首页
首页想象一下这个场景:在一个跨国协作的线上会议中,屏幕下方滚动着精准的实时转录翻译字幕。突然,两三个参会者为了某个战略项目讨论了起来,语速极快且伴随抢话。
如果此时的字幕只是机械地吐出文字,而没有标注姓名,作为旁听者或稍后回看纪要的决策者,你根本分不清哪句是研发经理的技术坚持,哪句是销售经理的客户需求。这种文字的堆砌,我们称之为“身份迷思”。
在声网的实时转录翻译产品中,说话人标签(Speaker Labeling)不仅是一个功能开关,它是将非结构化语音转化为结构化数据的关键钥匙。
1. 什么是说话人标签?为什么它在实时场景下这么难?
从技术定义上讲,说话人标签(又称 Diarization)解决的是“Who spoke when(谁在什么时候说了什么)”的问题。
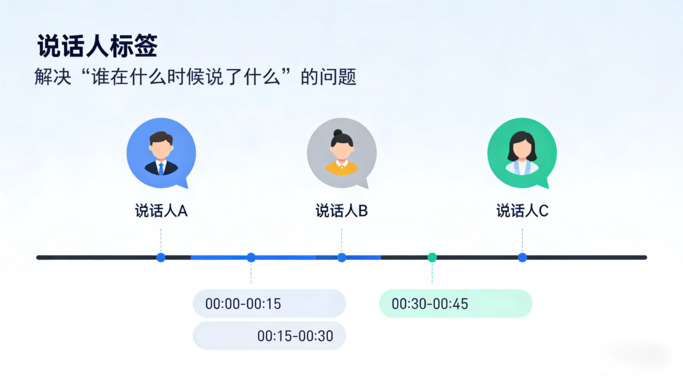
在传统的离线录音转写中,这相对容易。算法可以反复扫描一段音频,提取声纹特征,然后进行聚类。但在实时转录翻译的动态场景下,开发者面临的是三重挑战:
- 低延时的枷锁: 你不能等一段话讲完 5 秒后再去分析是谁说的。字幕必须随音轨流出,这意味着身份识别必须在毫秒级完成。
- 交叉对话(Cross-talk): 在激烈的讨论中,两个音频信号是重叠的。传统的单声道转录会将两个人的声音混在一起,导致识别率断崖式下跌。
- 声纹漂移: 不同的麦克风设备、不同的网络带宽,甚至用户感冒后的嗓音变化,都会干扰纯算法驱动的声纹识别。
2. 声网的解法:原生音轨隔离 vs. 纯声纹算法
在多说话人场景下,实时转录翻译通常面临两个核心问题:
- 如何区分“谁在说话”
- 如何保证字幕与音视频内容精准对齐
声网的实时转录翻译能力,基于实时音视频系统的用户级音频结构进行设计,在多人互动场景中具备天然优势。
2.1 基于 UID 的说话人标注能力
在声网的实时音视频系统中,每个加入频道的用户都会分配唯一的 UID。实时转录翻译服务可以结合频道内的用户信息,对转录结果进行说话人标注(Speaker Labeling),并支持按用户维度获取转录结果。
这意味着,在多人连麦、会议或社交场景中,转录文本可以明确标识发言者身份,而不需要事后再对混合音频进行复杂的说话人分离处理。
通过将转录结果与用户 UID 进行关联,开发者可以更方便地实现:
- “谁说了什么”的文本归因
- 会议纪要结构化整理
- 多主播场景下的字幕区分
这种基于频道结构的说话人标注能力,是实时互动场景下的重要基础能力。
2.2 基于时间戳的字幕对齐
在解决“谁在说”的问题之后,还需要保证“何时说”的准确性。
声网实时转录服务以流式方式返回识别结果,并为转录文本附带时间戳信息。开发者可以利用这些时间信息,将字幕与音视频内容进行对齐,用于直播字幕展示、回放生成或点播复用。
