 首页
首页当简洁的代码掩盖了效率低下的问题:我们从修复几行代码并节省 90% 的 LLM 成本中学到了什么。

你知道那种感觉吗?——表面上一切运行良好,但当你掀开盖子一看,才发现系统其实在耗费着本该用量十倍的燃料。
我们有一个客户端脚本,用来发送请求验证我们的提示词(prompts)。这个脚本是用异步 Python 代码编写的,在 Jupyter notebook 中运行得非常顺畅——干净、简单、快速。我们定期运行它,用于测试模型并收集评估数据。没有任何警示。没有报错。看起来一切都很正常。
但在那光鲜的表面之下,有些事情正在悄悄出错。
我们没有看到失败的请求,也没有遇到异常,甚至没有感觉到变慢。然而,我们的系统在做着远超所需的工作,而我们全然不觉。
在这篇文章中,我们将一步步讲述我们是如何发现这个问题的,根源在哪里,以及我们如何通过调整的异步代码结构,让 LLM 流量和成本减少了 90%,且几乎没有损失任何速度或功能。
当然,提前声明:读完这篇文章并不会神奇地让你的 LLM 成本立刻降低 90%。但它的启示更广——那些看似微不足道的设计决策,有时候只是一两行代码的差别,就可能造成巨大的效率损失。而如果我们能更有意识地思考代码的运行方式,长期来看就能节省时间、金钱和精力。
这个修复方法一开始看起来似乎很小众。它涉及 Python 异步机制的一些细节——任务是如何被调度、派发的。如果你熟悉 Python 和 async/await,你会更容易理解代码示例;但即便不是,也依然能从中获得启发。因为这篇文章真正的主题,并不仅仅是关于 LLM 或 Python,而是关于负责任且高效的工程实践。
让我们开始吧。
设置阶段(The Setup)
为了实现自动化验证,我们使用一个预定义的数据集,并通过客户端脚本触发系统。验证只针对数据集中的一个小子集进行,因此客户端代码会在收到一定数量的响应后才停止运行。
下面是一个简化版的 Python 客户端示例:
import asyncio
from aiohttp import ClientSession
from tqdm.asyncio import tqdm_asyncio
URL = "http://localhost:8000/example"
NUMBER_OF_REQUESTS = 100
STOP_AFTER = 10
async def fetch(session: ClientSession, url: str) -> bool:
async with session.get(url) as response:
body = await response.json()
return body["value"]
async def main():
results = []
async with ClientSession() as session:
tasks = [fetch(session, URL) for _ in range(NUMBER_OF_REQUESTS)]
for future in tqdm_asyncio.as_completed(tasks, total=NUMBER_OF_REQUESTS, desc="Fetching"):
response = await future
if response is True:
results.append(response)
if len(results) >= STOP_AFTER:
print(f"\n✅ Stopped after receiving {STOP_AFTER} true responses.")
break
asyncio.run(main())这个脚本会从数据集中读取请求、并发发送,一旦收集到足够数量的有效响应(true responses)用于评估,就会停止运行。
在生产环境中,逻辑会更复杂一些——它取决于我们所需响应的多样性,但整体结构是一样的。
下面我们用一个 模拟的 FastAPI 服务器(dummy FastAPI server) 来复现真实的运行行为:
import asyncio
import fastapi
import uvicorn
import random
app = fastapi.FastAPI()
@app.get("/example")
async def example():
sleeping_time = random.uniform(1, 2)
await asyncio.sleep(sleeping_time)
return {"value": random.choice([True, False])}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)现在我们启动这个虚拟服务器并运行客户端。你会在客户端终端看到类似这样的信息:

进度条在收到10个回复后停止了
你能发现问题所在吗?

不错!速度快、运行流畅,而且……等等,一切都按预期运行吗?
表面上看,客户端似乎在做正确的事情:发送请求,收到 10 个有效响应,然后停止。
但事实真是如此吗?
