 首页
首页2025 年 8 月,微软开源发布了 VibeVoice-1.5B——一个独具创新的文本转语音(TTS)模型,支持“一文生成长达 90 分钟的对话音频”,并能在单次生成中模拟 最多 4 位不同说话人的自然对话。它基于全新的“连续语音标记器 + 扩散生成”框架,实现语义与声学分离、高效长上下文处理,并在开源许可下对研究者友好发布。本文将以通俗科普的方式,为你展现 VibeVoice 的基本概念、核心能力、技术架构及合理边界,是理解这款开源 TTS 的必读入门内容。
1. 什么是 VibeVoice?
VibeVoice 是微软研究院发布的一款全新 开源 TTS 框架,专注于生成“长播、对话式、表达丰富”的音频内容,比如播客或多说话人对话内容。具体来说,VibeVoice-1.5B 在单次文本输入下,可生成:
- 最长约 90 分钟音频;
- 包含 最多 4 位不同说话人对话场景;
- 支持跨语种(中英文)和带一定“唱歌”成分的表达;
- 完全开源,采用 MIT 许可证,方便研究使用;
- 这是传统 TTS 系统难以实现的能力边界突破。
简单来说,VibeVoice就像是一个”超级语音演员”,你给它一个剧本,它能找来4个不同声音的”演员”,为你演出一场长达90分钟的对话节目。而且这些”演员”完全由AI生成,不需要真人录音。
2. VibeVoice 技术解读(结构与原理)
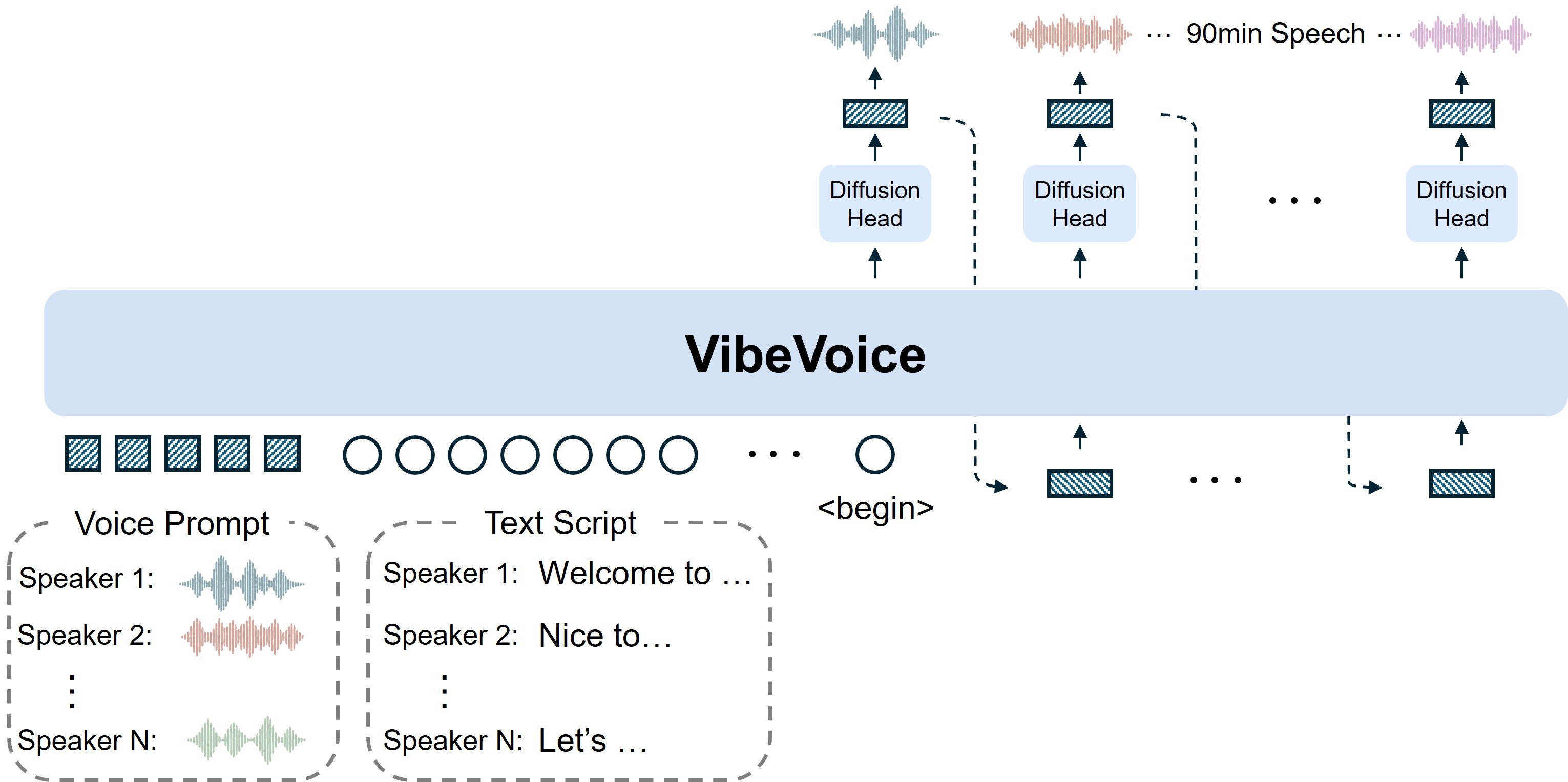
这幅图呈现了 VibeVoice 从 角色语音样例 + 文本脚本输入 → Tokenizer 编码 → LLM 解读上下文 → Diffusion Head 渲染声学特征 → VAE 解码输出音频 的完整流程。
2.1 架构总览
VibeVoice 因其突破性的长语音与多说话人能力,采用了独特的三段式架构:
