 首页
首页声纹注册(Voiceprint Enrollment) 是声纹识别系统的基础步骤,用于让系统“学习并建立某个用户的声音特征档案”。它类似于人脸识别中的“人脸录入”,或手机解锁中的“指纹录入”,但对象是用户的声音。在完成声纹注册后,系统就能在后续的语音验证或多说话人场景中,通过声纹模板识别说话者身份,实现 安全验证、个性化服务、对话分配优化 等多种应用。声纹注册广泛用于 金融安全、呼叫中心、IoT 设备、智能助手、会议系统、对话式 AI 应用、身份认证系统 等领域。
本文将从定义、技术原理、工作流程到应用价值,帮助你快速理解这一重要能力的本质与未来发展。

什么是声纹注册?
声纹注册是系统采集并建立用户声纹模板的过程。每个人的声音具有独特的生物特征,由声道结构、发声方式、习惯性语音模式共同决定。声纹注册就是将这些特征提取、向量化,并保存为可匹配的数据模板。
在专业系统中,声纹注册通常包含:
- 语音采集(Enrollment Audio Capture)
- 特征提取(Feature Extraction)
- 声纹建模(Embedding / Template Creation)
- 模板存储(Secure Storage)
注册完成后,系统即可在后续使用 声纹验证(Verification) 或 声纹识别(Identification) 技术对用户身份进行判断。
声纹注册的工作流程
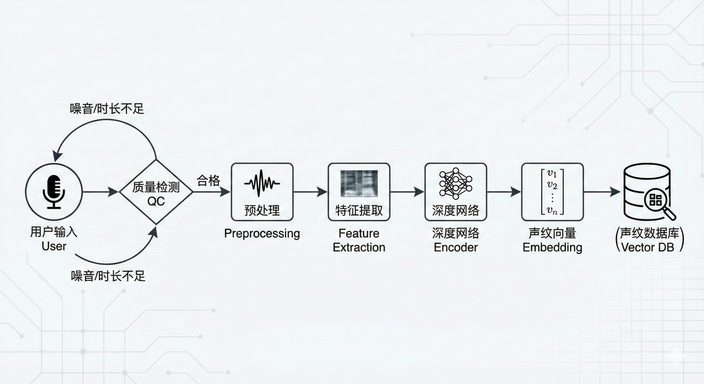
虽然用户感受到的可能只是 “读一句话”,但系统内部需要经过一套完整的流程来确保声纹模板稳定可靠。一般包括以下 4 个关键步骤:
1. 录音采集:第一次与系统“见面”
用户按照提示朗读固定或随机文本,如:“请读出以下数字:825940”、“请说一句:今天天气不错”
音频需要满足基本质量要求:无杂音、无回声、采样率 ≥ 16kHz。
系统可能要求用户提供 1–3 次录音以提升可靠性。采集越干净,后续识别越准确。
2. 语音预处理:去噪、分段与清洗
原始语音往往存在背景音、环境回声、长停顿。模型无法直接利用,需要进行:
- 降噪(Noise Reduction)
- 回声消除(AEC)
- 语音活动检测(VAD)
- 归一化(Normalization)
这一步骤的目的是确保模型提取到的声纹特征更稳定、更纯净。
3. 声纹特征提取:将声音变成数学向量
这是声纹注册的核心步骤。系统会通过深度学习模型生成“声纹向量”(speaker embedding),常见网络包括:
- x-vector
- ECAPA-TDNN
- ResNet-based Speaker Encoder
- Conformer Encoder
- Large Audio Models(LAM) 的 speaker embedding 模块
这些模型会将语音信号转化为一个固定长度的高维向量,例如 192 维、256 维或 512 维。
这个向量就是声纹识别系统的核心:声纹向量(Speaker Embedding)= 声音的“数学指纹”。
4. 声纹模板生成与存储:成为系统的“档案”
声纹向量还需要经过:
- 聚合与滤波
- 质量评分
- 模板归一化
- 加密存储
最终形成声纹模板(Voiceprint Template),用于未来的身份认证。从此以后,只要你再次开口,系统就能通过“相似度评分”判断是不是你本人。
声纹注册的技术原理概述
