首页
首页
摘要
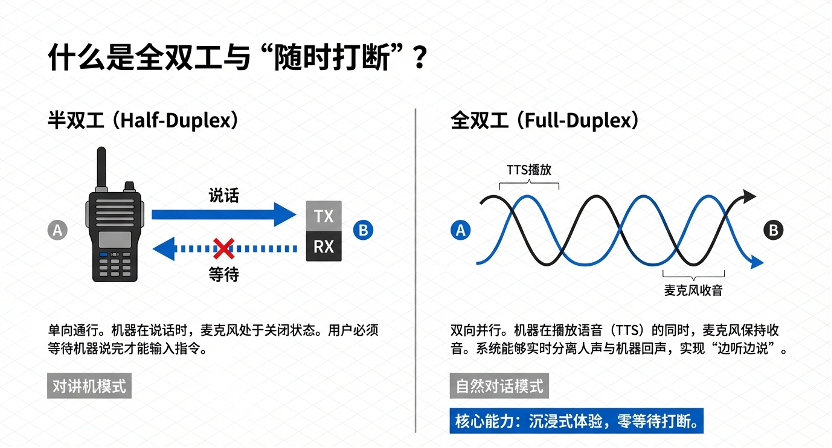
随着人工智能技术的飞跃,现代语音交互系统正经历向“全双工”(Full-Duplex)架构的范式转移。传统的语音用户界面深受“半双工”通信模式限制,导致人机对话呈现机械化的“说-停-听”循环 。语音活动检测(Voice Activity Detection, VAD)作为全双工(Full-Duplex)交互系统的核心“感知层”,负责在复杂声学环境下精准判定人类语音的起始与终止 。该技术通过过滤背景噪声与静音,有效降低系统计算能耗,并为毫秒级的“智能打断”提供关键触发信号 。
本文将梳理语音活动检测(VAD)技术的技术定义、技术原理、技术标准、应用场景、以及未来发展趋势,旨在为开发者们、语音技术专家、系统架构师及研究人员提供一份尽量详尽的技术百科参考。
1. 技术定义
语音活动检测(VAD)是语音信号处理系统中的首要环节与“关卡”,其本质是一个高度鲁棒的实时二分类问题 。
核心任务
VAD 需从连续输入的音频流中,将每一帧信号(通常为 20ms-30ms)准确划分为“语音(Speech)”或“非语音(Non-Speech)”类别 。
范畴界定
- 语音类:包含有意义的人声片段,涉及浊音(元音等具有周期性的信号)与清音(摩擦音等类似于高频噪声的信号) 。
- 非语音类:涵盖绝对静音、平稳背景噪声(如空调风声)、非平稳突发噪声(如关门声、键盘敲击音)以及非交互性人声(如咳嗽、喷嚏) 。
尽管定义简单,但在低信噪比、混响严重或存在多说话人的真实环境中,实现高准确率的VAD极具挑战性 。
2. 技术原理
VAD 的演进经历了从简单的时频域阈值判定到复杂统计建模,再到深度学习时序建模的三个阶段 。
2.1 物理特征采集与预处理
系统将输入的模拟音频离散化后,进行分帧处理(如 20ms 一帧),并提取能够表征语音物理特性的指标 :
- 短时能量(Short-Term Energy):基于“语音能量通常高于背景噪声”的物理假设 。