- 连续语音标记器(Tokenizer):包括 Acoustic 和 Semantic 两种,每秒处理约 7.5 帧,大幅度压缩音频细节,提升处理效率。
- LLM 上下文理解:采用 Qwen2.5-1.5B 大语言模型理解对话结构、语义与角色识别。
- 扩散解码生成头(Diffusion Head):从 LLM 隐状态中逐 token 生成精细声学特征,最后通过 VAE 解码输出高保真音频。
整体架构能够保持语义一致、说话人身份标记清晰、同时生成连续长音频。
2.2 关键组件分析
- Continuous Tokenizers:维持音质与处理效率,通过 7.5Hz 的超低帧率减少 token 数量,节约计算资源。
- Acoustic Tokenizer:σ-VAE 架构,编码/解码器各约 3.4 亿参数,压缩音频约 3200 倍。
- Semantic Tokenizer:结构类似 Acoustic,但只需“语义内容”表示,省去 VAE,并通过 ASR 代理任务训练生成文本意义 token。
- Diffusion Head:轻量模块(约 1.23 亿参数),使用 Classifier-Free Guidance 和 DPM-Solver 推理方式,增强音质与稳定性。
- Context Curriculum:训练中逐步增加处理长度,从 4k → 65k token,使模型适应长语境生成。
2.3 工作流
1)输入阶段:Voice Prompt + Text Script
Voice Prompt(可选):提供说话人声线示例(例如 4 位角色的短语音样本),帮助生成模型调度声音特征与说话人风格一致。
Text Script(核心输入):包含角色对话脚本,格式如:
Speaker 1: Welcome...
Speaker 2: Nice to...
