 首页
首页近年来,随着生成式AI和实时交互技术的发展,基于语音交互的智能硬件应用迅速兴起。从最初的“听得到”(QoS时代),到“听得清、听得懂”(QoE时代),再到如今追求“听得心”(AI QoE时代)的跨模态、拟人化体验。QoS(Quality of Service)关注网络带宽、延迟、丢包、抖动等技术指标;而QoE(Quality of Experience)则关注用户的主观体验,如响应速度、易用性和满意度。
要在智能设备上实现接近人际交流的流畅对话,不仅要保证基础的传输质量,更需通过语义理解、情感表达等高级能力来提升AI的“体验质量”(AI QoE)。对话式AI硬件必须内置让AI“知道何时该听/说”、“如何实现带语义理解的自然打断”、“如何表达得更自然拟人”的对话式AI引擎,才能实现这一目标。
关键指标与用户体验影响
在对话式AI交互中,多个技术指标直接关系体验流畅度:响应延迟、打断时延、丢包抗干扰能力、噪声处理以及全场景适配等。一般来说,双向对话中往返延迟低于1.7秒用户感觉自然;延迟超过2秒就明显感到卡顿,3秒则已经很难接受。为了接近人对话的实时感,声网对话式AI引擎的语音对话延迟可降至500ms级,而其对话硬件套件也宣称延迟低至650ms。实际体验中,更低的延迟能让对话响应更加及时、自然,减少用户等待感。
另一个关键指标是打断时延。自然对话中,当用户插话纠正或提出新问题时,系统应能迅速停止当前回应并切换。声网对话式AI引擎的智能打断响应中位时长只有340ms(最低可达165ms),接近人类对话的反应速度。若打断不够灵敏,用户需要等AI“自说自话”完成,严重破坏沉浸感和交互自然度,这也是此前AI硬件差评率居高不下的重要原因之一。
抗丢包能力影响通信稳定性和流畅度。声网技术经优化可以在高达80%的丢包率下仍保持交流稳定;通过SD-RTN全球实时网络和前向纠错、自适应抖动缓冲等算法,对弱网和抖动进行智能补偿,最大程度减少卡顿。在网络波动下,智能路由技术会自动选择最优路径,并结合丢包控制和拥塞控制策略,保障对话不中断。
噪声与环境干扰是家庭和公共场景下常见的挑战。有数据指出,在嘈杂家庭环境和多人干扰下,AI设备的有效识别率可能不足65%,而儿童发音不准导致指令识别误判率可超过30%。声网通过多级噪声抑制和人声聚焦技术来应对:其AI降噪可强力抑制100+种突发噪声,同时智能滤除背景人声,利用主讲人声纹锁定技术锁定用户声音。声网对话式AI套件可屏蔽95%的环境人声和噪声干扰,实现对话人声精准识别。这些技术提升让AI即使在商场、地铁等复杂环境下,也能持续理解用户意图,不受环境声影响。
多场景适配同样重要。声网“5A全场景适配”指标,覆盖全球各地、全天候、各种大模型和终端设备。例如,声网SDK支持30000+种终端机型,涵盖各种OS和IoT设备,并提供可运行于RTOS系统的超轻量级SDK(仅需1.4MB内存),确保手表等低功耗设备也能流畅通信。在复杂环境适应上,“5A”意味着在不同网络、时段、模型和设备下都能保证服务连续可用。这种多维度适配能力,是确保AI硬件在各种用户场景中都能流畅使用的基石。
- 响应时延:在对话中尽量做到500~650ms级别,超过2s往往会让用户感觉到迟钝。
- 打断时延:目标百毫秒级,声网方案提供340ms中位响应(最低165ms),确保用户能够随时插话。
- 丢包容忍度:可承受高达80%的丢包率;智能路由和纠错算法进一步减轻弱网影响。