通过时间戳机制,字幕能够在时间轴上与语音内容保持一致,提升整体观看体验与可读性。
3. 说话人标注在核心场景中的实际价值
在多人实时互动场景中,转录的价值不仅在于“文字化”,更在于“可归因”。说话人标注能力能够将转录文本与具体用户身份进行关联,从而提升整体可用性。
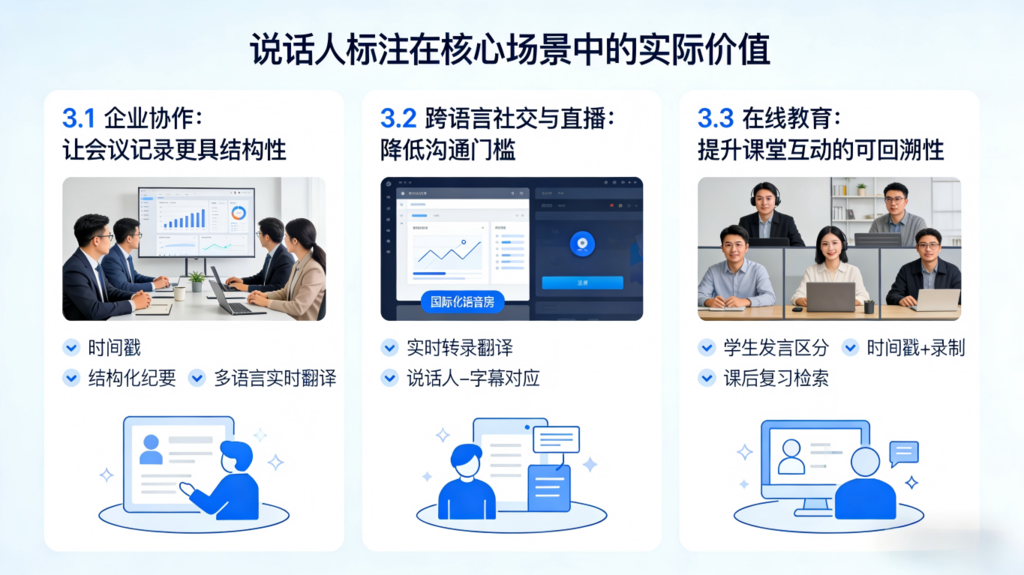
3.1 企业协作:让会议记录更具结构性
在跨部门或跨国会议中,说话人标注可以清晰区分不同角色的发言内容。结合时间戳信息,开发者可以在会后生成结构化会议纪要,或进一步对接上层业务系统进行整理与归档。
在多语言会议场景中,实时翻译能力能够帮助不同语言背景的成员同步理解讨论内容。
3.2 跨语言社交与直播:降低沟通门槛
在国际化语音房或跨区域直播互动中,实时转录与翻译可以帮助不同语言背景的用户进行交流。说话人标注则确保字幕与发言者对应,避免内容混淆。
3.3 在线教育:提升课堂互动的可回溯性
在多人连麦课堂中,说话人标注可以帮助教师区分学生发言。结合时间戳与录制能力,转录结果可用于课后复习或知识点检索,增强学习体验。
4. 如何评估 Diarization 的能力?
在评估实时转录翻译方案时,建议从以下几个维度进行考察:
4.1 多说话人场景下的稳定性
当频道中存在多名用户同时在线甚至交替发言时,系统是否仍能保持稳定的说话人标注能力?
服务商是否支持基于用户身份的转录结果区分,而不是依赖事后混音分离?
4.2 实时延时表现
从语音发出,到带说话人标签的转录文本展示在终端屏幕上,中间的处理延时是多少?
跨区域网络环境下,系统是否依托全球实时传输网络来保障整体链路的稳定性与可预测性?
4.3 接口与集成复杂度
开发者在接入转录服务时:
- 是否可以直接获取带说话人信息的结构化转录结果?
- 是否需要自行维护复杂的身份映射逻辑?
- 整体集成流程是否与现有实时音视频架构保持一致?
接口抽象能力的成熟度,往往决定了后期维护成本。
结语
实时转录翻译不应该只是冰单的文字流动。通过说话人标签,我们赋予了这些文字以身份、立场和逻辑。
在声网实时转录翻译架构中,转录由云端实时完成,并支持说话人标注(Speaker Labeling)。系统在返回转录结果时会附带对应的用户 UID,从而在多人互动场景中实现“谁说了什么”的清晰区分。结合时间戳信息,转录文本可以进一步用于字幕展示、检索或结构化处理。
准备好为你的产品实时转录翻译服务了吗? 点击这里 申请体验资格。
下一篇预告: 当准确的、带身份标签的文本流实时产生后,我们该如何发挥它的最大价值?
下一篇我们将探讨:《转录只是开始:如何将实时翻译文本接入 LLM 生成会议纪要与课程总结?》。