 首页
首页引言
在对话式AI系统快速发展的今天,如何确保系统能够准确理解用户意图、维护对话上下文、处理异常情况,已成为测试团队面临的核心挑战。传统的对话式AI Demo测试已无法满足复杂对话场景的验证需求,我们需要一套能够模拟真实用户交互、覆盖完整对话流程的端到端测试框架。
过往的测试方式存在诸多局限性:主播加入频道需要人工操作,测试人员必须手动点击按钮、输入频道信息才能建立连接;需要人来说话,每次测试都需要测试人员亲自发声,不仅效率低下,而且无法保证测试的一致性和可重复性;多语种场景无法覆盖,当需要测试日语、英语、粤语等不同语言时,测试人员往往不具备相应的语言能力,导致测试覆盖不全;输出内容如何自动判断符合用户提问输入,系统响应的正确性只能依赖人工判断,主观性强、效率低,且无法实现大规模自动化测试。
本文将一起探讨对话式AI测试框架如何演进,逐步解决这些痛点,构建起一套端到端对话式AI的自动化测试体系。

测试框架演进路线图
一、测试框架的演进
第一阶段:基础工具验证(Postman + 集成RTC SDK的Demo)
最初的测试方式相对简单,主要依赖Postman等工具进行对话式智能体服务端API调用,配合集成声网 RTC SDK的Demo,加入相同的RTC频道进行人声说话测试,最终通过人工判断回答结果。
核心痛点:
1. 主播加入频道需要人工操作:每次测试都需要测试人员手动打开Demo应用,输入频道信息,加入频道等按钮,这一过程不仅耗时,而且无法实现自动化批量测试。
2. 需要人来说话:测试人员必须亲自发声,通过麦克风输入语音。这种方式存在明显问题:
- 测试效率极低,无法实现7×24小时无人值守测试
- 测试一致性差,不同人员、不同时间、不同环境下的语音输入存在差异
- 无法精确控制输入内容,难以构造特定的测试场景
- 无法进行大规模并发测试
- 无法进行声纹相关的测试
3. 多语种场景无法覆盖:当需要测试日语、英语、粤语、上海方言等不同语言和方言时,测试人员往往不具备相应的语言能力,导致:
- 多语种测试覆盖不全
- 无法验证系统对不同语言和方言的识别能力
- 国际化场景测试受限
4. 输出内容如何自动判断符合用户提问输入:系统响应的正确性完全依赖人工判断,存在以下问题:
- 主观性强,不同人员对同一回答的判断可能不一致
- 效率低下,需要人工逐条检查
- 无法实现自动化验证
局限性总结:整个测试过程高度依赖人工,无法实现真正的自动化测试。
第二阶段:脚本化测试(Python Request + 集成RTC SDK的Demo)
随着测试需求的增长,QA 团队开始使用Python脚本化的Request方式进行测试,但仍然依赖集成RTC SDK的Demo操作和人声说话,测试结果仍需人工判断。
核心能力:
