 首页
首页你跟语音助手说:”推荐一些上海的餐厅……哦对,最好有户外座位的。”
说到”餐厅”之后有个自然的停顿。传统语音助手在这里面临一个问题:这个停顿是你说完了,还是你还没说完?如果判断错了,要么它在你还没说完时就插嘴,要么它明明该回了却还傻等着。
这个问题叫 turn detection,判断说话方是否真的结束了这一轮发言。它是语音 AI 里最难做对的一个环节之一,也是 TEN Framework 做了专门设计的地方。
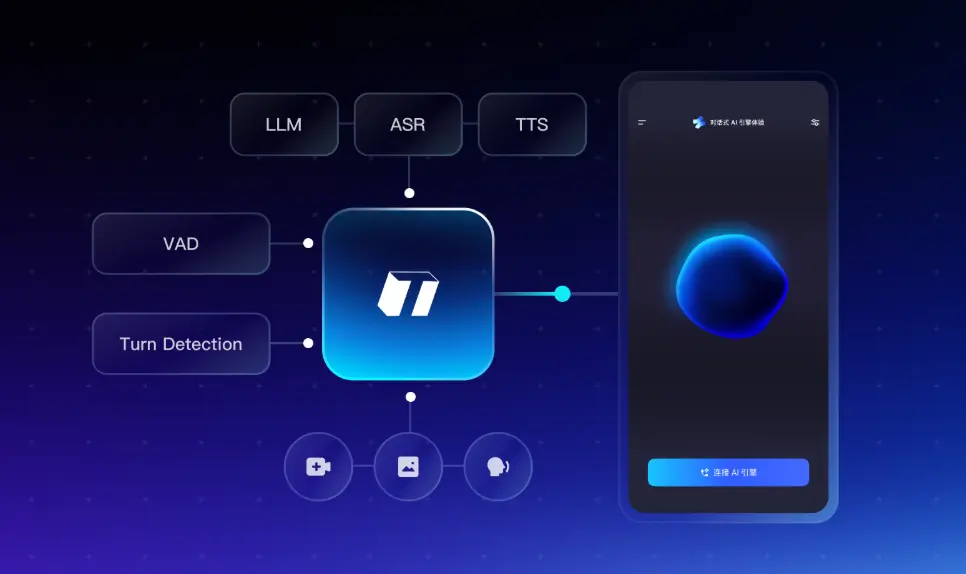
一. VAD 解决的不是这个问题
VAD(Voice Activity Detection,语音活动检测)的工作是判断音频信号里”有没有声音”,区分语音和背景噪音,检测说话开始和结束。这在实时通话场景里是必需的,但它本身不知道”你说的这句话,意思上完整了吗”。
VAD 靠的是音频信号分析,看波形,看频谱,计算声能。它很快,延迟约 50ms,不需要 GPU,适合做噪音过滤和基础的静音检测。它的局限性是,对话里自然停顿的意义,它看不出来。
“我在想……下个月要去哪里度假。”
说到”在想”之后有个停顿,这个停顿不代表说话结束,只是人在组织语言时的自然节奏。但 VAD 看到静音,就判断”说完了”,然后 AI 打断进来,这种误判在复杂对话里很频繁。
Turn detection 想解决的是另一层问题:”这句话,说完整了吗”。
二. 三个状态:finished / unfinished / wait
TEN Turn Detection 把每一段转录文字分成三种状态:
finished:说完了,该回复了
说话方表达了一个完整的意思,等待 AI 回应。
例子:“Hey there I was wondering can you help me with my order”
这种情况 AI 应该开始处理并生成回复。
unfinished:说到一半,继续听
说话方暂停了,但明显还没说完这句话。
例子:“Hello I have a question about”
这个输入在句法上是不完整的,AI 应该继续等待,不要插话。
wait:明确叫停,别说话
说话方明确表示不想让 AI 说话。
例子:“Shut up” / “等一下” / “先别说”
人在对话里叫停对方,是非常常见的行为,但”静音检测”类方案完全没法处理,叫停的话说出来,反而是有声音的,VAD 会判断成新的说话输入。
这三种状态覆盖了实时对话里的绝大多数情形,让系统能对每段输入做出合理的下一步决定:响应、继续听、还是停住。
三. 为什么要用 LLM 来判断
看到这里可能会想:能不能用更简单的方案解决,比如规则判断、小模型,或者加长静音阈值?