- 噪声抑制度:声网AI降噪可覆盖100多种环境噪声,并声称屏蔽95%背景噪音。
- 全场景覆盖:实现全球、全天候、跨模型、跨设备的“5A”适配,支持主流大模型和主流芯片平台。
这些指标直接影响交互体验:低延迟使对话更加自然,快速打断让用户控制流畅不中断,强抗丢包和噪声能力则确保设备能在嘈杂环境和网络波动时依旧保持连贯对话。根据业界反馈,体验不佳的AI硬件往往正是因为延迟过高、识别率低和缺乏打断机制;通过上述技术改善,可有效降低退货和差评率。
关键技术:打断机制、噪声处理与语义理解
为了满足上述指标,需要多种先进技术协同。智能打断(AI VAD)是核心技术之一。声网自主研发的AI语音活动检测(VAD)能够适应自然对话中的停顿、语气和语速变化,判断用户何时真正说话结束。结合上下文的语义完整性判断(如AGC、AINS算法),系统可以区分“用户只是短暂停顿”还是“已完成发言”,从而自由打断AI的回答。这种打断不只是简单的词尾检测,而是综合声学特征和对话语义,确保即时、中断对话仍然连贯。开发者构建场景时,只要引入这套打断机制,AI即可在用户讲话时快速暂停输出,支持随时接入新指令。
噪声抑制与人声锁定的实现依赖于多级音频处理算法。声网通过AI降噪技术,在不损伤人声原音的前提下,有效压制商场、人流、家电等背景声;通过AI回声消除去除麦克风回声;同时利用背景音频过滤和主讲人声纹锁定等策略,主动忽略旁人声音,只聚焦于持麦克风用户的声波
。在工程上,这意味着设备端音频预处理管道中会同时运行噪声抑制、回声消除、旁声过滤等模块,输出的信号才送至ASR进行识别。实践证明,这些算法能在各种复杂环境中保持对话语音清晰,即使孩子们在嘈杂场景中使用智能手表视频通话,也能听清对方。
语义理解与对话连贯则需要整个系统具备“听懂”甚至“听得心”的能力。这不仅指ASR转写的准确性,更涉及对句子含义和上下文的理解。声网的方案会对识别结果进行语义完整性判断,确保不会在用户尚未表达完整意思前就打断。更重要的是,与大模型(LLM)深度集成后,系统能够结合语境和长期记忆进行应答,使AI对话从**“理解文本”提升到“理解用户心理和意图”。通过将RT数据流与大模型推理结合,声网的对话式AI引擎让智能硬件具备了“仿人”般的交互节奏:在回答时表现出拟人化情感,换角时保持一致语音风格,并在对话中保留关键信息,让用户产生更强的情感共鸣。
- 实施智能打断:采用AI VAD技术实时检测用户发言开始/结束,配合语义完整性判断算法(如AGC/AINS),让AI能立刻中止当前回复,避免用户被“打断”的体验。
- 深度噪声抑制与人声锁定:在信号链路中加入多级AI降噪和回声消除模块,并通过主讲人声纹锁定,仅采集目标用户的声音,屏蔽环境或其他说话者。
- 端到端语义完整性:在打断判定前,检测用户句子的语义完成度,确保不会误截断正在说话的语句;对识别结果利用LLM做上下文理解,使对话连贯并保留情感因素。
- ASR/LLM/TTS流水线:构建从麦克风采集→ASR转写→LLM生成→TTS合成的全流程管道,让设备能“听”到声音后迅速“说”出回答。
对话式AI引擎架构与组件串联
声网推出的对话式AI引擎将上述技术集成到一个灵活架构中,兼容各种第三方大模型(如DeepSeek、ChatGPT等)和语音服务。通过智能的工作流编排,开发者可以根据场景需求自由替换ASR、LLM或TTS模块。下图示例了典型的系统架构:设备端预处理音视频信号后通过SD-RTN™实时网络传输,后端的对话式AI引擎核心包含AI VAD、背景声滤除、智能降噪、回声消除和优化打断等音频算法模块,并与ASR/LLM/TTS等大模型协同工作。