1. 多厂商管理:Python脚本有效实现了多厂商管理,可以统一管理不同厂商的信息,支持灵活的厂商切换和配置。
2. 厂商数据隔离和脱敏:框架支持厂商数据隔离和脱敏,确保不同厂商的测试数据相互独立,敏感信息得到有效保护,保障测试数据的安全性。
3. 多环境支持:支持多环境切换,确保测试可以在不同环境中进行,满足不同阶段的测试需求。
改进点:脚本化使得测试可以批量执行,多厂商管理和多环境支持大大提升了测试的灵活性和覆盖范围,但仍然需要人为介入RTC SDK的操作
第三阶段:引入自研SDK自动化测试工具
为了提升RTC SDK的自动化能力,QA 团队在早些年自研首个RTC SDK自动化测试工具,本次引入该工具并增强字幕渲染的功能。这使得测试人员可以通过编码的方式,自动的控制SDK加入频道的时机,以及SDK的API调用,且直观地看到ASR识别结果和LLM返回的文本内容,大大提升了问题定位的效率。
关键突破:通过引入SDK自动化工具,且适配实时字幕渲染,测试人员可以高效率的完成RTC SDK加入频道的操作以及观察到完整的对话流程,为端到端测试奠定了基础。
第四阶段:自定义语料支持与实时TTS生成(Audio Device Service)
这是测试框架演进中的关键阶段,通过引入音频设备服务和实时TTS生成技术,彻底解决了”需要人来说话”、”多语种不会说”等核心痛点。
音频设备服务:实现人声输入自动化
SDK通过麦克风采集音频数据再送给后续处理模块,那么如果固定一些音频语料灌入外置声卡,然后让SDK通过采集指定声卡的音频数据就可以解决”人声说话”的问题,通过引入音频设备服务,测试框架开始支持自定义灌入语料,脚本控制语料灌入时机,这使得测试可以覆盖更多场景,包括不同方言(上海方言、湖北方言)、不同语言(日语、英语、普通话、粤语)的测试。
实时TTS生成:动态语料生成
随着TTS技术的成熟,测试框架进一步支持实时TTS生成语料。这意味着测试不再局限于预录制的音频,可以根据测试需求通过支持多语种的实时TTS服务动态生成各种语音内容。
核心突破:
1. 彻底解决”需要人来说话”的痛点:
- 通过音频设备服务,可以直接灌入预录制的音频语料,完全摆脱了对人工发声的依赖
- 测试可以7×24小时自动运行,无需人员值守
- 测试一致性大幅提升,使用固定语料或动态生成的语料确保了每次测试的输入完全一致
2. 突破”多语种不会说”的限制:
- 通过实时TTS生成,可以动态生成任意语言的语音内容,覆盖范围远超人工录制
- 不再受限于测试人员的语言能力,可以覆盖各种国际化场景
3. 端到端测试能力的完善:
- 可以模拟不同用户、不同场景的真实输入,构建完整的端到端测试能力
- 支持声纹多人场景的验证
- 可以生成各种边界场景的语料,包括语速变化、情感变化、语调变化等