…
模型根据文本与角色轮次构建对话。
2)Tokenizer 阶段:Acoustic 与 Semantic Tokenizers
输入先由两种 连续语音标记器(tokenizer) 编码:
- Acoustic Tokenizer:基于 σ-VAE 的结构,压缩 24kHz 音频至超低帧率(7.5 Hz),每秒只生成少量音频 token。其设计有效压缩了约 3200× 帧信息量,在长文本处理时显著降低计算开销。
- Semantic Tokenizer:采用与 Acoustic 类似的编码过程,但不包含 VAE 解码路径,重点捕获语义内容,通常通过 ASR 任务代理训练。
3)混合上下文处理:文本 + 语音标记嵌入拼接
- Tokenizers 生成的 token 与文本脚本中的角色信息一同串联,形成统一输入序列供 LLM 处理。
- 这一步使模型能够理解角色身份、上下文流与对话节奏。
4)上下文解读:LLM 掌控对话流程
- 经过拼接后的序列输入到 Large Language Model(如 Qwen2.5-1.5B),负责理解对话结构、角色走向、语境转折等。
- LLM 的隐藏状态为后续生成阶段提供语义条件。
5)合成阶段:Token-Level Diffusion Head
- 生成任务由 Diffusion Head(扩散生成头) 执行,它是一个轻量模块(约 123M 参数,4 层结构),基于 LLM 的隐藏状态条件预测下一个 acoustic VAE token。
- 使用的是类似 DDPM 的去噪扩散策略(Classifier-Free Guidance + DPM-Solver),按 token 逐步生成高保真语音特征。
6)解码阶段:VAE Decoder 输出音频
- 预测的 acoustic VAE tokens 经过 Acoustic Tokenizer 的 Decoder(VAE 解码路径)最终生成连续音频波形,并输出成时长可达 90 分钟、多角色参与的对话音频。
7)循环扩展:迭代生成至目标时长
- 模型循环执行 token 生成、解码步骤,持续生成音频直到达成设定长度(如 90 分钟)或文本脚本结束。
3. VibeVoice 的能力亮点
结合官方报道与模型卡,我们可以提炼出几条核心优势:
3.1长语音生成:90 分钟不间断
VibeVoice-1.5B 能够一次性生成长达 90 分钟音频,远超传统 TTS 模型通常支持的几秒至几分钟范围,适用于播客、长对话内容制作。
3.2 多说话人对话自然切换
支持最多 4 个说话角色,并自然处理说话轮次,是进行对话模式生成的关键能力。
3.3 表情丰富:语音、唱段、语种融合
除对话外,VibeVoice 可生成具有“情感表达”“唱歌”风格、以及跨中英文混合输出,增强生成内容的表现力。
3.4 原创开源方式:MIT 许可
该模型基于 MIT 开源协议发布,适合学术研究与共享创新使用,增强了透明度与可复现性。
3.5 未来可期:7B 流式版本在路上
文中还提及即将推出的 7B 流式版本,将进一步提升实时性与生成效率,适用于互动式应用。
4. 使用范围与合理边界
根据 HuggingFace 模型安全说明,该模型虽功能强大,但不适用于一些敏感场景:
4.1 支持但有限语言与风格
支持 仅限英文与中文,非这两种语言的生成可能失准或不可理解。
不支持背景音、音乐或声效,仅限“纯人声输出”。
说话时不支持多人同时交谈(重叠语音),仅自然轮流发言场景。
4.2 合规警示
强烈禁止用于声音克隆身份冒充、诈骗、深伪录音、绕过身份验证或散播虚假信息等用途。
同时该模型建议用于研究与探索用途,不建议直接商业部署,除非完成后续的稳健性/法律合规测试。
5. 开源许可与获取方式
- MIT 许可:允许商业使用、派生与再分发,是现代常见的开源协议,利于开发者快速实验与商业化参考。
- GitHub 仓库:Microsoft 官方发布源代码、Demo、培训脚本与使用说明。
- Hugging Face 模型卡:提供详细训练信息、架构概要、安全使用指南、“Out-of-scope uses” 等文档资源。
VibeVoice-1.5B 是一次 TTS 技术的重大突破,其在“如何高效生成长对话音频且支持多说话人”方面表现史无前例。它不仅为播客、音频小说等内容创造提供技术可能,更为研究者探索 TTS 边界提供开放基础。技术上的创新(低帧率 Tokenizer + LLM + Diffusion)为未来语音模型设计提供新思路。