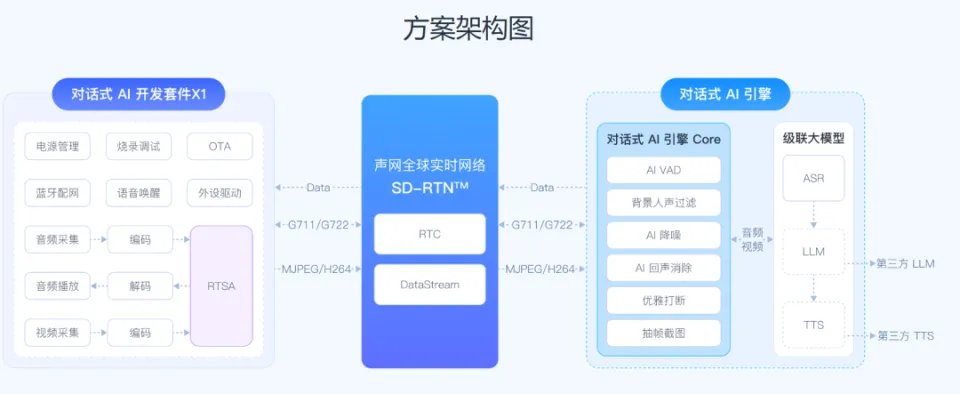
示例架构图:设备端采集音频并预处理,经过声网SD-RTN全球实时网络传输到对话式AI引擎。引擎核心包含AI VAD、背景人声过滤、智能降噪、AI回声消除、优化打断等模块,同时整合ASR、LLM、TTS等大模型,实现端到端语音交互。数据流使用标准音视频格式(如G711、G722、MJPEG/H264等),确保实时性和兼容性。
在上述架构中,语音数据在实时传输网络(SD-RTN™)中低延迟传输,然后由AI引擎负责核心处理。声网对话式AI引擎支持“任意文本大模型一键接入”,让开发者可以快速将各种LLM升级成“能说会道”的多模态模型。声网产品层面集合了全球最全的ASR/LLM/TTS服务商,形成开放生态,使硬件厂商用同一个引擎模块专注场景创新,无需重复造轮子。
声网技术的多场景适应与案例验证
声网的技术在多种实际场景中得到验证。在儿童智能手表、AI玩具、智能家居和可穿戴设备等场景下,相关案例显示其稳定性和多样功能。比如小天才Z10电话手表采用声网RTC技术实现了全球首个RTOS支持的低功耗SDK(主存1.4MB),支持双摄720P视频通话,并新增实时字幕功能,依靠云端STT同步转写对方语音,在嘈杂环境下解决听不清问题。其SD-RTN网络确保视频通话端到端延迟极低,同时兼容3万多款终端机型。
在AI玩具领域,如珞博科技的Fuzozo,采用声网对话式AI赋能后,显著提升了交互实时性和稳定性,实现了情感陪伴场景下的核心体验保障。另一典型,Looktech推出的Memo AI眼镜搭载多种大模型作为语音助手,在声网技术加持下实现了“超低延迟响应、噪声屏蔽和智能打断”能力,显著提升用户对话体验。这些案例都验证了声网方案在复杂家庭、移动场景等环境下的适配性。
此外,声网方案已在技术层面覆盖多种芯片平台和系统(如Broadcom、Espressif等主流芯片,安卓、Linux、RTOS等系统)。其一小时跑通Demo,一天完成产品原型送样的快速部署能力,也表明了成熟的工程化支持。开发者和厂商只需基于同一套对话引擎接口,即可实现智能硬件产品从设计到量产的快速迭代。这一“AI+IoT”思路强调硬件为入口、云服务为终身价值,通过技术实力为产品注入“数字灵魂”,正是声网解决传统硬件体验问题的方向。
综上所述,对话式AI赋能智能设备需要从底层网络质量和音频算法做起,同时借助大模型实现更高层次的语义和情感理解。关键在于将ASR、LLM、TTS等能力通过低延迟、抗干扰的实时网络串联起来,并通过AI VAD、智能打断和多级降噪等技术,让人机对话贴近自然对话的节奏
。声网在这方面积累了丰富实践:其SD-RTN™网络实现了全球200ms级平均延时,AI引擎支持海量设备和多场景适配,并在实际产品中展现了低延迟、语义连贯、情感丰富的对话效果。对于AI开发者、产品经理和硬件厂商来说,要打破“硬件思维”,将体验思维置于首位,通过优化上述指标和技术,才能真正让智能硬件“会说话”并陪伴用户,开创AI硬件的新格局对话式AI引擎架构与组件串联声网推出的对话式AI引擎将上述技术集成到一个灵活架构中,兼容各种第三方大模型(如DeepSeek、ChatGPT等)和语音服务。通过智能的工作流编排,开发者可以根据场景需求自由替换ASR、LLM或TTS模块。