- 零过交率(ZCR):统计信号穿过零电平的次数。浊音 ZCR 较低,清音和噪声 ZCR 较高 。零过交率公式如下:
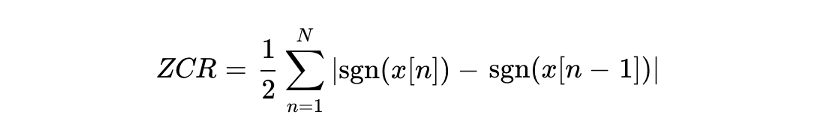
- 谱熵(Spectral Entropy):衡量频谱分布的无序度。语音由于谐波结构有序,熵值较低;噪声则随机性强,熵值较高 。
2.2 统计模型
随着统计信号处理的发展,基于概率模型的VAD逐渐取代了简单的阈值判定。高斯混合模型(GMM)对语音和噪声分布建模,能够计算当前帧的似然比(LRT) 。这种方法计算开销极小,但在非平稳噪声(如键盘敲击声、远处的人声干扰)下,基于 GMM 的 VAD 性能显著下降,尤其在弱语音检测上容易产生漏检。 ,这意味着会丢失大量微弱的语音片段,导致“切词”现象。此外,GMM缺乏时序建模能力,无法利用上下文信息来平滑判定结果。
2.3深度学习架构(现代主流)
深度神经网络(DNN)的引入引发了VAD技术的范式革命。与依赖人工特征的传统方法不同,深度学习模型能够从海量数据中自动学习复杂的时频模式,显著提升了在低信噪比环境下的鲁棒性。
- CNN 时频图分析:卷积神经网络(CNN)在图像处理领域的成功被迁移至音频分析。VAD模型通常将音频转化为梅尔频谱图(Mel-Spectrogram)或MFCC特征图,将其视为“图像”进行处理。该技术能够捕捉共振峰等局部特征,远超传统MLP和统计模型。
- LSTM 时序记忆:语音本质上是时间序列信号,而长短期记忆(LSTM),通过引入“门控”机制和记忆单元,能够捕捉上下文信息。即便当前帧能量因爆破音瞬间跌落,LSTM 也能“记住”先前的语音状态,从而避免语音切断(Clipping) 。
3. 核心挑战与对策
在应用层实现高标准的 VAD 需克服以下工程难点:
回声自激干扰
全双工模式下,系统扬声器声音会进入麦克风。若 AEC(声学回声消除)不力,VAD 会误将系统自身的 TTS 判为用户说话,导致自激式打断 。因此,必须在 VAD 之前部署高性能 AEC 模块,并配合双讲检测(DTD)逻辑 。
