 首页
首页在实时音视频场景中,开发者常常会遇到这样一个问题:开启自动噪声抑制(ANS)后,声音确实更干净了,但为什么“延迟”似乎变高了?那么问题来了:自动噪声抑制算法对实时性到底有没有要求?它会不会成为实时音视频系统中的延迟瓶颈?
答案是:有要求,而且非常高。
但它的“实时性要求”并不是简单的“越低延迟越好”,而是一个工程上的平衡问题——在降噪效果、计算复杂度、模型结构、端侧性能、整体链路延迟之间做取舍。
一. 什么是自动噪声抑制(ANS)?
自动噪声抑制(Automatic Noise Suppression,ANS)是一种音频前处理算法,目标是:在尽可能保留人声细节的前提下,抑制或消除背景噪声。
在真实场景中,常见噪声包括:键盘敲击声、空调与风扇声、环境人声、交通噪声、室外风噪等。
在实时音视频系统中,ANS通常并不是单独存在的,而是和以下模块一起构成完整的音频前处理体系:
- AEC(Acoustic Echo Cancellation,回声消除)
- AGC(Automatic Gain Control,自动增益控制)
- VAD(Voice Activity Detection,语音活动检测)
典型的处理链路是:采集 → AEC → ANS → AGC → 编码 → 网络传输
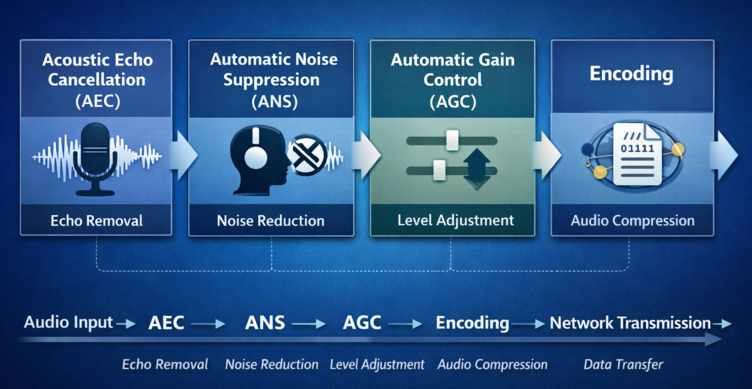
注意这里的一个关键点:自动噪声抑制(ANS)发生在编码之前。
这意味着,它的处理耗时会直接叠加进整条实时音视频链路的端到端延迟。也正因为如此,ANS对实时性的要求极其敏感。
二. 什么叫“实时性”?它远比一个数字复杂得多
很多人在讨论实时性的时候,习惯用一个简单的指标来衡量,比如 “总延迟是多少毫秒”。但在真正的实时音视频工程中,这样的理解太片面了。从工程角度看,实时性至少包含三个层面
1. 算法内部延迟
先从最基础的说起。自动噪声抑制(ANS)这样的算法本身就会引入一定的处理时间。这包括:
- 每一帧需要处理的音频数据长度(例如 10 ms、20 ms)
- 模型推理所需的计算时间
- 以及必要的历史帧缓存以支持算法运算
这些时间都会变成延迟的一部分。如果你的模型每帧要等 20 ms 的数据才能开始处理,那么这 20 ms 就已经是不可避免的延迟了。即便推理只耗时几毫秒,这些帧结构本身的等待也是延迟的重要组成部分。
从音频处理中典型的分帧和频域分析机制来看,这种结构性的延迟是算法“设计上”的一部分,而不是简单通过优化就能消除的。
2. 缓冲与帧结构延迟
在实时音频处理中,数据并不是一条条“流”直接送进嘴里就能处理的。通常需要先把麦克风采集的连续信号 分帧、加窗、变换 成更适合处理的形式(如频谱)。这意味着:
- 为了进行一帧处理,需要先“积累”一段时间的数据
- 这段时间往往至少是 10 ms 或更高
- 只有等够了一帧数据,算法才可能开始处理
所以,从结构上讲,即便算法本身非常快,它也必须先等待帧完整到达,这本身就形成了延迟。这一点在实时音频处理系统中是非常常见的现象,它并不是某个具体算法的问题,而是由音频处理的时间窗机制决定的。
3. 端到端延迟
最后,也是最关乎用户体验的一层是真正意义上的 端到端延迟。它并不只包括算法内部的延迟和帧结构延迟,还包括:
- 设备采集和驱动层缓冲
- 音频前处理(包括 ANS、AEC 等)
- 编码器和解码器的处理时间
- 网络传输延迟(抖动、队列、拥塞等)
- 最终播放缓冲
每一项都会叠加形成最终的用户感知延迟。
所以,即便 ANS 只增加了 10–15 ms,会不会有影响?
答案是:会。
这不是因为 10 ms 看起来很大,而是因为整个系统的延迟结构本身就非常紧张。端到端的预算本来就有限,一旦某一个环节消耗了过多时间,整体体验就会被拉高。因此,理解“实时性”不能只盯着一个数字,而需要从三层结构去看:
- 算法内部产生的延迟
- 音频数据组织和缓冲机制引入的延迟
- 整条链路和用户感知上的延迟累计
只有把这些维度都考虑进去,我们才能理解为什么在实时音视频中 ANS 对延迟如此敏感。
三. 自动噪声抑制(ANS)为什么会影响实时性?