让我们在服务器上添加一些打印语句,看看它在底层实际执行了哪些操作:
import asyncio
import fastapi
import uvicorn
import random
app = fastapi.FastAPI()
@app.get("/example")
async def example():
print("Got a request")
sleeping_time = random.uniform(1, 2)
print(f"Sleeping for {sleeping_time:.2f} seconds")
await asyncio.sleep(sleeping_time)
value = random.choice([True, False])
print(f"Returning value: {value}")
return {"value": value}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0", port=8000)现在重新运行所有程序。
你会开始看到类似这样的日志:
Got a request
Sleeping for 1.11 seconds
Got a request
Sleeping for 1.29 seconds
Got a request
Sleeping for 1.98 seconds
...
Returning value: True
Returning value: False
Returning value: False仔细查看服务器日志。你会发现一些意想不到的情况:服务器并没有像进度条显示的那样只处理 14 个请求,而是处理了全部 100 个。即使客户端在收到 10 个有效响应后就停止了,它仍然会预先发送所有请求。因此,服务器必须处理所有这些请求。
这是一个很容易被忽略的错误,尤其是在客户端看来一切似乎都运行正常的情况下:响应迅速,进度条不断推进,脚本也提前退出。但实际上,无论我们何时停止监听,所有 100 个请求都会立即发送出去。这会导致流量超出所需 10 倍,从而推高成本、增加负载,并可能导致超出速率限制。
因此,关键问题就变成了:为什么会发生这种情况?我们如何确保只发送真正需要的请求?答案最终是一个虽小但意义重大的改变。
问题的根源在于任务的调度方式。在我们最初的代码中,我们一次性创建了一个包含 100 个任务的列表:
tasks = [fetch(session, URL) for _ in range(NUMBER_OF_REQUESTS)]
for future in tqdm_asyncio.as_completed(tasks, total=NUMBER_OF_REQUESTS, desc="Fetching"):
response = await future当你将协程列表传递给 as_completed,Python 会立即将每个协程包装成Task,并在事件循环中排队执行。这发生在你开始遍历循环体之前。一旦协程被包装成 Task,事件循环就会立即在后台运行它。
as_completed它本身并不控制并发,它只是等待任务完成,并按完成顺序逐个释放它们。你可以把它理解成“已完成任务的迭代器”,而不是“流量管控器”。这意味着当你开始循环时,那 100 个请求都已经在执行中了。在得到 10 个结果后跳出循环,确实停止“处理剩余结果”,但并不能阻止“剩下的请求已被发出去”。
为了解决这个问题,我们在代码里引入了一个信号量(semaphore)来限制并发。信号量的作用很简单:同一时刻,只允许固定数量的请求真正开始执行,其余的先排队等着。这样一来,当我们达到“收集到足够结果、可以停了”的条件时,那些还在排队、还没轮到执行的任务就不会再发请求了。
以下是修改后的版本:
import asyncio
from aiohttp import ClientSession
from tqdm.asyncio import tqdm_asyncio
URL = "http://localhost:8000/example"
NUMBER_OF_REQUESTS = 100
STOP_AFTER = 10
async def fetch(session: ClientSession, url: str, semaphore: asyncio.Semaphore) -> str:
async with semaphore:
async with session.get(url) as response:
body = await response.json()
return body["value"]
async def main():
results = []
semaphore = asyncio.Semaphore(int(STOP_AFTER * 1.5))
async with ClientSession() as session:
tasks = [fetch(session, URL, semaphore) for _ in range(NUMBER_OF_REQUESTS)]
for future in tqdm_asyncio.as_completed(tasks, total=NUMBER_OF_REQUESTS, desc="Fetching"):
response = await future
if response:
results.append(response)
if len(results) >= STOP_AFTER:
print(f"\n✅ Stopped after receiving {STOP_AFTER} true responses.")