语义缺失的“假打断”
环境中的咳嗽声或背书语(如“嗯”、“对”)常被 VAD 识别为语音 。对此,可以引入语义话轮结束检测(EoT)与流式 ASR 的“稳定性分数”,区分物理语音与交互意图 。
多说话人干扰
在办公室或家庭环境中,旁人交谈易触发 VAD。可以通过部署个性化 VAD(pVAD),结合声纹嵌入(Speaker Embedding)技术,仅响应认证用户的声音信号 。
4. 闭环链路逻辑
VAD 在全双工实时交互中的信号流向如下:[ 麦克风音频采集 ] → [ AEC 声学回声消除 ] → [ VAD 语音判定 ] → [ ASR 部分结果识别 ] → [ 智能打断逻辑判定 ] → [ TTS 播放/停止控制 ]
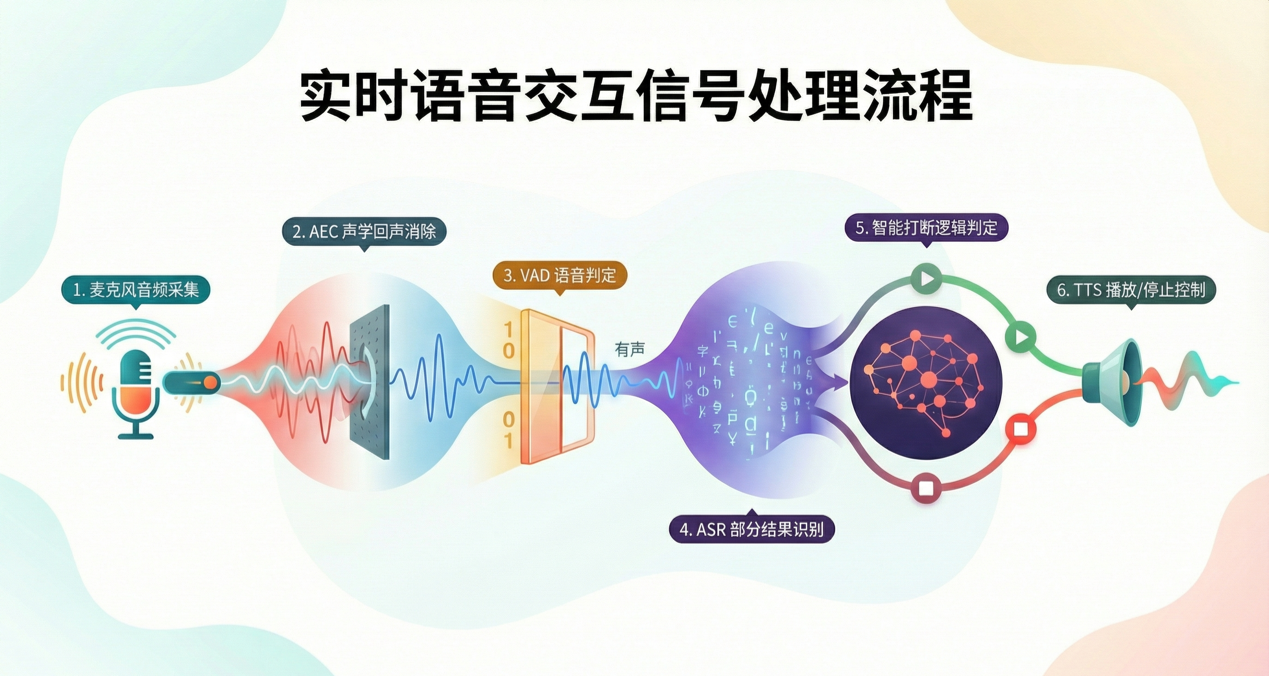
逻辑闭环说明:VAD 产生触发信号后,系统不会立即停止 TTS,而是先执行“音量闪避(Ducking)”,待流式 ASR 的中间结果识别出关键词(如“停止”)或语义完整后,再执行强制停止 。
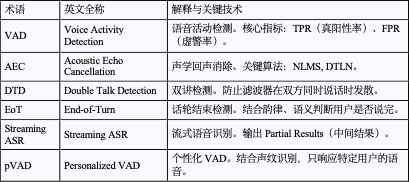
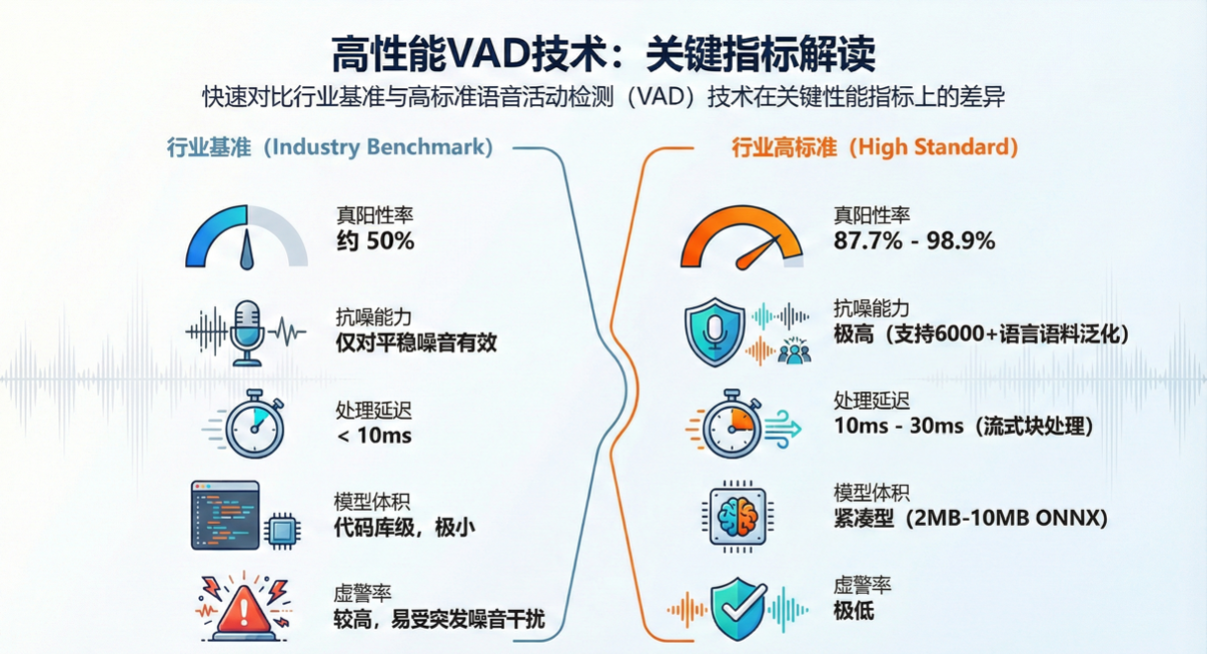
5.关键技术指标
6.应用场景
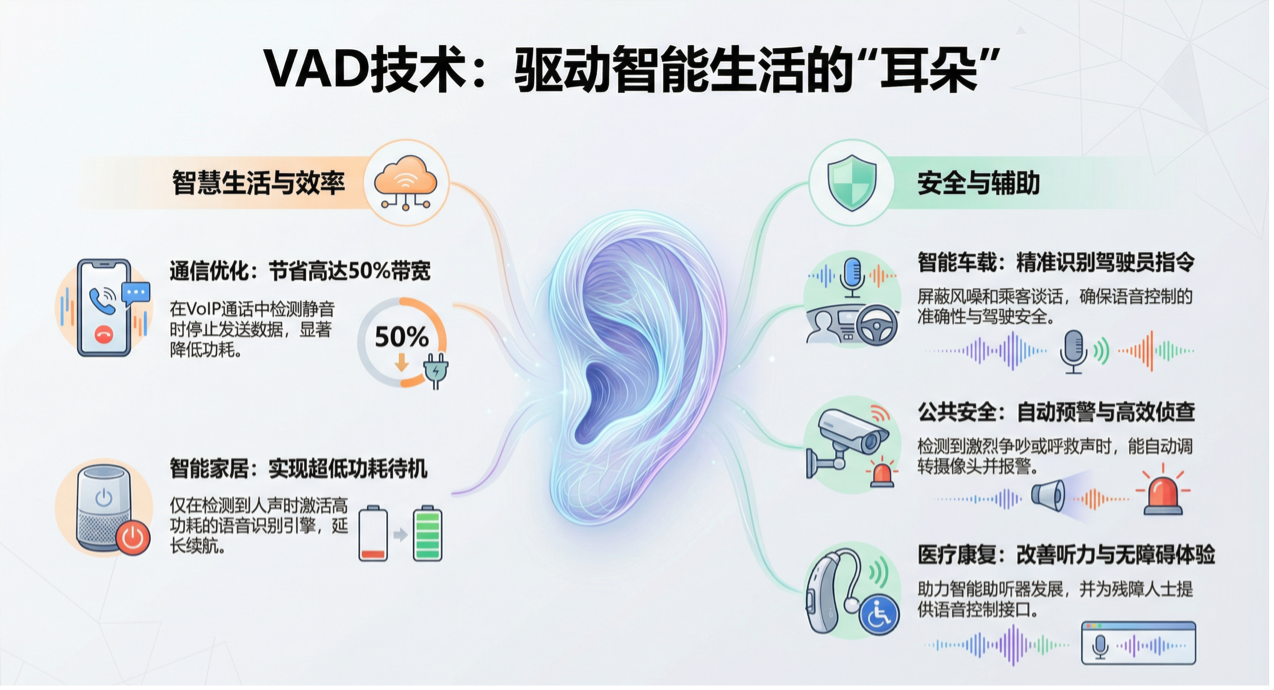
数字化生活场景
通信与底层架构
在 VoIP 通话中,VAD 检测到静音时停止发送数据包,可节省高达 50% 的带宽资源,并显著降低移动端功耗。同时,VAD 将非语音片段交给噪音抑制算法,用于实时更新环境底噪模型。
智能家居与物联网
一方面,设备通过极低算力的 VAD 持续监听,仅当检测到人声时才激活高功耗的 ASR 引擎,延长电池续航。另一方面,智能空调、灯光系统通过检测特定空间内的语音活动,辅助判定人员驻留状态,实现自动化节能。
智能车载与驾驶安全
配合波束成形技术,VAD 能精准识别驾驶员位置的语音,屏蔽窗外风噪或乘客谈话,确保指令执行的精准性。或者通过识别特定频率的呼救声或尖叫声触发安全预警,实现紧急事件监测。