声纹识别是一门结合声学、生理学与人工智能的交叉技术。声纹技术属于 生物特征识别(Biometric Authentication) 的一个分支。核心科学原理包括:
1. 先天差异:每个人声道结构不同
每个人的喉部、口腔、鼻腔构成了独特的声道共振结构,形成无法复制的物理特征。这些差异就好比“声音的 DNA”。
2. 后天行为特征:语言习惯的持久一致性
即便模仿者能模仿音色,但很难模仿:
- 音高曲线
- 语速节奏
- 气流控制
- 停顿习惯
- 情绪表达方式
这些行为特征在长期稳定存在,是声纹识别的重要依据。
3. 声学参数建模
系统会分析声音中的:
- 共振峰(Formants)
- 基频(F0)
- 频谱能量分布(Spectral Envelope)
- Mel Frequency Cepstral Coefficients(MFCC)
- 时频动态特征(Temporal-Spectral Dynamics)
4. 深度学习建模(Deep Neural Network Embeddings)
现代声纹识别依赖深度学习生成 embedding,具有:
- 鲁棒性高
- 适应噪声环境
- 适应跨设备差异
- 可扩展大规模说话人库
5. 匹配机制(Scoring & Verification)
常用评分方法:
- Cosine Similarity
- PLDA
- Neural Discriminative Scoring
当相似度超过阈值,就判定“为同一人”。
声纹注册有什么用?
声纹注册是后续“识别是谁”与“验证是不是本人”的前置步骤。它不仅用于身份识别,也推动了对话式 AI 与实时交互的发展。典型应用包括:
1. 身份认证
是声纹技术最成熟的应用,包括:
- 银行、运营商热线的身份验证
- App 登录、找回账号
- 风控系统辅助验证
- 多因子认证(MFA)的一环
优势: 无需密码、不易遗忘、不可复制、使用自然。
2. 对话式 AI Call Center(智能呼叫中心)
- 自动识别来电者
- 风控验证
- 多轮对话中的个性化服务
这为实时对话式 AI 带来巨大的效率提升。
3. 智能硬件与 IoT
智能音箱、车载系统、机器人等场景中,声纹注册能实现:
- 主人识别
- 家庭成员区分
- 个性化唤醒词
- 个性化指令执行
让设备“听懂是谁在说”。
4. 多人语音场景(会议、课堂、直播)
- 说话人追踪(Speaker Tracking)
- 多说话人分离(Diarization + Enrollment)
- AI 助理分角色记录会议纪要
声纹注册 vs 声音识别(ASR)的区别
| 对比项 | 声纹注册 | 声音识别ASR |
|---|---|---|
| 关注点 | 是谁在说话 | 说了什么内容 |
| 结果形式 | 用户身份 / 说话人标签 | 文本(Transcript) |
| 输入需求 | 通常需要干净语音样本 | 背景噪声容忍度高 |
| 技术基础 | 声纹向量、相似度评分 | 声学模型 + 语言模型 |
| 功能类型 | 身份认证、生物特征识别 | 内容转写 |
影响声纹注册质量的关键因素
为了获得稳定的声纹模板,需要注意以下几点:
- 麦克风质量
- 背景噪音
- 说话人健康状态(感冒可能造成差异)
- 上下文内容(固定短语 vs 随机短语)
- 录音时长(一般 3–10 秒最佳)
- 设备一致性(跨设备需做归一化)
优秀的声纹系统通常会加入质量评分与多段融合,确保模板足够稳定。
声纹注册是声纹识别系统的起点,它让设备首次“认识你的声音”,并在之后的交互中持续利用这一能力带来安全与体验提升。