break
asyncio.run(main())通过这项更改,我们仍然预先创建了 100 个请求任务,但同时只允许一小部分请求运行(示例里同时只跑了 15 个)。如果我们提前达到停止条件,事件循环就不会继续调度新的任务。这既能保持响应速度,又能减少不必要的调用。
现在,服务器日志只会显示大约 20 条“收到请求 / 返回响应”记录。而客户端的进度条显示方式与之前基本相同。

经过此次调整,我们立即看到了显著成效:请求量和LLM成本降低了90%,且客户端体验未有明显下滑。这一改动还提升了团队整体吞吐效率,减少了任务队列堆积,并消除了来自LLM供应商的速率限制问题。
这个微小的结构优化让我们的验证管道效率得到飞跃性提升,同时并未给代码增加过多复杂性。此事再次提醒我们:在异步系统中,除非明确规划任务的调度方式与执行时机,否则控制流往往不会按照预设模式运行。
深层洞察:关闭事件循环的重要性
若当初没有使用asyncio.run执行原始客户端代码,我们或许能更早发现问题。例如采用手动管理事件循环的方式,
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
loop.close()Python会输出如下警告:
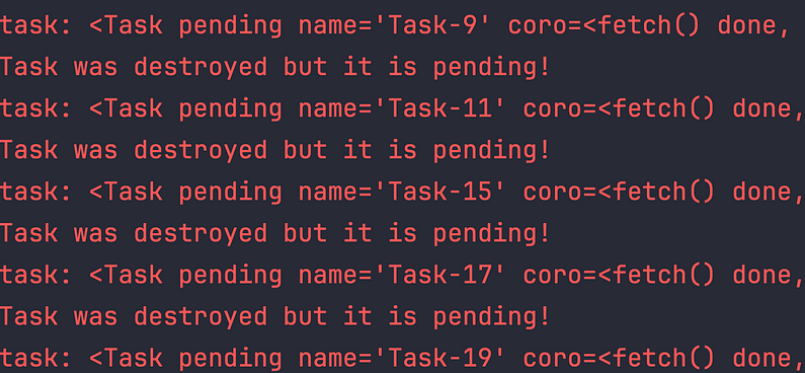
任务已被销毁,但仍处于待执行状态
当程序退出时,若事件循环中仍存在未完成的异步任务,便会触发此类警告。倘若我们当时看到满屏的此类警告,很可能就会更早意识到问题。
那么为何使用asyncio.run()时看不到这些警告?
因为asyncio.run()在后台自动执行了清理操作。它不仅是运行协程后退出,还会取消所有剩余任务、等待它们完成,最后才关闭事件循环。这种内置的安全机制阻止了“待处理任务”警告的显示——即使你的代码悄无声息地创建了过多任务。
而在手动使用loop.run_until_complete()后直接调用loop.close()时,那些没来得及执行的任务会直接被留下。此时Python检测到你在强制关闭仍有任务调度的事件循环,就会发出警告。
这并非要否定asyncio.run()的价值,而是揭示了一个重要原则:应当明确程序退出时哪些任务仍在运行。至少,在系统关闭前监控或记录待处理任务是非常必要的实践。
最终思考
通过重新审视控制流程,我们仅用几行代码就实现了验证流程的质的飞跃——没有增加基础设施,而是更精细地利用现有资源。这次调整带来90%的成本降低,几乎未增加复杂度,同时消除了速率限制错误,减轻了系统负载,让团队能更频繁地执行评估而不产生瓶颈。
这件事深刻提醒我们:“整洁”的异步代码未必等于高效代码,如何 intentional(有意识地)运用系统资源至关重要。负责任的高效工程不仅在于编写能运行的代码,更在于构建珍惜时间、成本与共享资源的设计体系。当我们将算力视为共享资产而非无限资源时,各方都将受益:系统更具扩展性,团队提升协作效率,成本保持可控。
因此,无论是调用LLM、部署Kubernetes任务还是批处理数据,都值得停下来自问:我是否真正做到了物尽其用?
很多时候,解决方案与性能提升,往往仅咫尺之遥。
原文作者:Uri Peled
原文链接:https://towardsdatascience.com/how-we-reduced-llm-cost-by-90-with-5-lines-of-code/