加长静音阈值是最常见的”解法”,但它是在用延迟换误判率,等得更久,少打断你,但整体对话的响应速度变慢,体验同样不好。
规则判断理论上可以做一部分:句子以问号结尾的大概率说完了,以”然后””还有”结尾的大概率没说完。但人说话不按规则来,中间随时会改口、补充、停顿思考。
TEN 的选择是用一个专门微调过的 LLM(基于 Qwen2.5-7B)做语义分析。每段 STT 转录出来的文字,都经过这个模型判断当前属于哪种状态。
用 LLM 的关键在于:它真的能读懂上下文。几个用规则没法处理的例子:
自然停顿:”我在考虑……要不要出去旅游。” — 说到”考虑”后有停顿,但这是思考节奏,不是结束。模型能识别”在考虑”是个未完成的表达。
改口:”帮我订一张去北京的机票……算了,换成上海吧。” — 这是一整个 turn 里的自我修正,不是两条独立指令。
连续问题:”北京的天气怎么样?上海呢?” — 这两个问题在语义上是关联的,放在一个 turn 里一起处理,比分成两次回应体验更好。
四. 数据对比:三状态识别的准确率
TEN 开源了一套中英双语测试集(TEN-Turn-Detection TestSet),并在其中对比了几个方案的准确率:
英文测试结果:
| 方案 | finished 准确率 | unfinished 准确率 | wait 准确率 |
|---|---|---|---|
| 方案 A(仅支持英文) | 59.74% | 86.46% | 不支持 |
| 方案 B | 71.61% | 96.88% | 不支持 |
| TEN Turn Detection | 90.64% | 98.44% | 91% |
中文测试结果:
| 方案 | finished 准确率 | unfinished 准确率 | wait 准确率 |
|---|---|---|---|
| 方案 A | 不支持中文 | 不支持中文 | 不支持 |
| 方案 B | 74.63% | 88.89% | 不支持 |
| TEN Turn Detection | 98.90% | 92.74% | 92% |
两点值得注意:一是 wait 状态,对比方案都不支持;二是中文 finished 的准确率,TEN 达到 98.90%,显著高于方案 B 的 74.63%。
这个差距在实际对话里的体感很明显,finished 判断准确了,AI 才能在正确的时机开口,而不是让用户等或者抢话。
五. 架构:数据流是怎么走的
把 Turn Detection 放进整条语音 AI 链路里,流程是这样的:
用户说话(麦克风)
↓
Agora RTC 传输音频
↓
Deepgram STT → 实时转录文字块
↓
每个文字块 → Turn Detection 模型
├─ finished → 送给 LLM 生成回复
├─ unfinished → 继续等待
└─ wait → 停住,不处理
↓
LLM 回复 → TTS 合成 → 用户听到Turn Detection 模型部署在 GPU 上,通过 OpenAI 兼容 API 对接。这样它可以像普通 API 调用一样集成进 TEN 的 Extension 里。
六. 延迟:多出来的 200-300ms 值不值
多一层 LLM 推理,必然带来额外延迟。Turn Detection 这一步大约 200-300ms。
一条完整链路的延迟分布大概是:
| 环节 | 延迟 |
|---|---|
| 音频采集 | ~20ms |
| STT(Deepgram 流式) | 100-300ms |
| Turn Detection(GPU LLM) | 200-300ms |
| LLM 生成回复 | 500-1500ms |
| TTS 合成 | 500-1000ms |
| 总计 | 1-3 秒 |
把整条链路放在一起看,Turn Detection 增加的 200-300ms 在总延迟里占比并不大。而且有一个反直觉的地方:加了 Turn Detection 之后,整体延迟感可能反而更低。原因时候没有 Turn Detection 时,系统容易在用户还没说完时就开始处理,然后给出一个基于不完整输入的回复,接着用户再纠正,再来一轮,这些冤枉路加起来比 Turn Detection 本身的开销大得多。
七. VAD 和 Turn Detection 怎么配合用
VAD 和 Turn Detection 不是互斥的。很多实际场景下,两者配合使用效果最好:
VAD 在前,做噪音过滤,把背景噪音和实际语音分开,只把真正的语音输入送给 STT 和后续环节。这一步很轻量,延迟低,不需要 GPU。
Turn Detection 在后,拿到 STT 的转录文字,做语义层面的判断。它不关心信号,只看内容。
两层分工明确:一个过滤信号,一个理解语义。TEN VAD 和 TEN Turn Detection 都可以独立作为 Extension 接进去,组合使用。
八. 适不适合用 Turn Detection,取决于场景
Turn Detection 不是所有语音 AI 场景的最优解。
如果你做的是唤醒词识别、简单指令控制、IoT 设备交互,对延迟要求极低,VAD 就够了,加 Turn Detection 是过度设计。
如果你做的是多轮对话、复杂问答、客服场景,用户说话的方式不可预期,Turn Detection 带来的准确性提升明显值得那 200-300ms 的额外代价。
还有一类场景是中间地带:用户说的都是短句,停顿很规律,VAD 误判率本来就低,这时候加不加 Turn Detection 差别不大,取决于你有没有 GPU 资源来部署。
模型权重在 Hugging Face 上可以直接取到:huggingface.co/TEN-framework/TEN_Turn_Detection
仓库地址:github.com/TEN-framework/ten-turn-detection