ANS 之所以会对实时性构成明显影响,是由音频处理的基本原理和实时系统的约束共同决定的。影响主要来自以下三个根本因素:
1. 频域处理依赖时间窗口
传统的噪声抑制算法(例如基于谱减法或 Wiener 滤波的经典方法)都是在频域完成噪声分析与抑制的,而频域处理本质上依赖一个时间窗口:
要进行频谱分析,必须先积累一定长度的语音数据,然后再做短时傅里叶变换(STFT)等运算,将时间信号转换为频率域表示。时间窗口越长,频率分辨率越高,噪声估计越精确,降噪效果也更好;但这同时意味着必须等够一段时间才能开始处理。这种时间窗引入的延迟是结构性、不可绕过的。
这种设计在离线或非实时处理里并不成问题,但在实时场景中,它直接变成了延迟来源。
2. 深度学习模型需要推理时间
近年来实时噪声抑制越来越多采用深度学习模型,例如单向递归网络(RNN)、因果卷积网络(Causal CNN)流式 Transformer 等。这些模型在语音增强质量上表现优异,但它们的推理时间并不是免费的,模型规模越大、参数越多、层数越深,推理耗时越高。即便单帧推理只需几毫秒,对于延迟预算紧张的实时音视频系统来说,这几毫秒仍然是显著的消耗。尤其在移动端或算力受限的设备上,模型推理时间成为延迟的直接贡献者,如果没有量化、剪枝和加速优化,实际延迟可能被放大几十毫秒甚至更多。
优秀的神经网络降噪效果背后往往伴随着更高的计算负担,而这正是影响实时性的核心因素之一。
3. 因果性限制:实时不能“看未来”
在离线场景中,效果最好的噪声抑制算法往往可以访问未来帧信息,例如双向 RNN 或非因果卷积网络等,它们同时利用过去和未来上下文来提高效果。
但在实时音视频处理里,不存在未来帧。算法只能依赖当前和历史信息做推理,这就要求模型必须在信息不完整的情况下做决策。
- 当前帧只能基于已到达的历史内容进行判断
- 不能使用未来未到达的数据
这种信息约束是实时系统的本质要求,也直接导致实时模型的性能上限通常低于非实时模型。在实际实现时,我们甚至常常要牺牲一部分降噪质量,以满足这种严格的因果性和低延迟要求。
四. 不同场景对ANS实时性的要求差异
实时性并不是一个固定标准,它和具体应用场景密切相关。不同业务对延迟容忍度的差异,直接决定了ANS设计的侧重点。
1. 在线会议
多人交互、频繁打断是在线会议的典型特征。在这种场景中,如果整体延迟超过某一临界值(比如约 200 ms),谈话节奏会明显紊乱,抢话不顺畅、对话体验下降。为了避免这种感知上的卡顿,ANS设计必须控制在非常低的延迟内,这对算法结构和处理速度提出了严格要求。
2. 游戏语音
在实时竞技类游戏中,语音延迟的容忍度更低。因为玩家需要将语音指令与操作同步,如果延迟超过 ~80 ms,就会明显影响行为判断和配合效率。这使得游戏语音往往更倾向于优先保证低延迟,而不是极限抑噪。
3. 互动直播
直播场景呈现出不均衡的实时性要求:
- 主播端:需要极低的延迟以保证互动节奏
- 观众端:稍微高一点的延迟也能接受,以换取更强的降噪效果
这种差异化需求使得工程实现常常对主播端和观众端采取不同的ANS设计方案。
4. AI 语音 Agent / 智能客服
这个场景的挑战更复杂,因为延迟不仅影响用户体验,还会影响语音识别、打断检测和 TTS 交互逻辑。
高延迟可能导致:
- ASR 识别反应变慢
- 打断检测失效
- 对话节奏生硬
因此,在这种交互式体验中,对实时性的要求往往比纯通信场景更苛刻。
结语
从算法内部处理到帧级缓冲,从端到端传输到用户感知,每一层都可能消耗时间。ANS 会影响实时性,主要在于:
- ANS 本质上是音频前置处理的一部分,它发生在编码之前,因此其任何处理时间都会直接叠加到端到端延迟中。
- 实时性不是一个单一数字,而是由算法内部延迟、帧级缓冲延迟以及整个链路的叠加延迟构成的综合指标。
- ANS 影响实时性的三大根本因素是:频域处理对时间窗的依赖、深度学习模型的推理计算成本,以及实时系统中不可使用未来帧的因果性限制。
- 不同业务场景对延迟的容忍度不同,这将直接影响 ANS 的设计策略和优化方向。
ANS 是整个音频处理 3A(AEC、ANS、AGC)体系中的一环,其延迟贡献虽然看似毫秒级,但却是端到端延迟预算中不可忽视的一笔。合理设计和工程优化后的 ANS,并不会成为系统瓶颈,反而能在保证语音清晰度的前提下,有效提升终端用户的实时交互体验。