- 每一轮对话都可以根据前一轮的响应动态生成新的输入,实现真正的多轮对话自动化测试
对话流测试的完善:通过自定义语料和实时TTS生成的结合,测试框架可以动态构造对话场景,支持多轮对话的自动化测试,为端到端测试奠定了坚实基础。
第五阶段:LLM智能判断
最新的演进阶段引入了大模型来判断回答结果。既可以通过大模型分析用户提问和Assistant回答的是否符合语义场景,同时引入多模态大模型分析系统返回的音频内容是否符合。
核心能力:
- 文本内容智能判断:通过大语言模型分析用户提问和Assistant回答的匹配度,自动验证回答的相关性、准确性和完整性。支持多轮次对话语义分析。
- 音频多模态分析:引入多模态大模型,通过分析系统返回的音频内容(PCM音频),理解音频中实际表达的内容,并与文本回答进行对比验证,确保TTS合成的语音准确传达了文本回答的内容。这确保了在语音交互场景中,系统不仅文本回答正确,语音输出也能准确传达文本内容。
端到端闭环:LLM智能判断实现了从用户输入到系统响应验证的完整闭环,包括文本和语音的多模态验证,使得端到端测试可以真正实现无人值守的自动化执行。
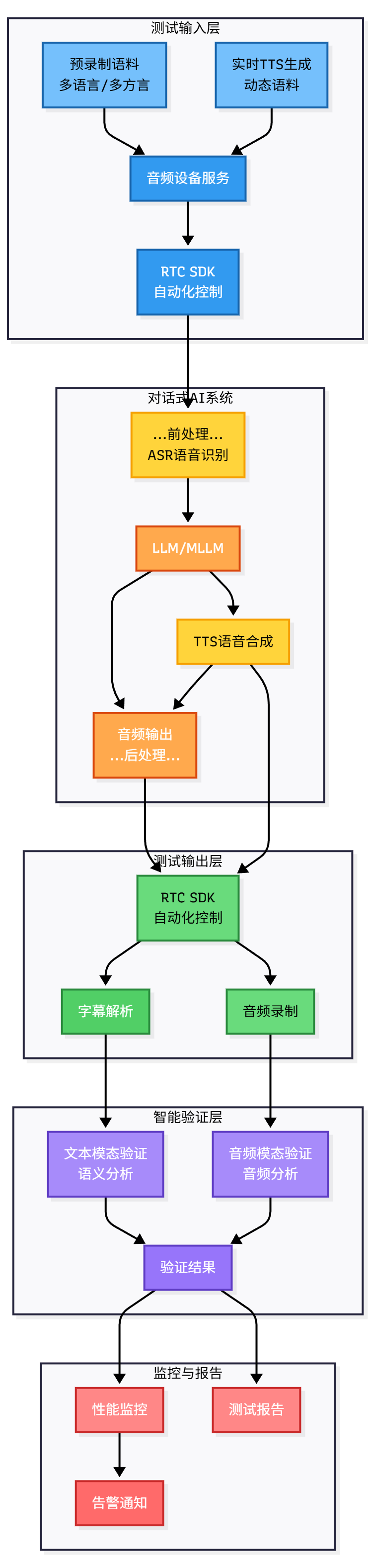
端到端测试流程图
二、其他能力的支持
除了核心的端到端对话流测试能力外,测试框架还提供了其他的辅助能力,全面保障系统的稳定性和可靠性。
2.1 异常参数生成
测试框架内置了异常参数生成器,可以自动对所有参数生成非法值,验证系统在异常情况下的稳定性。
异常类型:
- 参数类型错误(字符串传入数字字段)
- 参数值越界(超出允许范围的值)
- 参数缺失(必填参数为空)
- 参数格式错误(不符合规范的格式)
通过自动生成各种异常参数,可以全面验证系统的容错能力和边界处理能力。
2.2 崩溃自恢复测试
框架支持崩溃自恢复测试,可以验证系统在主动和被动拉起场景下的稳定性。这确保了即使在异常情况下,系统也能够自动恢复并继续提供服务,保障了系统的高可用性。
2.3 压力测试
测试框架支持大规模压力测试,可以:
- 并发执行多个Agent,验证系统在高并发场景下的表现
- 测试系统资源消耗和性能瓶颈
- 验证系统在极限负载下的稳定性
- 发现系统容量限制和性能衰减点
通过压力测试,可以提前发现系统在高负载下的潜在问题,确保系统能够应对实际生产环境的流量压力。
2.4 性能监控及时通知
框架内置了性能监控和告警机制:
- 自动记录请求响应耗时,支持存储和分析
- 自动生成HTML报表,直观展示性能数据
- 超过阈值(如3秒)自动触发机器人通知告警
通过实时监控和及时通知,测试团队可以快速发现性能问题,保障系统的响应速度和用户体验。
2.5 Custom LLM