公共安全与安防
在盲区监控中,VAD 配合声源定位技术,在检测到激烈争吵或呼救声音时,自动调转摄像头视角并报警。此外,从长达数天的监控录像中,自动提取包含人声的片段,极大提升案件侦办效率。
医疗与康复
VAD 实时区分言语信号与环境噪声,仅对言语信号进行频段增益补偿,防止由于全局放大带来的二次听力受损,助力智能助听器发展。VAD还可以为肢体残障人士提供基于纯语音活动控制的医疗器械接口,优化无障碍环境。
在对话式 AI 中的应用
语音活动检测(VAD)作为全双工智能打断逻辑的核心触发器:
- 流式 ASR 协同:利用 ASR 输出的中间结果结合稳定性分数,实现毫秒级的关键词(如“停止”)打断 。
- 音量闪避:检测到 VAD 信号时,系统先平滑降低 TTS 音量而非立即切断,若确认为噪声则恢复,提升容错率 。
- 个性化 VAD (pVAD):结合声纹识别技术,仅响应特定认证用户的打断,过滤背景中他人的谈话 。
7.未来趋势:多模态与端到端模型
视觉增强VAD(Audio-Visual VAD)
在极度嘈杂的环境,纯音频VAD几乎失效,因此未来的方向是融合视觉信息。
- 唇语检测:通过摄像头分析用户的唇部运动。如果嘴唇在动,即使麦克风全是噪音,VAD也判定为语音。
- 注视检测:如果用户看着屏幕/摄像头说话,打断概率极高;如果用户看着旁边说话,可能是与他人交谈,系统应忽略。2025 年多模态信息语音处理 (MISP) 挑战赛(Multi-modal Information Based Speech Processing)正聚焦于此 。
大模型端到端预测(LLM-based Turn-Taking)
GPT-4等多模态大模型的出现,正在模糊 VAD与ASR的界限。多模态大模型跳过了转文字环节,它可以直接处理音频Token,感知用户的语调(如急促的呼吸声表示紧急打断,拉长的元音表示犹豫)。这将实现真正“人类级别”的直觉打断,能够区分“反讽”、“犹豫”和“坚定”的打断意图。
8. 附录:关键术语表与技术指标