机会,也是国家战略布局的重点。中国将具身智能和人形机器人纳入新质生产力的核心方向,美国则通过 NVIDIA、Google、Figure AI 等企业在全球竞争中建立先发优势。对于开发者和企业来说,这意味着政府采购、研发补贴和产业园区配套等政策红利将持续释放。
六. 当前核心痛点
尽管 Physical AI 前景广阔,但当前的落地过程中仍面临多个尚未被完全解决的核心痛点。理解这些痛点,是做好 Physical AI 产品和系统架构的前提。
延迟痛点:推理链路长,端到端响应慢
Physical AI 系统的典型推理链路是:传感器采集 → 数据上传 → 云端/边缘推理 → 结果下发 → 执行动作。每一个环节都会引入延迟,叠加起来后端到端的响应时间往往难以控制在理想范围内。对于语音交互类应用,超过 300ms 的延迟就会让用户明显感受到不自然;对于遥操作类应用,超过 50ms 的延迟会直接影响操控精度和安全性。
感知痛点:复杂环境下多模态融合难度大
真实物理环境远比实验室复杂:光线变化、背景噪声、遮挡、反光——这些都会显著降低感知层的准确性。如何在复杂、动态的真实场景下保持稳定的多模态感知能力,是当前 Physical AI 系统最主要的技术瓶颈之一。模型在训练环境下表现良好,但到了真实部署环境就出现性能下降,是这一领域普遍存在的挑战。
部署痛点:硬件成本高,量产落地难
一台具备完整 Physical AI 能力的机器人,所需的传感器、芯片、执行器和结构件成本目前仍然较高。以人形机器人为例,主流产品的单台成本目前仍在数十万元人民币级别。量产能力的建立、供应链的稳定性、售后维护体系的构建——这些工程化挑战是 Physical AI 从”展示样机”走向”规模商用”必须跨越的门槛。
交互痛点:自然对话连贯性不足
对于需要语音交互的 Physical AI 设备,当前面临的核心体验问题是:在嘈杂环境下语音识别准确率下降、多轮对话的上下文记忆能力有限、以及打断/插话场景的处理不自然。用户期望与机器人的对话如同与人交流,但当前的技术实现离这个目标仍有明显差距。
通信痛点:现有方案延迟高、弱网稳定性差
许多 Physical AI 设备直接采用传统 IoT 通信协议(如 MQTT)或普通 HTTP/WebSocket 进行数据传输。这类方案在实验室的稳定网络环境下表现尚可,但一旦进入弱网、高延迟或网络抖动的真实使用场景,往往会出现语音断续、指令丢失、画面卡顿等严重影响体验的问题。对于以实时交互为核心价值的 Physical AI 产品,通信层的稳定性和低延迟能力是产品体验的底线,也是当前行业普遍面临的难题。
七. 声网能解决什么
在 Physical AI 系统的四层架构中——感知、决策、执行、通信,前三层有 NVIDIA、Google、各大机器人厂商在密集投入,而通信层长期是被忽视的”基础设施盲区”。
声网在实时音视频通信领域深耕超过十年,在全球部署了覆盖 200+ 国家和地区的低延迟实时通信网络。这套基础设施,正在成为 Physical AI 系统的通信层解决方案。
设想这样一个场景:一台家用陪伴机器人,用户问了一句”今天天气怎么样”,机器人沉默了将近半秒,才开口回答。用户的第一反应不是”AI 在思考”,而是”这机器人是不是坏了”。300ms,是语音交互体验的生死线。
声网的 对话式AI 专为 Physical AI 设备设计,将声网的实时通信能力与端侧 AI 推理能力深度融合,提供从麦克风采集、降噪处理、实时传输、ASR 识别、大模型推理到 TTS 播报的完整链路方案。在标准网络环境下,端到端语音交互延迟可控制在 100ms 以内;在弱网和高丢包环境下,声网的自适应码率和抗丢包算法也能保持流畅的对话体验。
已有Physical AI 团队基于声网的方案完成了商业落地:
- 陆吾智能”陆卡卡”:声网联合博通集成在 CES 2026 发布的 R2 全场景 AI 机器人开发套件的标杆产品。陆卡卡搭载本地视觉识别能力,可实现人脸跟踪、手势识别、物体跟随,并结合多自由度运动控制,做到”转头注视说话者”、”走向用户主动打招呼”,感知、决策、物理动作三个环节在设备本地完成闭环,是声网 Physical AI 落地的典型案例。
- Sentino AI 占率合作:声网兄弟公司Agora与 Sentino 于 2026 年 1 月联合发布面向 Physical AI 的 AI Agent 平台,基于声网对话式 AI 引擎构建。平台让 AI Agent 具备跨会话的长期记忆、情感感知与个性化表达能力。
如果你正在开发 Physical AI 产品,并且希望在通信层少走弯路,欢迎了解声网对话式 AI 的详细方案。