框架包含了遵循OpenAI协议的custom llm,可以模拟生产环境中出现的各种异常场景,验证系统在异常情况下的处理能力。
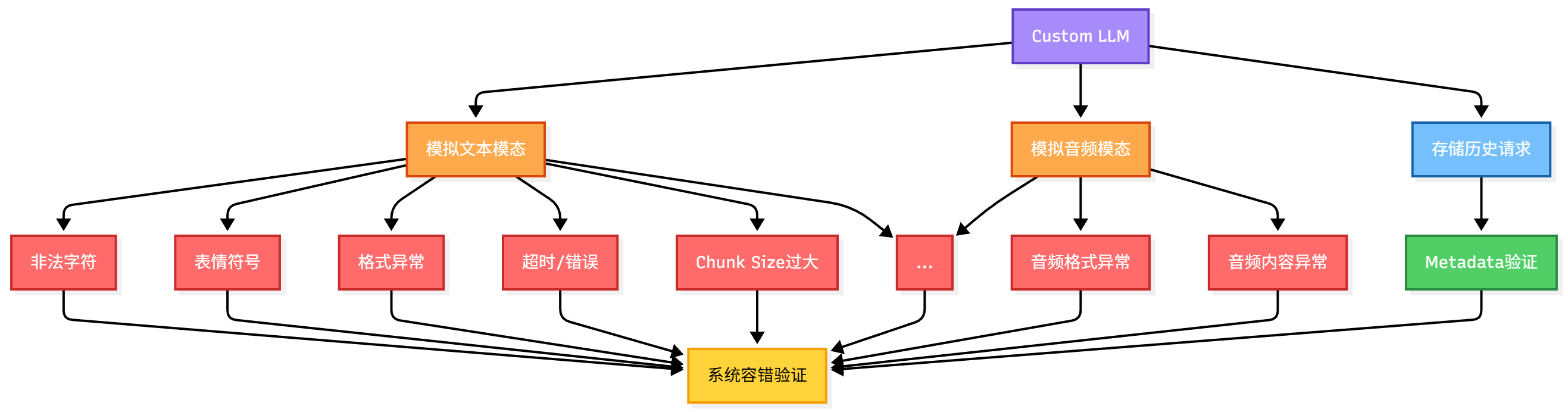
核心能力:
1. 异常场景模拟:通过custom_llm可以构造各种异常返回,模拟真实生产环境中可能遇到的问题:
- 大模型返回非法字符,验证系统对异常字符的处理能力
- 大模型返回表情符(emoji),验证系统对特殊字符的兼容性
- 大模型返回格式异常的数据,验证系统的容错机制
- 模拟大模型返回超时、错误等异常情况
- 模拟大模型返回的chunk size过大导致的系统异常问题
2.多模态支持:
- 文本模态:支持模拟文本返回的场景
- 音频模态:支持模拟音频返回的场景
3. 历史请求存储与查询:
- 存储历史请求:Custom LLM会自动存储所有接收到的请求,包括请求体、请求头、metadata等完整信息,便于后续分析和追溯
- 查询请求体:提供查询接口,可以根据时间范围、请求ID等条件查询历史请求,支持查看完整的请求体内容
- Metadata验证:验证发送给大模型的请求中携带的metadata是否符合预期,包括验证metadata的字段、值、格式等,确保系统正确传递了必要的上下文信息
通过custom_llm开发,测试团队可以在受控环境中验证系统对各种异常场景的处理能力,提前发现和修复潜在问题,保障系统在生产环境中的稳定性和可靠性。同时,通过历史请求存储和metadata验证功能,可以确保系统在调用大模型时正确传递了所有必要的上下文信息。
测试框架整体能力图
结语
从最初的人工测试,到如今的端到端自动化测试,测试框架经历五个阶段的持续迭代,我们逐步解决了传统测试方式的核心痛点:主播加频道的手工操作通过自研工具自动化、需要人来说话的局限性通过音频设备服务和实时TTS生成技术解决;多语种不会说的问题通过自定义语料和动态TTS生成来扩大语种覆盖;输出内容如何自动判断符合用户提问输入通过LLM智能判断和多模态分析实现了自动化验证。
如今的测试框架从用户输入(支持多语言、多方言、动态语料生成)到系统响应(文本和音频的多模态验证),实现了端对端的对话式自动化测试。同时,框架还提供了异常参数生成、崩溃自恢复测试、压力测试、性能监控、Custom LLM等辅助能力,全面保障系统的稳定性、可靠性和性能表现。
未来,随着AI技术的不断发展,端到端对话流测试将更加智能化,可能会引入自动生成测试用例、智能分析测试结果,进一步提升测试的效率和准确性。
版权声明:本文由作者授权上海声网科技有限公司发表。未经许可,不得转载。
本文内容为作者个人观点,仅用于技术交流与分享,不代表上海声网科技有限公司的官方立场或承诺。
如涉嫌侵权,请联系我们:blog@shengwang.cn

